
MapReduce in Big Data
Last updated on Nov 21, 2023

What do you know about Big Data?
Big data is open source software where java frames work is used to store, transfer, and calculate the data. This type of big data software tool offers huge storage management for any kind of data. Big data helps in processing enormous data power and offers a mechanism to handle limitless tasks or operations. The major purpose to use this big data used to explain a large volume of complex data. Big data can be differentiated into three types such as structured data format, semi-structured data format, and unstructured data format. One more point to remember, it’s impossible to process and access big data using traditional methods due to big data growing exponentially. As we know that traditional methods consist of the relational database system, sometimes it uses different structured data formats, which may cause failure in the data processing method.
Why do we need big data?
Here are the few advanced features of big data;
1. Big data helps in managing the traffics on streets and also offers streaming processing.
2. Supports content management and archiving e-mails method.
3. This big data helps to process rat brain signals using computing clusters.
4. provides fraud detections and prevention.
5. Offers manage the contents, posts, images, and videos on many social media platforms.
6. Analyze the customer data in real-time to improve business performance.
7. Fortune 500 company called Facebook daily ingests more than 500 terabytes of data in an unstructured format.
8. The main purpose to use big data is to get full insights into their business data and also help them to improve their sales and marketing strategies.
Introduction to MapReduce application:
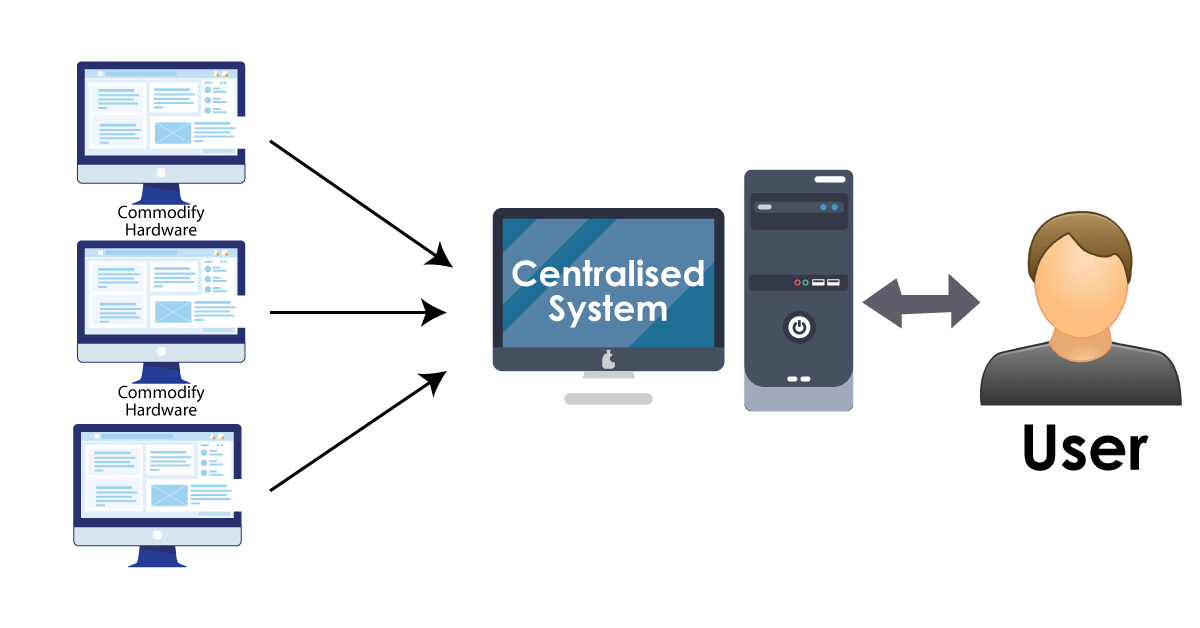
We know that traditional enterprise systems consist of a centralized server to process data and also help to store them. Normally traditional models are not suitable to process the large volume of data and cannot access them using standard database servers. In general, a centralized server usually consists of the bottleneck to process multiple data files.
The following diagram will illustrate the bottleneck process:

The below diagram will explain how this MapReduce integrate the tasks;
How this MapReduce works?
In general, this MapReduce algorithm divided into two components as “Map” and “Reduce”.
1. The Map task takes out data sets and converts them into another data set, where individual data set will be divided into key-value pairs (or you can call them Tuples).
2. The Reduce task will take the output data sets from the Map task as an input value and combines them into tuples of key-value pairs.
There are seven stages while working with the Map Reduce application model:
1. Input phase:
This is a type of record reader that helps to translate each data record into an input file and send them as a parsed data to mapping in the form of key-value pairs or tuples.
2. Map:
Map is a kind of user-defined function; this consists of series of key-value pairs and processes each key-value pair to generate more tuples data sets.
3. Intermediate keys:
here the key-value pairs are generated by the mapper method popularly known as intermediate keys.
4. Combiner:
A combiner is a kind of local reducer that helps to group similar data sets from the different map phases into identified sets. This combiner normally takes the intermediate keys from the mapper type as input and applies them into user-defined codes to aggregate into the small scope of one mapper. This is an optional one, not a MapReduce algorithm.
5. Shuffle and sort:
This is a reducer task that should starts with the shuffle and sort step. It helps to download the grouped key-value pairs into the local machine. The individual key-value data pair is sorted by intermediate key into larger data set list. The final data list groups can be iterated easily in the reducer task.
6. Reducer:
The reducer takes the key-value paired group as an input value and runs them using Reducer functions. With the help of a reducer, the data can be aggregated, integrated, filtered, and combined into one data set. Once you are done with the execution process, this gives zero or more key-value pairs to get the final step.
7. Output Phase:
In this output phase, Map-reduce consists of output formatter that translates the final data key-value pair from the various reducer function and writes into a single file with the help of a record writer.

