
Splunk Architecture
Last updated on Jul 20, 2024

What is Splunk?
Splunk seems to be a fantastic, expandable, and effective technology for indexing and searching log files contained inside a framework. It analyzes machine-generated information in order supply operations and maintenance intelligence. The major benefit from using Splunk is that this does not necessitate any database for storing its information, instead relying on its indexes.
With Splunk software, it is simple to search for specific data within a cluster of complex data. It is difficult to determine which configuration is currently active in log files. To clarify, the Splunk application employs a tool that assists the user in locating issues with a configuration file and viewing the current configurations that are in use.
Get ahead in your career by learning Splunk course through hkrtrainings Splunk Training !
Why Splunk?
Splunk is considered mainly because of the following functionalities.
- User's performance was increased by providing immediate access to specific devices and content. It is a fantastic profitability component for end customers.
- Manages Enterprise Splunk deployments in a streamlined and scalable manner.
- Facilitates in the rapid development of Splunk applications using authorised web languages as well as structures.
- It allows business users to conduct faster and more straightforward analyses and visualization techniques.
Now let's start with actual concepts here.
Before I get into how distinct Splunk components work, I'd like to go over the different phases of the data pipeline which each element tends to fall under.
Stages in the Data Pipeline:
Basically there are 3 different stages in the data pipeline. They are:
- Data input stage
- Data storage stage
- Data searching stage

Data Input Stage:
Splunk software uses up the raw stream of data from its own origin, divides it into 64K blocks, and analyzes each block with metadata keys during this stage. The metadata keys also include data's hostname, source, and source type.The keys can also contain values being used internal and external, like the data stream's character encoding, and value systems that control data analysis during the indexing stage, like the index into which the events should be stored.
Data storage stage:
Data storage contains two parts: indexing and parsing
- Splunk software explores, evaluates, and converts data during the Parsing phase to extract only the relevant data. It is also referred to as process automation. Splunk software splits the data stream into single events during this phase. The parsing phase is divided into several sub-phases:
- Dividing the data stream into individual lines
- Identifying, parsing, and establishing timestamps
- Individual events are annotated with metadata copied from the source-wide keys.
- Using regex transform rules to transform event data and metadata
- During the Indexing phase, Splunk software needs to write parsed events to a disk index. It saves both of the condensed raw data and the index file. The advantage of indexing is that the data is easily accessible during searching.
Data Searching stage:
This stage governs how well the indexed data is accessed, viewed, and used by the user. Splunk application stores consumer knowledge objects, such as documents, event types, dashboards, alerts, and field extractions, as part of its search function. The search function is also in charge of managing the search process.

Splunk Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Splunk Components:
If you look at the image below, you would see the various data pipeline stages that various Splunk components fall under.
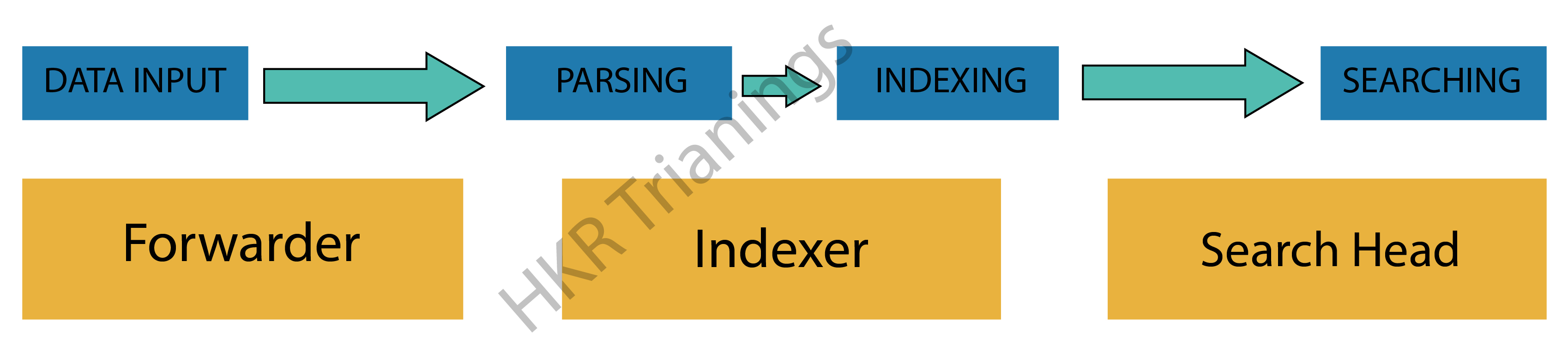
Splunk is made up of three major components:
- Splunk Forwarder is a data forwarding tool.
