
What is Pyspark
Last updated on Jan 24, 2024

What is Apache Spark?
Apache Spark is a specific Big Data analysis, storage, and data processing engine.It has many benefits over MapReduce: it is quicker, simpler to use, more easy, and can run just about anyhttps://moz.com/where. It has built-in tools for SQL, Machine Learning, and streaming, making this one of the most important and highest demanded tools in the IT business sector. Scala is the programming language used to create Spark. Although Apache Spark has APIs for Python, Scala, Java, and R, the former two are the most commonly used languages with Spark.
What is Pyspark?
PySpark is a Python-based tool developed by the Apache Spark Community for use with Spark.It enables Python to work with RDDs (Resilient Distributed Datasets). It also includes PySpark Shell, which connects Python APIs to the Spark core in order to launch Spark Context. Spark is the name of the cluster computing engine, and PySpark is the Python library for using Spark.
Here some of the important features of pyspark. They are:
- It comes with real time processing computations and calculations.
- It works dynamically with RDDS.
- In order to process the bulk datasets of big data pyspark serves as the fastest framework when compared with others.
- One of the most attractive features of pyspark is the effective disk persistence and memory caching.
- Moreover pyspark is most compatible with other programming languages such as python, scala, java when processing large datasets.
Become a Pyspark Certified professional by learning this HKR Pyspark Training !
Why Pyspark?
In order to perform the different operations on the big data, one needs to rely on different tools. But this is not a good sign when dealing with bulk datasets processing.In the current market there are several flexible and scalable tools that deliver enormous results form the big data. One such tool is the pyspark which acts as an effective tool while dealing with big data. At present many data scientists, IT professionals prefer python as it has simple and neat user interface design.So many data analysts prefer this tool for performing data analysis, machine learning on big data. And the Apache spark community came up with a tool by combining both the spark and python i.e pyspark in order to deal with big datasets very easily.
Who can learn the Pyspark?
Python is quickly becoming a powerful language in data science and machine learning. One will be capable of working with Spark in Python using Py4j's library. Python is a programming language popularly used throughout machine learning and data science. Python allows for parallel computing.
The prerequisite to take this pyspark course are:
- Python programming knowledge
- Big data knowledge and framework.
- PySpark is a good fit for someone who wants to work with big data.
Installation and configuration of Pyspark
Just before installing the apache, you need to make sure that java and scala are installed on your system. If not install them first. Now you will walk through how to set up the pyspark environment.
Now we will walk through the installation steps on the Linux platform first then on windows as well.
Installation on Linux platform:
Step1:just download the updated version of the apache spark form the official website apache spark and try to locate it in the downloads folder.
Step2:Now extract the spark tar file
Step3: Immediately after the extraction of files is done, use the following commands to move them to the specific folder as they are placed in the downloads folder by default.
/usr/local/spark
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv sp
ark-2.4.0-bin-hadoop2.7 /usr/local/spark
# exit
Step4:Now set up the PATH for the pyspark.
export PATH = $PATH:/usr/local/spark/bin
Step5:Set up the environment for pyspart by using the following command.
$ source ~/.bashrc
Step6:You need to verify the pyspark installation with the help of the following command.
$ spark-shell
Output will be displayed showing successful installation of pyspark.
Step7: Invoke the pyspark shell by running the command in the spark directory as follows.
# ./bin/pyspark

PySpark Training Certification
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Installation on Windows
In this section, we will learn how to install pyspark step by step on the Windows platform.
Step1:Download the latest version of spark from the official website.
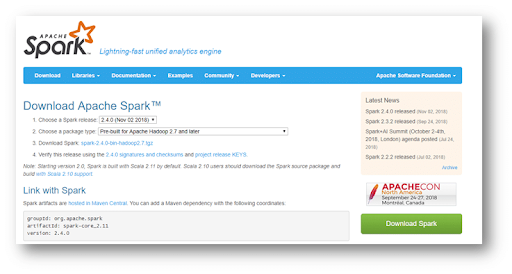
Step2: Now extract the downloaded file into a new directory.
