
Snowflake clustering
Last updated on Jul 15, 2024


- Reviewed by
- Deeksha (Expert in Cloud Computing and Devops)
What is a Snowflake?
Snowflake data cloud is a powerful data warehouse management platform. It is not an addition to already existing data warehouse management platforms. Snowflake data cloud is built on top of various cloud services such as Amazon web services, Microsoft Azure, and GCP (Google cloud platform) infrastructure. One more interesting thing about Snowflake data cloud is that this platform doesn’t require any installation prerequisites like hardware or software components to select, configure, or manage. With the help of the Snowflake data cloud, it’s easy to move the data into the ETL (extract, transfer, and load) process.
How does snowflake physically store data?
Snowflake tool allows users to access the data in one place so that they can deliver valuable outcomes. All business data in the snowflake is stored in the “Snowflake database tables” which are structured in rows and columns.
Points to remember while storing the data in Snowflake data cloud:
- When you create a table, then insert data records into the snowflake data cloud platform.
- Snowflake makes use of micro partitions and clustering of the data in the table structure.
- If the table grows, a few pieces of data in the column disappear.
The below image illustrates the data storage in the snowflake:
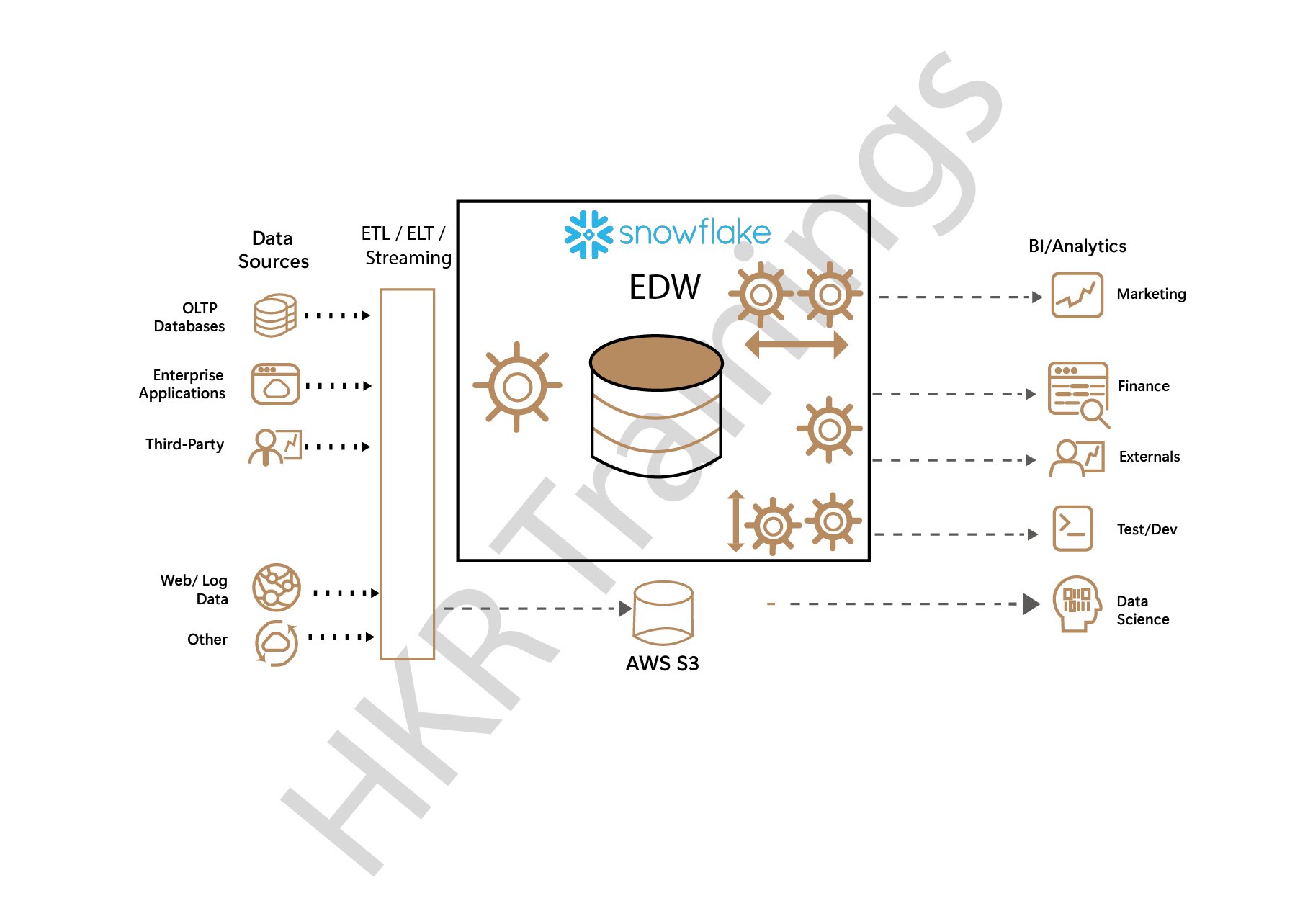
In the future section, we will be explaining more about micro partitions, and the auto clustering process.