- Splunk Indexer, which is used for data parsing and indexing.
- Search Head is a graphical user interface (GUI) for searching, analyzing, and reporting.
Splunk Forwarder:
Splunk Forwarder seems to be the component that you must use to collect logs. If you want to collect logs from a remote machine, you can do so by using Splunk's remote forwarders, which are separate from the main Splunk instance.
In reality, users could indeed install multiple forwarders on different machines to forward log data to a Splunk Indexer for processing and storage. What if you want to perform real-time data analysis? Splunk forwarders can also be used for this purpose.The forwarders can indeed be configured to send data to Splunk indexers in real time. You can install them in multiple systems and collect data in real time from multiple machines at the same time.
Now let's go through the different types of splunk forwarders.
- Universal forwarder: If you really want to send the raw data collected at the source, you can use a universal forwarder. It is a straightforward component that performs minimal processing on incoming data streams before passing them on to an indexer.
With almost every tool on the market, data transfer is a major issue. Because the data is processed minimally before being forwarded, a large amount of unnecessary data is also forwarded to the indexer, resulting in performance overheads.Why bother transmitting all the information to the Indexers and then filtering out only the relevant information? Isn't it best to send just the necessary data to the Indexer, saving bandwidth, time, and money? It can be fixed by employing heavy forwarders, as explained below.
- Heavy forwarder:
You could use a Heavy forwarder to solve half of your problems because one level of data processing occurs at the source before data is forwarded to the indexer.The Heavy Forwarder generally parses and indexes data at the source and intelligently routes it to the Indexer, saving bandwidth and storage space. As a result, when a heavy forwarder parses the data, the indexer only has to deal with the indexing segment.
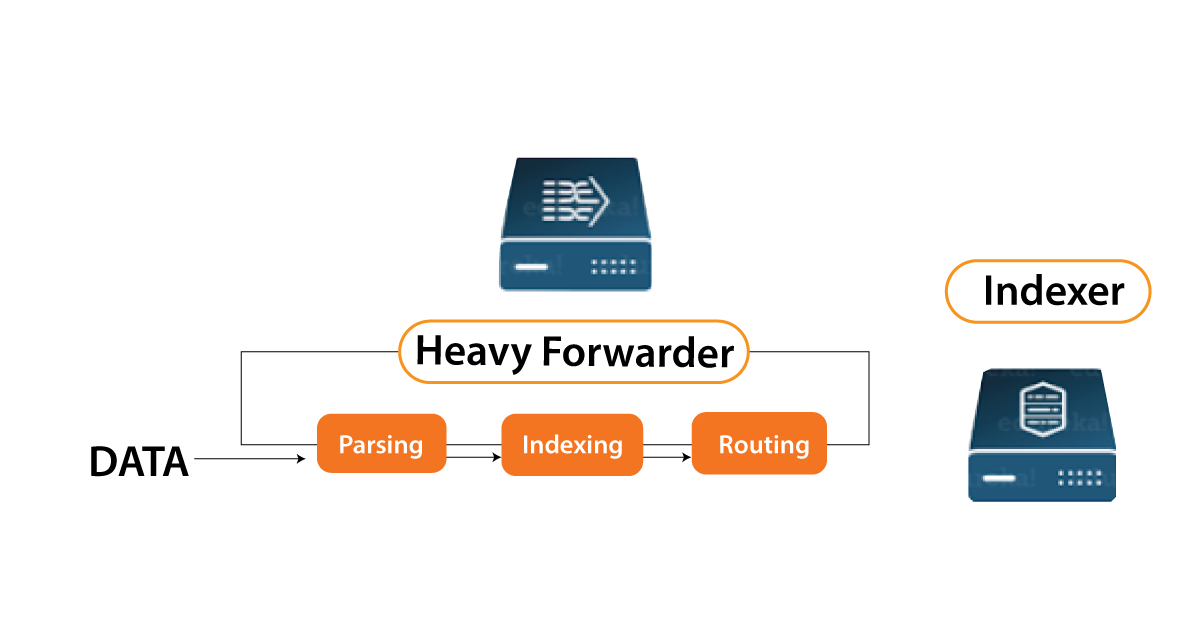 Splunk Indexer:
Splunk Indexer:
The indexer is the Splunk component that will be used to index and store the data from the forwarder. The Splunk instance converts incoming data into events and stores it in indexes for efficient search operations. If the data is received from a Universal forwarder, the indexer will first parse it before indexing it. Data parsing is used to remove unwanted data. However, if the data is received from a Heavy forwarder, the indexer will only index the data.