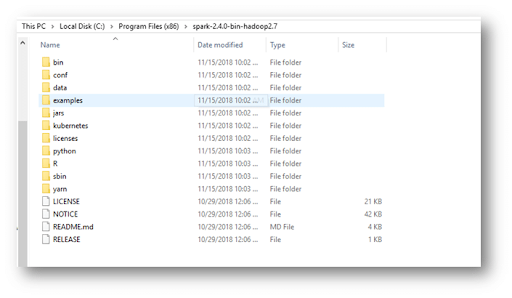
Step3: Now set the user and system variables as follows.
User variables:
- Variable: SPARK_HOME
- Value: C:\Program Files (x86)\spark-2.4.0-bin-hadoop2.7\bin
System variables:
- VAriable:PATH
- Value: C:\Windows\System32;C:\Program Files (x86)\spark-2.4.0-bin-hadoop2.7\bin
Step4: Now download the Windows utilities by clicking here and move them to the C:\Program Files (x86)\spark-2.4.0-bin-hadoop2.7\bin.
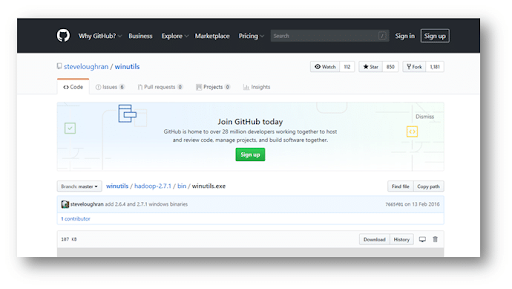
Step5: Now you can start the spark shell by the following command.
Spark-shell
Step6:In order to start or begin the pyspark shell type the following command as follows.
Pyspark
Now your pyspark shell environment is ready and you need to learn about how to integrate and perform operations on the pyspark.
Before driving into the pyspark operations you need to take care of configuration settings that you need to take care.
Subscribe to our YouTube channel to get new updates..!
SparkConf:
What is SparkConf?
SparkConf is indeed a configuration class that allows you to specify configuration information in key-value format. SparkConf would be used to define the configuration of the Spark application. It will be used to specify Spark application parameters as the key-value pairs. Just like an illustration, if you are developing a new Spark application, you will be able to specify the parameters as below:
Val Conf = new SparkConf()
.setMaster(“”local[2]””)
.setAppName(“”Program Name””)
Val sc = new SparkContext(Conf)
SparkConf assists in setting the necessary configurations and parameters needed to run the Spark application on the local or cluster. It offers configurations for a Spark application to execute. The details of a SparkConf class for PySpark are included in the following code block.
class pyspark.SparkConf (
loadDefaults = True,
_jvm = None,
_jconf = None
)
With SparkConf(), we will first develop a SparkConf object and load the values from the spark.* Java system properties too. The SparkConf object now allows you to set various parameters, and those options will take precedence over the system properties.
There are setter methods that facilitate chaining in a SparkConf class. You may write conf.setAppName("PySpark App").setMaster("local"), for example. A SparkConf object is unchangeable once we pass it to Apache Spark.
Well, before running any spark application you need to set some parameters and configurations and that can be done using the sparkconf.
Now we will discuss the most important attributes of the sparkconf while using the pyspark. They are:
- set(key, value): This attribute is used to configure a property.
- setMaster(value): The master URL is set using this attribute.
- setAppName(value): This attribute is used to specify the name of an application.
- get(key, defaultValue=None): This attribute is used to retrieve a key's configuration value.
- setSparkHome(value): This attribute is used to specify the location of the Spark installation.
Want to know more about Pyspark ,visit here Pyspark Tutorial !
Below is the code where some attributes of sparkconf are used mostly.
>>> from pyspark.conf import SparkConf
>>> from pyspark.context import SparkContext
>>>conf = SparkConf().setAppName("PySpark App").setMaster("local[2]")
>>> conf.get("spark.master")
>>> conf.get("spark.app.name")
You have learned about how to set configurations using the sparkconf, next you need to learn about the sparkcontext.
