
Splunk Enterprise
Last updated on Jan 24, 2024

Most users access Splunk Enterprise via a web browser and use Splunk Web to manage and create knowledge objects, run searches, create pivots and reports, and so on. You can also manage your Splunk Enterprise deployment using the command-line interface.
Utilizing apps, you can customize the Splunk Enterprise eco system to address the different needs of your organization. An app is a catalogue of Splunk platform setups, information objects, viewpoints, and workflows. Multiple apps can be run concurrently by a single Splunk Enterprise installation. Moreover you can browse different apps on the Splunkbase apps in order to create your own on the Splunk developer site.
Want to get Splunk Training From Experts? Enroll Now to get free demo on Splunk Online Course.
Features of splunk Enterprise:
The following are the important features of the splunk enterprise. They are:
- Indexing:
Splunk Enterprise analyzes and stores data that represents your company and its infrastructure. Data can be collected from a variety of devices and applications, including websites, servers, databases, operating systems, and others. After collecting the data, the index segments, stores, compresses, and maintains the supporting metadata to speed up searching.
- Search:
In Splunk Enterprise, the primary way for users to explore their data is through search. A search can be saved as a report and used to power dashboard panels. Searches extract information from your data, such as:
- Retrieving events from a database
- Metrics Calculation
- Looking for specific conditions within a time window that is rolling
- Finding patterns in your data
- Future Trend Prediction
- Alerts:
Alerts inform you once search outcomes both for chronological and true search queries meet the criteria you specify. Alerts can be configured to perform actions such as sending alert information to specified email addresses, posting alert information to an RSS feed, and operating a custom script, such as one that logs an alert event to syslog.
- Dashboard:
Dashboards include panels with modules such as search boxes, fields, charts, and so on. Typically, dashboard panels are linked to saved searches or pivots. They show the results of finished searches as well as data from background real-time searches.
We have the perfect professional Splunk Tutorial for you. Enroll now!

Splunk Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
- Pivot:
The table, chart, or data visualization that you create with the Pivot Editor is referred to as a pivot. The Pivot Editor allows users to map data model object attributes to a table, chart, or data visualization without having to write the searches in the Search Processing Language (SPL) to generate them. Pivots can be saved as reports and incorporated into dashboards.
- Reports:
Splunk Enterprise lets you save searches and pivots as reports, which you can then add to dashboards as dashboard panels. Run reports on an as-needed basis, schedule them to run at regular intervals, or configure a scheduled report to generate alerts when the result meets certain criteria.
- Data models:
Data models represent highly specialised technical knowledge around one or more collections of indexed data. They allow Pivot Editor designers to develop reports and dashboards without having to design the searches that produce them.
Top 40+ frequently asked Splunk interview questions & answers for freshers & experienced professionals
Splunk Enterprise users:
Splunk Enterprise caters to a variety of users. The following are the five main personas who use Splunk Enterprise:
- Administrator
- Knowledge Manager
- Search user
- Pivot user
- Developer
Administrator Activities:
- Splunk Enterprise deployment administrators can perform configuration, optimization in order to secure the infrastructure
- Creates user accounts and permissions.
- Can easily load the data into Splunk Enterprise.
Knowledge manager activities:
- Oversees the creation, normalization, and use of knowledge objects across teams, departments, and deployments.
- Obtains the data and enters it into Splunk Enterprise, or collaborates with the administrator to do so.
- Creates and distributes data models
Search user activities:
- Search is used to investigate server issues, understand configurations, monitor user activity, and troubleshoot escalated issues.
- Creates reports and dashboards to monitor their IT infrastructure's health, performance, activity, and capacity.
- Patterns and trends that are indicators of routine problems are identified.
Pivot user activities:
- Pivot is used to generate databases based on data models created by the Knowledge Manager.
- Creates reports and dashboards to help them keep track of their businesses.
- Identifies trends in their company's health and performance.
Acquire Splunk SIEM Security certification by enrolling in the HKR Splunk SIEM Security Training program in Hyderabad!