As your data is indexed by Splunk, it generates a number of files. These files contain one or more of the following:
- Compressed raw data
- Indexes pointing to raw data (index files, also known as tsidx files), as well as some metadata files
- These files are stored in buckets, which are collections of directories.
Now, let me explain how Indexing works.
Splunk processes incoming data to allow for quick search and analysis. It improves the data in a variety of ways, including:
- Dividing the data stream into discrete, searchable events
- Creating or determining timestamps
- Obtaining information such as host, source, and sourcetype
- Performing user-defined actions on incoming data, such as identifying custom fields, masking sensitive data, creating new or modified keys, breaking rules for multi-line events, filtering unwanted events, and routing events to specified indexes or servers.
This indexing procedure is also referred to as event processing.
Data replication seems to be another advantage of using Splunk Indexer. Splunk keeps multiple copies of indexed data, so you don't have to worry about data loss. This is known as index replication or indexer clustering. This is accomplished with the assistance of an Indexer cluster, which is a collection of indexers that are configured to replicate each other's data.
Lets's get started with Splunk Tutorial online!
Subscribe to our YouTube channel to get new updates..!
Splunk Search Head:
The search head seems to be the component that interacts with Splunk. It gives users a graphical user interface through which they can perform various operations. You can search and query the Indexer's data by entering search terms, and you will get the expected results.
The search head could be installed on separate servers or on the same server as other Splunk components. There is no separate installation file for the search head; to enable it, simply enable the splunkweb service on the Splunk server.
A search head in a Splunk instance can send search requests to a group of indexers, or search peers, who perform the actual searches on their indexes. The search head then combines the results and returns them to the user. This is a faster data search technique known as distributed searching.
Search head clusters seem to be groups of search heads who work together to coordinate search operations. The cluster clusters search head activity, assigns jobs based on current loads, and guarantees that almost all search heads have direct exposure to the same collection of objects.
Advanced Splunk Architecture:
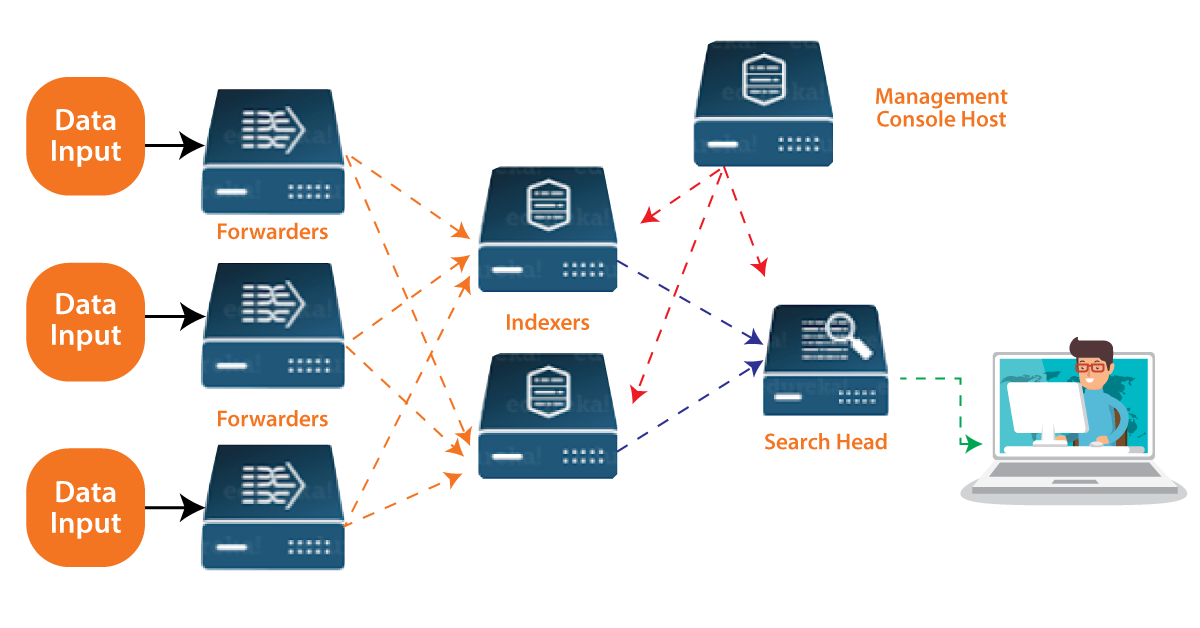
The above diagram represents the advanced architecture of splunk and end to end working.