SparkContext:
SparkContext is the portal by which any Spark-derived application or usability enters. It is perhaps the most important thing that happens when you run any Spark application. SparkContext is available as sc by default in PySpark, so creating a new SparkContext will result in an error.
Here is the list of sparkcontext parameters. They are:
- Master: The cluster's web address SparkContext establishes a connection with.
- AppName: The title of your position
- SparkHome: A directory for installing Spark
- Py Files: The.zip or.py files are sent to the cluster and then added to the PYTHONPATH environment variable.
- Environment: Variables affecting the environment of worker nodes.
- BatchSize: The number of Python objects that are represented in the batch. To disable batching, set the value to 1; to choose the batch size automatically based on the object size, set it to 0; and to use an unlimited batch size, set it to 1.
- Serializer : This parameter describes an RDD serializer.
- Conf: An LSparkConf object used to set all Spark properties
- profiler cls: A class of custom profilers used for profiling; however, the default one is pyspark.profiler.BasicProfiler.
Among all the parameters master and AppName are most widely used. And the basic initial code used for every pyspark application are:
from pyspark import SparkContext
sc = SparkContext("local", "First App")
SparkFiles and Class Methods:
When you use SparkContext.addfile to upload data to Apache Spark, you will use SparkFile (). SparkFiles contains two types of commands. They are:
- get(Filename):When you need to specify the path of a file that you added using SparkContext.addfile() or sc.addFile(), use this class method ()
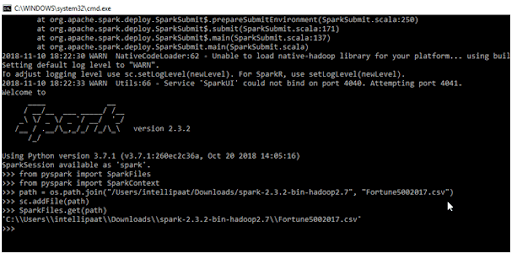
- Input:
>>> from pyspark import SparkFiles
>>> from pyspark import SparkContext
>>> path = os.path.join("/Users/intellipaat/Downloads/spark-2.3.2-bin-hadoop2.7", "Fortune5002017.csv")
>>> sc.addFile(path)
>>> SparkFiles.get(path)
- output
- Input :
>>> from pyspark import SparkFiles
>>> from pyspark import SparkContext
>>> path = os.path.join("/Users/intellipaat/Downloads/spark-2.3.2-bin-hadoop2.7", "Fortune5002017.csv")
>>> sc.addFile(path)
>>>SparkFiles.getRootDirectory()
- Output
Resilient Distributed Database(RDD):
Spark's RDD is one of its most important features. It is an abbreviation for Resilient Distributed Database. It is a group of items that are distributed across multiple nodes in a cluster in order to perform parallel processing. Faults can be recovered automatically by an RDD. Changes cannot be made to an RDD. However, you can create an RDD from an existing one by making the necessary changes, or you can perform various types of operations.
Here are the features of RDD. They are:
- Immutability: Once created, an RDD cannot be altered or reconfigured; however, if you want to make changes, you can create a new RDD from the existing one.
- Distributed: An RDD's data can exist on a cluster and be processed in parallel while parallel processing.
- Partitioned: More partitions distribute work among different clusters, but it also creates scheduling overhead.
Operations of RDDs:
Certain operations in Spark can be carried out on RDDs. These operations are, in essence, methods. RDDs can perform two types of operations: actions and transformations. Let us break them down individually with examples.
RDD is created using the following:
RDDName = sc.textFile(“ path of the file to be uploaded”)
Action Operations:
To perform certain computations, action operations are directly applied to datasets. The following are some examples of Action operations.
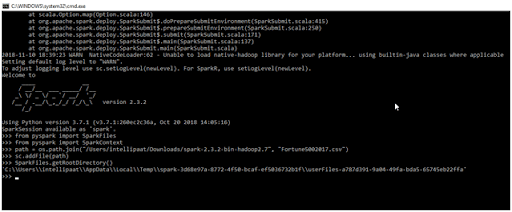
- take(n): This is one of the most commonly used RDD operations. It accepts a number as an argument and displays that many elements from the specified RDD.
