
Cap Theorem in Big Data
Last updated on Jan 26, 2024


- Reviewed by
- Deeksha (Expert in Cloud Computing and Devops)
Explain CAP
CAP theorem is also called Brewer's theorem, which stands for Consistency, Availability, and Partition Tolerance.
Consistency:
This situation expresses, all nodes have similar information simultaneously. Implementing a read function will return the estimation of the latest write function making all nodes provide similar information. A framework has consistency if an exchange begins with the framework in a reliable state, and finishes with the framework in a predictable state. A framework can (and does) move into a conflicting state during an exchange, however the whole transaction gets moved back if there is a mistake during any process all the while. We have 2 unique records ("Bulbasaur" and "Pikachu") at various timestamps given in the picture below. The result on the third part is "Pikachu", the most recent input. The nodes will require time to refresh and won't be available on the organization as frequently.
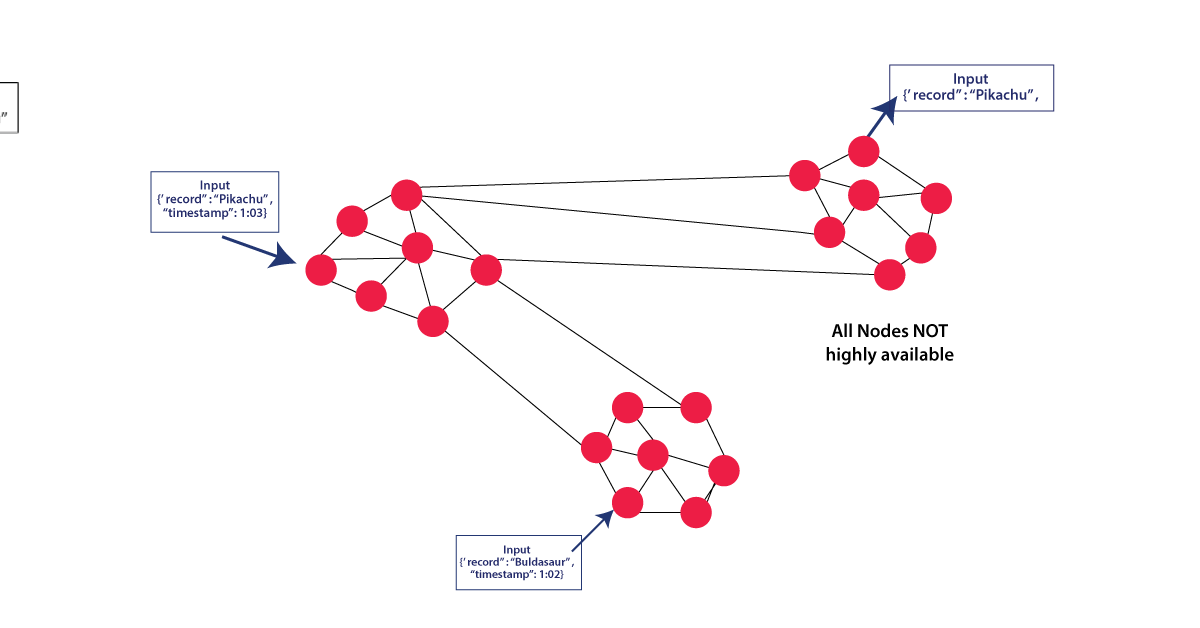
Availability:
This situation provides that each solicitation gets a reaction on success/failure. Accomplishing availability in an appropriated framework necessitates that the framework stays operational 100% of the time. Each customer gets a reaction, paying little heed to the condition of any individual node in the framework. This measurement is trifling to quantify: possibly you can submit the read/write commands, or you can't. Thus, the databases are time autonomous as they should be accessible online consistently. In contrast to the past model, we couldn't say whether "Pikachu" or "Bulbasaur" was included at first. The result could be any one among both. Consequently, high accessibility isn't feasible when dissecting streaming information at high frequency.

Partition Tolerance:
This situation expresses that the framework keeps on operating, in spite of the quantity of messages being deferred by the organization among nodes. A framework which is partition tolerant can support any measure of organization failure which does not bring about a failure of the whole network. Information records are adequately duplicated across blends of nodes and organizations to maintain the framework up through discontinuous blackouts. While managing current distributed frameworks, Partition Tolerance is a requirement and not a choice. Thus, we need to exchange among Consistency and Availability.

Enroll in our Apache Storm Training program today and elevate your skills!