Subscribe to our YouTube channel to get new updates..!
Developer activities:
- Splunk Enterprise data and application functionality are integrated.
- Creates Splunk apps and add-ons that include custom dashboards and data visualizations.
Splunk Enterprise Deployments:
Splunk Enterprise indexes information from the IT infrastructure's servers, software, datasets, network equipment, and virtualization software. Splunk Enterprise could indeed gather information from everywhere, whether this is local, remote, or in the cloud, as soon as the device which creates the information is connected to your network.
As it sense, Splunk Enterprise needs to perform three primary functions:
- It reads data from files, networks, and other sources.
- It parses and indexes the information.
- It performs searches on the data that has been indexed.
Types of deployment:
You could even deploy Splunk Enterprise as a single example or create deployments which support different instances, varying from a few to hundreds or thousands of cases, depending on the requirements.
Single instance deployments:
In small deployments, each Splunk Enterprise instance controls all issues related to data storage, from input to indexing to quest. A single-instance development can be helpful for development and analysis, and it may be sufficient for department-sized ecosystems.
Distributed deployments:
To better functioning contexts at which data originally comes on different systems, large amounts of data must be processed, or multiple users must search the data, users can measure the implementation by disseminating Splunk Enterprise instances all over multiple machines. This is referred to as a "distributed deployment."
Each Splunk Enterprise instance together in pretty standard distributed deployment performs a particular tasks and inhabits on a few of three handling tiers correlating to the primary data processing:
- data input tier
- Indexers tier
- Search management tier
Splunk Enterprise components:
The splunk enterprise architecture contains different components that perform different functionalities.Lets See them in detailed way.
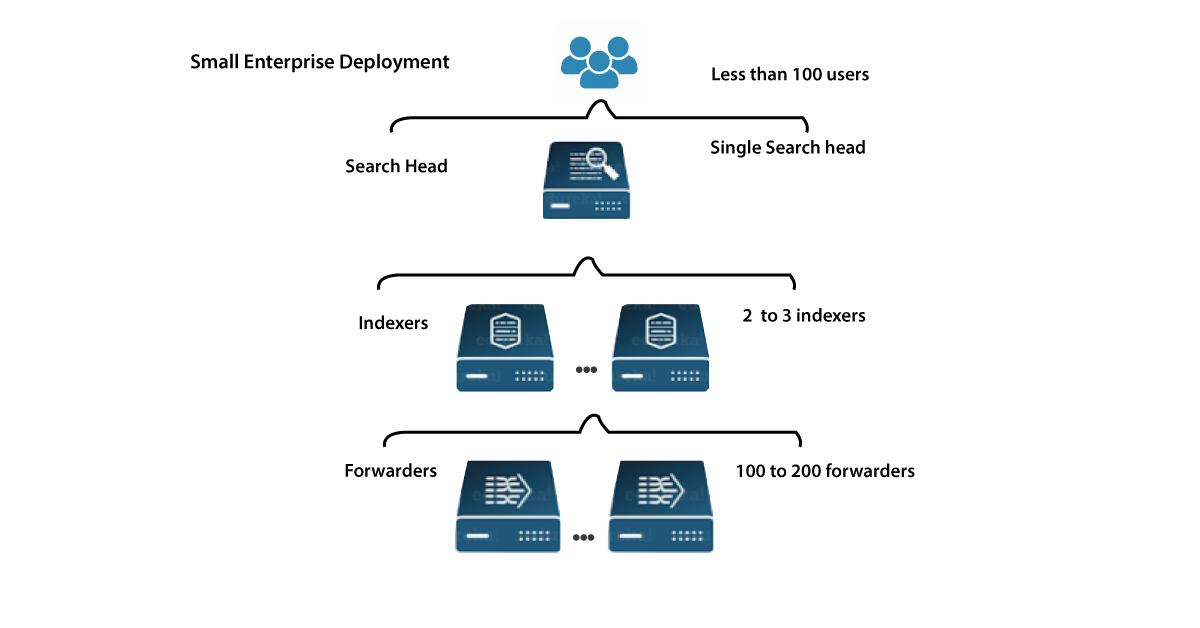
Forward data input tier:
A forwarder uses up data and then forwards it on, typically to an indexer. Forwarders typically require few resources, allowing them to live lightly on the machine that generates the data.
Indexing tier:
An indexer is a program that indexes incoming data from a group of forwarders. The indexer converts data into events and stores them in an index. In addition, the indexer searches the indexed data in response to search requests from the search head.
You could even deploy multiple indexers in indexer clusters to ensure high data availability and protect against data loss, or simply to simplify the management of multiple indexers.
Search head tier:
A search head communicates with users, routes search requests to a group of indexers, and returns the results to the user.
Multiple search heads can be deployed in search head clusters to ensure high availability and simplify horizontal scaling.
You could even add components to every tier as needed to meet increased competition on that tier. If you've a huge number of devices, for instance, you can add more search heads to better represent them.
Join our Nutanix Enterprise Cloud Platform Administration Training today and enhance your skills to new heights!
Conclusion:
In the above blog post we discussed the splunk enterprise, its features, deployments types and components of the splunk architecture. Had any queries please drop them in the comments section to get answered.
Related Articles:
About Author
Upcoming Splunk Training Online classes
| Batch starts on 2nd Aug 2026 |
|
||
| Batch starts on 6th Aug 2026 |
|
||
| Batch starts on 10th Aug 2026 |
|