- Input
>>> from pyspark import SparkContext
>>> rdd = sc.textFile("C:/Users/intellipaat/Downloads/spark-2.3.2-bin-hadoop2.7/Fortune5002017.csv")
>>>rdd.take(5)
- Output
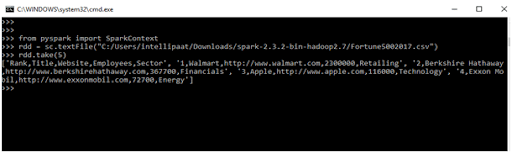
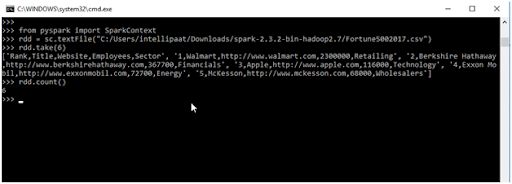
- count() It returns the number of elements in the RDD.
- Input
>>> from pyspark import SparkContext
>>> rdd = sc.textFile("C:/Users/intellipaat/Downloads/spark-2.3.2-bin-hadoop2.7/Fortune5002017.csv")
>>>rdd.take(5)
>>> rdd. count()
- Output
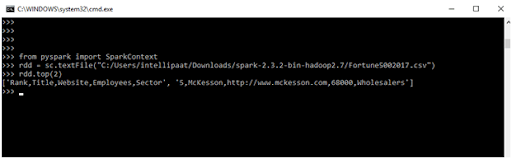
- top(n): This operation also accepts a number, say n, as an argument and returns the top n elements.
- Input
>>> from pyspark import SparkContext >>> rdd = sc.textFile("C:/Users/intellipaat/Downloads/spark-2.3.2-bin-hadoop2.7/Fortune5002017.csv") >>>
rdd.top(2)
- Output
Transformation Operations:
The set of operations used to create new RDDs, either by implementing an operation to an existing RDD or by creating an entirely new RDD, is referred to as transformation operations. Here are some examples of Transformation operations:
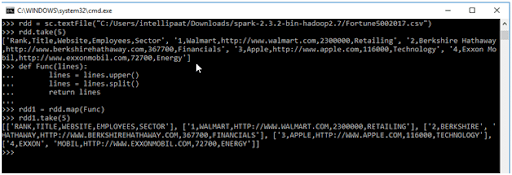
- Map Transformation: Use this operation to transform each element of an RDD by implementing the function to the entire element.
Map Transformation:
- Input
>>> def Func(lines):
. . . lines = lines.upper()
. . . lines = lines.split()
. . . return lines
>>> rdd1 = rdd.map(Func)
>>> rdd1.take(5)
- Output
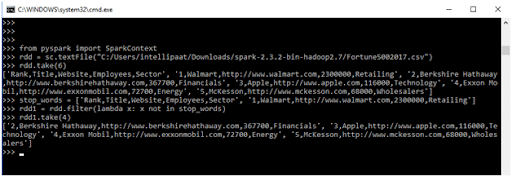
- Filter Transformation: Use this transformation operation to remove some elements from your dataset. These are known as stop words. You can create your own stop words.
- Input
>>> from pyspark import SparkContext
>>> rdd = sc.textFile("C:/Users/intellipaat/Downloads/spark-2.3.2-bin-hadoop2.7/Fortune5002017.csv")
>>> rdd.top(6)
>>> stop_words = [‘Rank, Title, Website, Employees, Sector’, ‘1, Walmart, http://www.walmart.com, 2300000, Retailing’]
>>> rdd1 = rdd.filter(lambda x: x not in stop_words)
>>> rdd1.take(4)
- Output
Top 30 frequently asked Pyspark Interview Questions !