Big Data Hadoop Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Distributed Database Systems
In a NoSQL type dispersed data set framework, Different PCs, or nodes, cooperate to give an impression of a unique operating database unit to the client in a NoSQL type distributed database system. They store the information among these numerous nodes. Every one of these nodes operates an event of the database server and they converse with one another. At the point when a client needs to write to the database, the information is suitably kept in touch with a node in the disseminated data set. The client may not know about where the information is composed.
Essentially, when a client needs to recover the information, it interfaces with the closest node in the framework that recovers the information for it, without the client thinking about this. Along these lines, a client essentially communicates with the framework as though it is connecting with a solitary information base. These nodes recover information that the client is searching for, from the important node, or putting away the information given by the client.
The advantages of a distributed system are very self-evident. The expansion in rush hour gridlock from the clients, we can undoubtedly scale our information base by including more nodes to the framework. As these nodes are commodity equipment, they are moderately less expensive than adding more assets to every one of the nodes independently. Horizontal scaling is less expensive than vertical scaling. The horizontal scaling assures that the replication of information is less expensive and simpler. It implies that now the framework can undoubtedly deal with more client traffic by fittingly appropriating the traffic among the recreated nodes.
Subscribe to our YouTube channel to get new updates..!
What is the CAP Theorem?
The CAP theorem states that a distributed database system has to make a tradeoff between Consistency and Availability when a Partition occurs.
A distributed database framework will undoubtedly have partitions in a certifiable framework because of network failure or some other explanation. Along these lines, partition tolerance is a property we can't dodge while setting up the framework. A distributed framework will either decide to abandon Consistency or Availability however not on Partition tolerance. For instance, if a partition happens among two nodes, it is difficult to give steady information on both the nodes and accessibility of complete information. Consequently, in such a situation we either decide to settle on Consistency or on Availability. A NoSQL circulated database is either portrayed as AP or CP. CA type information bases are for the most part the solid databases which operate on a solitary node and give no conveyance. Subsequently, they need no partition tolerance.
Where can the CAP theorem be used as an example?
The CAP theorem can indeed serve as an illustrative example within the realm of distributed database systems. When setting up a distributed database framework, it is inevitable to encounter partitions due to network failures or other unforeseen circumstances. Hence, partition tolerance becomes a necessary property that cannot be avoided in such a system. In this context, the CAP theorem comes into play. It states that a distributed framework must make a trade-off between either consistency or availability, as it is not possible to achieve both simultaneously when a partition occurs between two nodes. For instance, during a partition, it becomes challenging to maintain consistent data on both nodes while ensuring complete data availability. As a consequence, in such scenarios, we are left with the choice of prioritizing either consistency or availability.
To better understand this, it is essential to consider the different types of distributed databases. NoSQL distributed databases can be characterized as either AP or CP. AP databases prioritize availability and partition tolerance over strict consistency. On the other hand, CP databases prioritize consistency and partition tolerance at the expense of availability. These distinctions become crucial when deciding the appropriate database type for specific use cases.
CAP Theorem NoSQL Database Types
NoSQL (non-relational) databases are suitable for distributed network applications. NoSQL databases are horizontally adaptable and disseminated by layout, it can quickly scale across a developing network comprising different interconnected nodes.They are characterized dependent on the two CAP attributes they uphold:
CP database: A CP database conveys partition tolerance and consistency at the cost of accessibility. At the point when a partition happens between any two of the nodes, the framework needs to shut down the non consistent node (make it inaccessible) until the partition is settled.
AP database: An AP database conveys partition tolerance and accessibility at the cost of consistency. At the point when a partition happens, all nodes stay accessible however those at some unacceptable end of a partition may return a more established rendition of information than others.
CA database: A CA database conveys accessibility and consistency among all nodes. It will not be able to do this if there is a partition in between any two nodes in the framework, in any case, and can't convey adaptation to internal failure.
Spaces defined by CAP
CD Space: The engines of this space concentrate on accessibility and consistency, information dispersion doesn't prevail. It is the spot where Relational Databases are placed, in spite of the fact that we can likewise discover some NoSQL engines which are diagrammatically arranged.
ND Space: This doesn't receive any Databases engine and is an empty set. It repudiates the CAP Theorem on the grounds that with the most recent innovation it can't achieve with three of the Theorem features.
DT Space: Here, the resistance of divisions and consistency are favored, leaving to the side certain degree of accessibility. Confronting a network division, these Databases couldn't react to particular sorts of inquiries.
CT Space: Here the engines will support the accessibility and resistance of divisions, however that doesn't mean they do not provide any consistency as it is relative and can't ensure between nodes.
Conclusion
Distributed frameworks permit us to accomplish a degree of computing ability and accessibility that were essentially not accessible previously. The frameworks have better performance, lower inertness, and close to 100% up-time in servers which last till the whole globe. The frameworks are operated on product hardware which is effectively accessible and configurable at moderate expenses. Distributed frameworks are more intrinsic than their single-network partners. Learning the intricacy brought about in distributed frameworks, making the fitting compromises for the CAP, and choosing the correct apparatus for the task is essential with horizontal scaling.
About Author
Upcoming Big Data Hadoop Training Online classes
| Batch starts on 27th Jul 2026 |
|
||
| Batch starts on 31st Jul 2026 |
|
||
| Batch starts on 4th Aug 2026 |
|