Big Data Hadoop Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Map Reduce algorithms:
Usually, Map reduce algorithm consists of two main tasks such as Map and Reduce;
1. Map task is done with the help of the Mapper class.
2. Reduce task is done with the help of the Reducer class.
For example; the mapper class takes the input data value, tokenizes it, and sorts it. The output of the mapper class used as a Reducer class input, and also search for matching pairs and reduces the time while execution.
The below diagram will explain how this Map reducer task works;
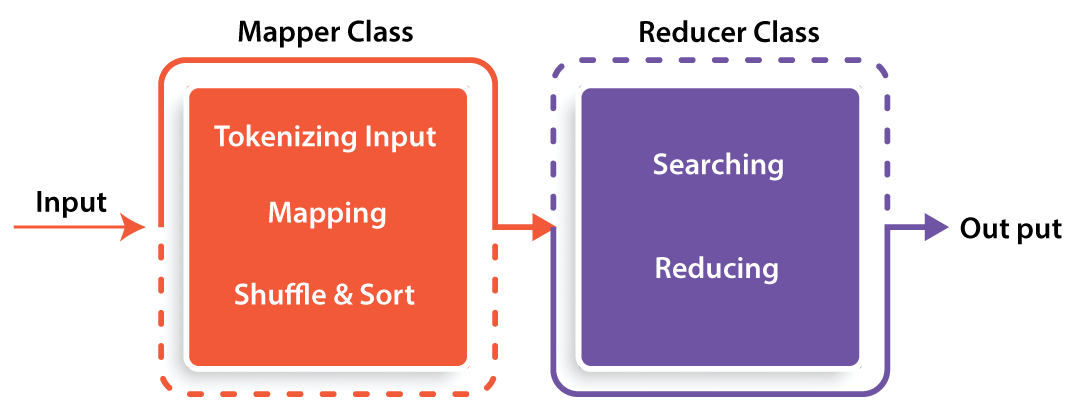
The following are the key algorithms used in the Map Reducer task;
1. Sorting
2. Searching
3. Indexing
4. TF – IDF algorithm
Let me explain them one by one;
1. Sorting:
Sorting is one of the basic types of Map Reduce algorithms mainly used to process and analyze the data. Map Reduce implements the sorting algorithm to automatically sort out the output data key-value pairs from the mapper key sets.
Few important points about sorting algorithm:
1. Sorting methods are normally implemented in the mapper class types themselves.
2. While in the shuffle and sort phase, after the tokenizing process, you need to add the key values in the mapper class. In this step, the Context class helps to collect the matching valued keys as a data collection.
3. To collect similar types of key-value pairs, with the help of RawComparator class the Mapper class sorts the key-value pairs.
2. Searching:
Searching is an important type of algorithms in the MapReduce algorithm. This Searching phase helps to combine both the combiner phase and reducer phase. The Map Phase helps to process each input file and offers the key-value pairs. Whereas the Reducer phase helps to check all the key-value pairs and eliminates the duplicate entries.
3. Indexing:
In general Indexing, the type is used to point to the particular data sets and also their address. This also performs batch indexing on the different various input files for a specific mapper method. The indexing technique that is generally used in Map Reduce is known as “Inverted Index”. Popular search engines like Google and Bing make use of the Indexing technique.
Subscribe to our YouTube channel to get new updates..!
4. TF –IDF:
This TF –IDF is a kind of text processing algorithm that is short known as Term Frequency – Inverse Document Frequency. This is also one of the commonly used web analysis algorithms. Here the “frequency” term refers to the number of times the document appears.
The below mathematical formula explains the TF-IDF algorithm type;
TF = (Number of items term the appears in a document) / (total number of terms in the document)
IDF = log_e (Total number of documents / Number of documents with the term in it).
Benefits of using Map Reduce algorithms:
The following are the key advantages of using Map Reduce:
1. Offers Distributed data and computations.
2. The tasks are independent, and entire nodes can fail and restart.
3. Linear scaling is considered to be an idle case. This is used to design hardware commodities.
4. Map Reduce is a simple programming model and with the help of this end, programmers can only write the map reduce task.
Conclusion:
In this Map Reduce big data blog, we have explained the types of algorithms being used to perform data process and analysis tasks. Most of the popular search engine companies like Google, Yahoo, and Bing prefer this Map reduce algorithm due to its benefits. I think due to this reason, big data experts are in huge demand and paid huge salary packages. Map reduce is one of the popular algorithms used to process a large volume of data. As per the latest report, almost 65% of top companies use map reduce algorithms to reduce the enormous amount of data.
About Author
Upcoming Big Data Hadoop Training Online classes
| Batch starts on 2nd Aug 2026 |
|
||
| Batch starts on 6th Aug 2026 |
|
||
| Batch starts on 10th Aug 2026 |
|