Key Features of PySpark
- Real-time Computation: PySpark emphasizes on in-memory processing and offers real-time computing on massive amounts of data. It demonstrates the low latency.
- Support for Several Languages: Scala, Java, Python, and R are just a few of the programming languages that the PySpark framework is compatible with. Because of its compatibility, it is the best framework for processing large datasets.
- Consistency of disk and caching: The PySpark framework offers potent caching and reliable disk consistency.
- Rapid processing: With PySpark, data can be processed quickly around 100 times quicker in memory & 10 times quicker on the disk.
- Works well with RDD: Python is a dynamically typed programming language that comes in handy when working with RDD.
Machine Learning(MLib) In Spark
Pyspark is a machine learning API, MLib that accommodates several types of algorithms.The different types of algorithms in pyspark MLib are listed below:
- mllib.classification. The spark. mllib package includes methods for performing binary classification, regression analysis, and multiclass classification. Naive Bayes, decision trees, and other algorithms are commonly used in classification.
- mllib.clustering: Clustering allows you to group subsets of entities based on similarities in the elements or entities.
- mllib.linalg: This algorithm provides MLlib utilities for linear algebra support.
- mllib.recommendation: This algorithm is used to fill in missing entries in any dataset by recommender systems.
- spark.mllib: This library supports collaborative filtering, in which Spark uses ALS (Alternating Least Squares) to predict missing entries in sets of user and product descriptions.
PySpark Dataframe
PySpark Dataframe is just a collection of structured as well as semi-structured data that is distributed. Generally speaking, dataframes are a type of tabular data structure. Rows in PySpark Data Frames can contain a variety of data types, but columns could only contain one type of data. These data frames are actually two-dimensional data structures, much like SQL tables and spreadsheets.
PySpark External Libraries
PySpark SQL
On top of PySpark Core comes another layer called PySpark SQL. PySpark SQL is used to process structured and semi-structured data in addition to providing an optimised API that enables you to read data from various sources in various file formats. Both SQL and HIveQL are supported by PySpark for data processing. PySpark is rapidly growing in popularity among database programmers and Hive users due to its feature list.
GraphFrames
This is a library needed to process graphs. This library is designed for rapid distributed computing and provides a collection of APIs for quickly doing graph analysis efficiently using PySpark Core and PySpark SQL.
What is clustering and how is it implemented in MLlib?
Clustering is an essential process used in data analysis to identify groups or patterns within a set of data points. Its objective is to group similar data points together and distinguish them from points that are dissimilar. One popular clustering algorithm implemented in MLlib is the KMeans algorithm.
The KMeans algorithm divides data points into a fixed number of clusters. It iteratively assigns each data point to the cluster whose centroid is closest to it. The centroids, which represent the center of each cluster, are initially chosen randomly. In each iteration, the algorithm recalculates the centroids based on the mean of all the data points assigned to each cluster. This process continues until the algorithm converges and the centroids no longer move significantly.
MLlib also offers a parallelized variant of the k-means++ method called KMeans||. It is a scalable and distributed approach that improves on the efficiency of the KMeans algorithm. KMeans|| iteratively initializes the centroids by taking multiple random samples from the dataset. The algorithm then uses these initial centroids to perform the clustering process, resulting in faster convergence and improved performance for large datasets.
In MLlib, the KMeans algorithm is implemented as an Estimator, which means it can be used to create a KMeansModel. The KMeansModel represents the outcome of the clustering process and can be used to predict the cluster assignment of new data points based on their similarity to the existing clusters.
In summary, clustering is the process of grouping similar data points together, and MLlib implements it through the KMeans algorithm and its parallelized variant, KMeans||. The KMeans algorithm divides data points into clusters based on their proximity to centroids, whereas KMeans|| improves efficiency by initializing centroids using multiple random samples. These algorithms are applied in MLlib as Estimators, resulting in a KMeansModel that can be used to predict the cluster assignment of new data points.
What is regression analysis and what algorithms are available for regression in MLlib?
Regression analysis is a statistical technique used to identify and understand relationships, correlations, and dependencies between variables. It is a common approach in machine learning to predict and estimate numerical outcomes based on input features. MLlib provides various algorithms for regression analysis.