Become a Snowflake Certified professional by learning this HKR Snowflake Training!
What are micro-partitions?
- All the stored data in the Snowflake table is automatically divided into micro-partitions. Each micro-partition contains between 50 Mb and 500 Mb of uncompressed data.
Each micro-partition is organized as a group of rows and columnar format. - This type of size and structuring helps users to check for the optimization and efficiency of the query processing.
- The purposes of using micro-partitions are, allow users to perform extremely efficient data manipulation language (DML) and fine-tuning of the data stored in the large tables. This can be further divided into millions or hundreds of millions of micro-partitions.
- In simpler words, we can define micro-partitions as query processing that specifies the filtering of the data prediction on a range of values that accesses almost 30% of the data values.
- It is very easy to derive the micro-partitions automatically when the data is ingested into the Snowflake and no need to define them explicitly by the users.
Here is an example of micro-partition;
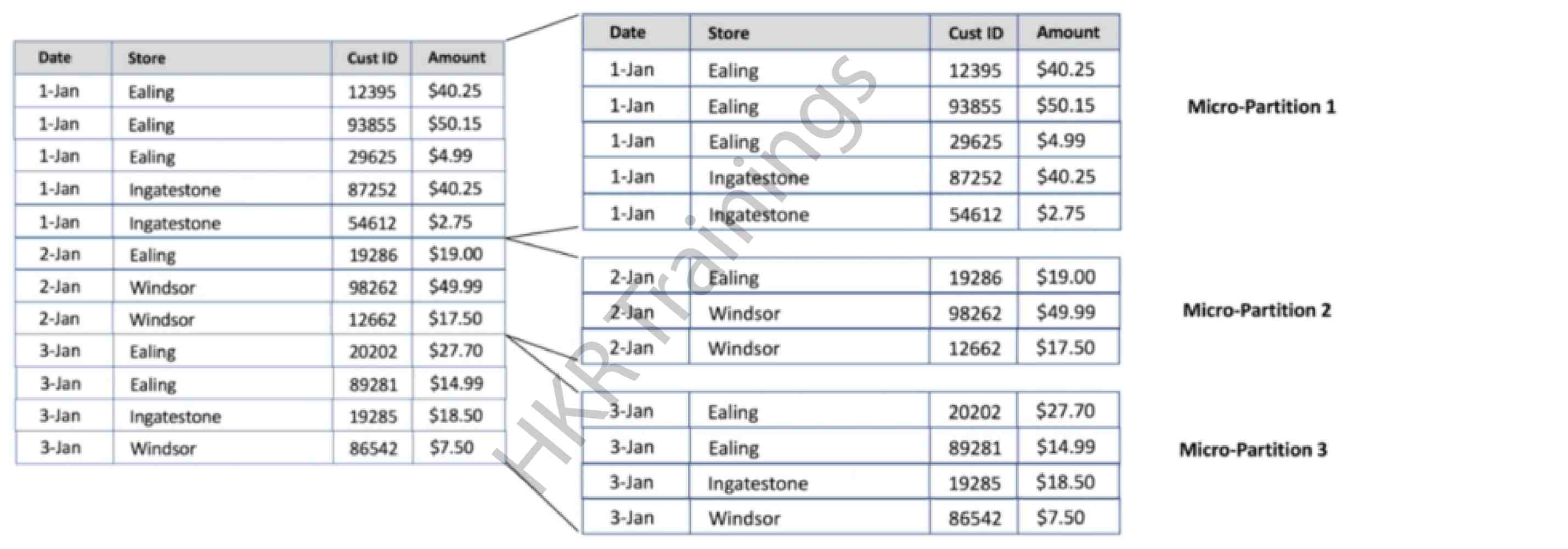
Snowflake uses the pruning (trimming) method to reduce the amount of data read from the storage.