Look at that picture above to see how Splunk works from start to finish. The images depict a number of remote Forwarders that send data to the Indexers. The Search Head can be used to perform various functions such as searching, analyzing, envisioning, and generating knowledge objects for Operational Intelligence based on the data in the Indexer.
The Management Console Host functions as a centralized configuration manager, distributing configurations, app updates, and content updates to Deployment Clients. Forwarders, Indexers, and Search Heads are the Deployment Clients.
Splunk Architecture:
If you understand the concepts described above, you will be able to easily relate to the Splunk architecture. Look at the image below for a consolidated view of the various process components and their functionalities.
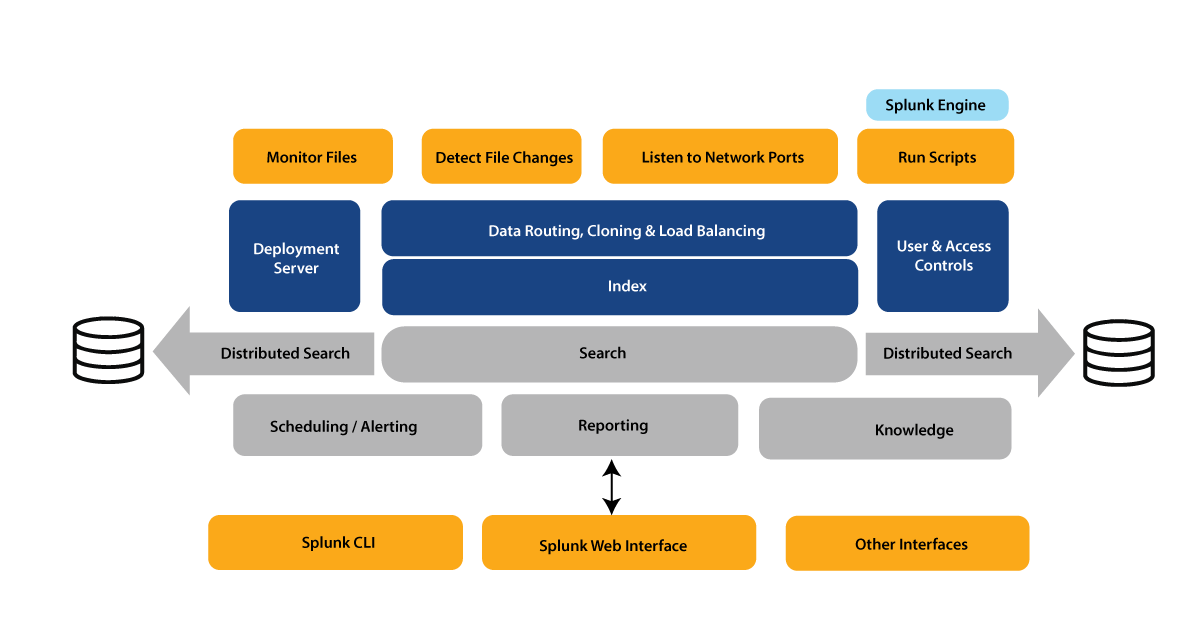
- You could indeed obtain information from numerous tcp port by operating data forwarding scripts.
- You can watch the files as they arrive and identify adjustments.
- First before data reaches the indexer, the forwarder can intelligently route it, clone it, and perform load balancing on it. Cloning is used to create multiple copies of an event at the data source, whereas load balancing is used to ensure that even if one instance fails, the data can be forwarded to another instance hosting the indexer.
- As previously stated, the deployment server is responsible for managing the entire deployment, including configurations and policies.
- When this information is received, it is saved in an Indexer. The indexer is then divided into logical data stores, and permissions can be set at each data store to control what each user sees, accesses, and uses.
- Once the data is in, you can search the indexed data and distribute searches to other search peers, with the results merged and returned to the Search head.
- Aside from that, you can perform scheduled searches and set up alerts to be triggered when certain conditions match saved searches.
- Using Visual representation dashboards, users could indeed create reports and analyze data using saved searches.
- Eventually, Knowledge objects can be used to enrich established unstructured data.
- A Splunk CLI or a Splunk Web Interface can be used to access search heads and knowledge objects. This communication takes place via a REST API connection.
Top 70 frequently asked Splunk interview questions & answers for freshers & experienced professionals
Conclusion:
I hope you enjoyed reading the splunk architecture blog that covers all the splunk components and their working in a detailed way.Had any doubts drop your queries in the comment section to get them clarified.
Other Blogs:
About Author
Upcoming Splunk Training Online classes
| Batch starts on 21st Jul 2026 |
|
||
| Batch starts on 25th Jul 2026 |
|
||
| Batch starts on 29th Jul 2026 |
|