One widely used algorithm is linear regression, which attempts to model the relationship between input variables and a continuous output variable. It assumes a linear relationship between the inputs and the output and estimates the coefficients of the linear equation to make predictions.
MLlib also offers logistic regression, which is useful for binary classification tasks. Instead of predicting continuous values, logistic regression estimates the probability of an instance belonging to a particular class.
In addition to linear and logistic regression, MLlib provides several regression algorithms to handle different scenarios and improve performance. For example, Lasso regression encourages sparsity in the model by adding a regularization term to the objective function. Ridge regression, on the other hand, uses L2 regularization to prevent overfitting and stabilize the model.
Decision trees, random forests, and gradient-boosted trees are also available in MLlib for regression tasks. These tree-based algorithms recursively split the input data based on different conditions to create a predictive model. They are particularly useful for capturing non-linear relationships and handling complex datasets.
What are the different types of machine learning algorithms available in MLlib?
MLlib, the machine learning library in Apache Spark, provides several types of machine learning algorithms for different tasks such as classification, regression, clustering, and statistical analysis. Here are the key types of machine learning algorithms available in MLlib:
1. Classification Algorithms:
- Binary Classification: MLlib offers binary classification algorithms like decision trees, logistic regression, random forests, naive Bayes, and gradient-boosted trees. These algorithms are used to classify data into two distinct categories or classes.
- Multiclass Classification: MLlib also provides multiclass classification algorithms, including random forests, naive Bayes, logistic regression, and decision trees. These algorithms are used to classify data into multiple categories or classes.
2. Regression Algorithms:
- MLlib supports regression analysis, which aims to identify correlations and dependencies between variables. It offers regression algorithms like Lasso, ridge regression, decision trees, random forests, and gradient-boosted trees. These algorithms are used to predict continuous numeric values based on input variables.
3. Clustering Algorithms:
- MLlib includes clustering algorithms for unsupervised learning tasks, where the goal is to discover structure or patterns in the data without predefined labels.
One of the popular clustering algorithms in MLlib is KMeans, which divides data points into a fixed number of clusters. MLlib also supports parallelized variants of KMeans, such as KMeans|| (KMeans parallelized initialization).
Clustering methods help identify groups or clusters of data points that are similar to each other and dissimilar to those in other clusters. They are useful for tasks like customer segmentation, image grouping, and anomaly detection.
4. Statistical Analysis:
- MLlib provides summary statistics for RDD (Resilient Distributed Datasets) through the Statistics package.
- The colStats() function in MLlib's Statistics package returns various statistical measures for each column, including minimum, maximum, mean, variance, number of non-zero values, and total count.
These statistics are useful for getting insights into the distribution and characteristics of the data, which can be utilized in data preprocessing, feature engineering, and exploratory data analysis.
What is Spark MLlib and what is its goal?
Spark MLlib is an extensive library for machine learning (ML) within Spark. It aims to provide scalable and fundamental machine learning capabilities. The primary objective of Spark MLlib is to simplify the process of developing and deploying scalable ML pipelines.
When using MLlib, an essential aspect is to structure the data in a format that contains one or two columns: Labels and Features for supervised learning, and only Features for unsupervised learning. This approach allows for efficient handling and manipulation of data.
MLlib offers various mechanisms to support machine learning tasks at a higher level. These mechanisms include traditional learning algorithms like classification, regression, clustering, and collective filtering. Additionally, MLlib provides tools for featurization, such as feature extraction, transformation, dimensionality reduction, and collection.
Another key component of MLlib is the concept of pipelines, which are invaluable for building, analyzing, and fine-tuning machine learning models. These pipelines help streamline the development and deployment process, making it easier to manage complex ML workflows.
Persistence is a critical feature of MLlib, enabling users to save and reload algorithms, templates, and pipelines. This capability ensures that the ML models can be stored, shared, and reused as needed.
MLlib further provides utilities for linear algebra, statistics, and data handling, among other functionalities. This wide range of utilities assists in various aspects of machine learning tasks, enhancing the overall effectiveness and efficiency of the ML workflow.
What is Spark Streaming and how does it enable live streaming data processing?
Spark Streaming is a powerful framework within the Spark API that allows for the flexible and efficient processing of live streaming data. It provides the ability to consume data from various sources, including Kafka, Flume, HDFS/S3, and others. These sources serve as open-source libraries that help establish the necessary infrastructure for streaming data.
With Spark Streaming, the incoming live data is divided into manageable batches, which are then processed using high-level functions such as map, reduce, and enter. This processing is done by the Spark engine, which ensures fault tolerance and high throughput.
By capturing and analyzing the data in batches, Spark Streaming enables real-time processing of streaming data. This means that as new data arrives, it is immediately processed and integrated into the ongoing analysis. This real-time capability is crucial in scenarios where timely insights are essential, such as detecting anomalies, monitoring system performance, or responding to emerging trends.
The final result of Spark Streaming's data processing is the generation of a final batch, which contains aggregated insights and analytics. This can be seen as a continuous production of valuable information from the streaming data.
What is the difference between local and distributed systems?
Local systems and distributed systems differ in the way they provide access to computing tools and utilize computational resources.
A local system operates on a single computer, enabling users to use computing tools exclusively from that particular device. This means that all the computational services are confined to a single machine and are not shared with other devices connected to a network. Local systems are typically limited in terms of available computational power and scalability.
On the other hand, a distributed system expands beyond the capabilities of a single machine by making use of computational services that are accessed by a group of machines connected through a network. Distributed systems leverage the collective power and resources of multiple machines, allowing for enhanced performance and scalability.
One key advantage of distributed systems is their ease of scalability. To increase computational capabilities, more machines can simply be added to the network, enabling the system to handle higher workloads. In contrast, local systems face limitations in scaling up as it becomes increasingly challenging to enhance the performance of a single high CPU unit.
PySpark In Various Industries:
Apache Spark is a widely used tool in a variety of industries. However this application is not limited to the IT industry, though it is most prevalent in that sector. Even the IT industry's big dogs, such as Oracle, Yahoo, Cisco, Netflix, and others, use Apache Spark to deal with Big Data.
- Finance: In the finance sector PySpark is used to extract the information related to the call recordings, emails, and social media profiles.
- E-commerce: In this industry, Apache Spark with Python can be used to obtain knowledge into real-time transactions. It can also be used to improve user suggestions based on new trends.
- Apache HealthCare Spark is used to analyze patients' medical records,as well as their prior medical history, and then predict the most likely health issues those patients will face in the future.
- Pyspark is widely used in the media industry as well.
Conclusion
Pyspark is an industry benefited platform with enormous advantages.It supports the most general purpose and powerful programming languages like python. Python in combination with spark comes with advanced features, built in operations, building blocks that truly benefits the apache spark community to a great extent. Even if you don't have enough information I hope this blog post will help you a lot to get good data insights about the pyspark.
Related Articles:
About Author
Upcoming PySpark Training Certification Online classes
| Batch starts on 27th Jul 2026 |
|
||
| Batch starts on 31st Jul 2026 |
|
||
| Batch starts on 4th Aug 2026 |
|
FAQ's
PySpark is a popular tool developed by the Apache community to combine Python with Spark for different uses. Moreover, an API of Python built for Apache Spark allows Python users to work closely with RDD.
PySpark is commonly used to build ETL pipelines and supports all the basic features of data transformation. These include sorting, joins, mapping, and many more.
PySpark is a distributed computing framework that supports large-scale data processing in real-time using a set of libraries. Also, PySpark enables us to build a tempView that doesn’t give up runtime performance.
PySpark and SQL both have some standard features. Some SQL keywords have an equivalent in PySpark utilizing the dot function.
There are many uses of PySpark as it is an API of Python. Also, Python is an easy-to-learn language that improves code readability and maintenance. Further, it is a combination of Python and Spark, which makes it more widespread.