In a query language, we define them using SELECT SUM (x) FROM T1 WHERE y = 42 (number of columns).
What is data clustering?
Important points to remember:
- Data clustering is a process of partitioning data in such a way that it should be optimized in real-time performance by allowing the query engine to ignore the data which is not required in the final result.
- In general, data is sorted or ordered along with natural dimensions.
For example date or geographic region format.
- Data clustering is a key factor in the query language because suppose if the table data is not fully sorted or not partially sorted may impact the query performance, particularly with the large tables.
- When users load into the Snowflake data table, metadata will be collected and stored for each micro-partitions which is created during the process.
- This type of metadata is usually used to optimize the data query at run time.
- Snowflake leverage (a method that is used to maximize performance) involves clustering of the data to avoid any unnecessary scanning of micro-partitions during the time of querying and this process significantly improves the data scanning efficiency of queries.
- Data clustering also filters the data column, this process may skip a large amount of data that does not match the predefined data.
- When a user creates the clustered data in a snowflake, the table data is organized automatically based on the contents of one or more columns in the table’s schema.
- The data order in the specified columns also defines the sorted order of the data.
- When the data is written to a snowflake’s clustered table either by a query job or a load job. Snowflake also sorts the data using the values in the clustering columns.
- These clustered column values organize the data into multiple blocks in snowflake storage.
- When you submit the data queries that contain a clause, which helps to filter the data that is based on the clustering columns.
- Snowflake also uses sorted blocks to eliminate the scans of unnecessary data.
The below image illustrates how does data clustering looks like:
Top 30 frequently asked snowflake interview questions & answers for freshers & experienced professionals

Snowflake Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
What is Snowflake clustering key?
The clustering key is just a subset of the Snowflake table where we store the data. These types of clustering keys are specifically used to co-locate the data in the snowflake table within the same micro partitions. Clustering keys are very useful while working with large data tables when ordering the column data is not the most favorable one or extensive DML (data manipulation language) on the table has caused the natural table clustering to upgrade.
Maximize the Query performance using clustering keys:
- Within the partitioned tables, each individual partitioned table behaves as an independent table (one table per partition).
- In such a case, the behavior of the clustering for each partition of a partitioned table is automatically extended to the clustering of the non-partitioned tables.
- Primitive non-repeated top-level columns take the support of the clustering keys such as INT64, BOOL, STRING, NUMERIC, GEOGRAPHY, TIMESTAMP, and DATE.
- In general, there are two types of typical usage patterns available for the clustering data patterns in the warehouse.
- The clustering on the table columns consists of a very high number of distinct values such as “USERID” and “transactionID”.
- Clustering on multiple columns that are used together frequently. When clustering is done by multiple columns, the order of the column which you specify is also important.
- The order of the specified columns define the sort order of the data. You can filter the data table by ant prefix of the clustering columns and enabling you to take the benefits of the clustering. The clustering methods which we use are; regionId, shopId, productId, together; or regionId, and shopId, or Just regionId.
- Data in the query table is stored in the “capacitor” blocks formats. That means the clustering specifies the “weak” sort order on the capacitor blocks.
The below example determines the clustering keys usage in the query;

- Clustering improves the query performance since it sorts the order of the table columns.
- This process enables the query data to optimize the aggregation; also computes the partial aggregation with the help of clustering keys.
- So the partial aggregation produces are smaller in size, thus reducing the amount of intermediate data that needs to be shuffled. This improves the aggregation query performance.
Clustering partitioned tables:
Take a look at a few points of clustering partitioned tables;
- In a partitioned data table, all the data is stored in the physical blocks. Each of these blocks holds one partition of the data.
- A partitioned table maintains all these operations wherever we need some modifications; the operations are like; query jobs, data manipulation language statements (DML), data definition language (DDL) statements, load query jobs, and copy jobs.
- To perform all these operations, the snowflake needs to maintain more metadata than a non-partitioned data table.
- As the number of partitions increase, the amount of metadata also needs to be stored more.
Automatic clustering:
- The snowflake automatic clustering is used to manage all the reclustering in the background seamlessly and continuously without using any manual intervention.
- Why do we need automatic clustering? The reason is as follows;
1. As new data is added to the clustered tables, the newly inserted data can be written to blocks that contain key ranges that overlap within the key ranges in previously written blocks.
2. These overlapping key ranges sometimes weaken the property of the clustered table. So to overcome this, we use automatic clustering.
The following image is an example of automatic reclustering;
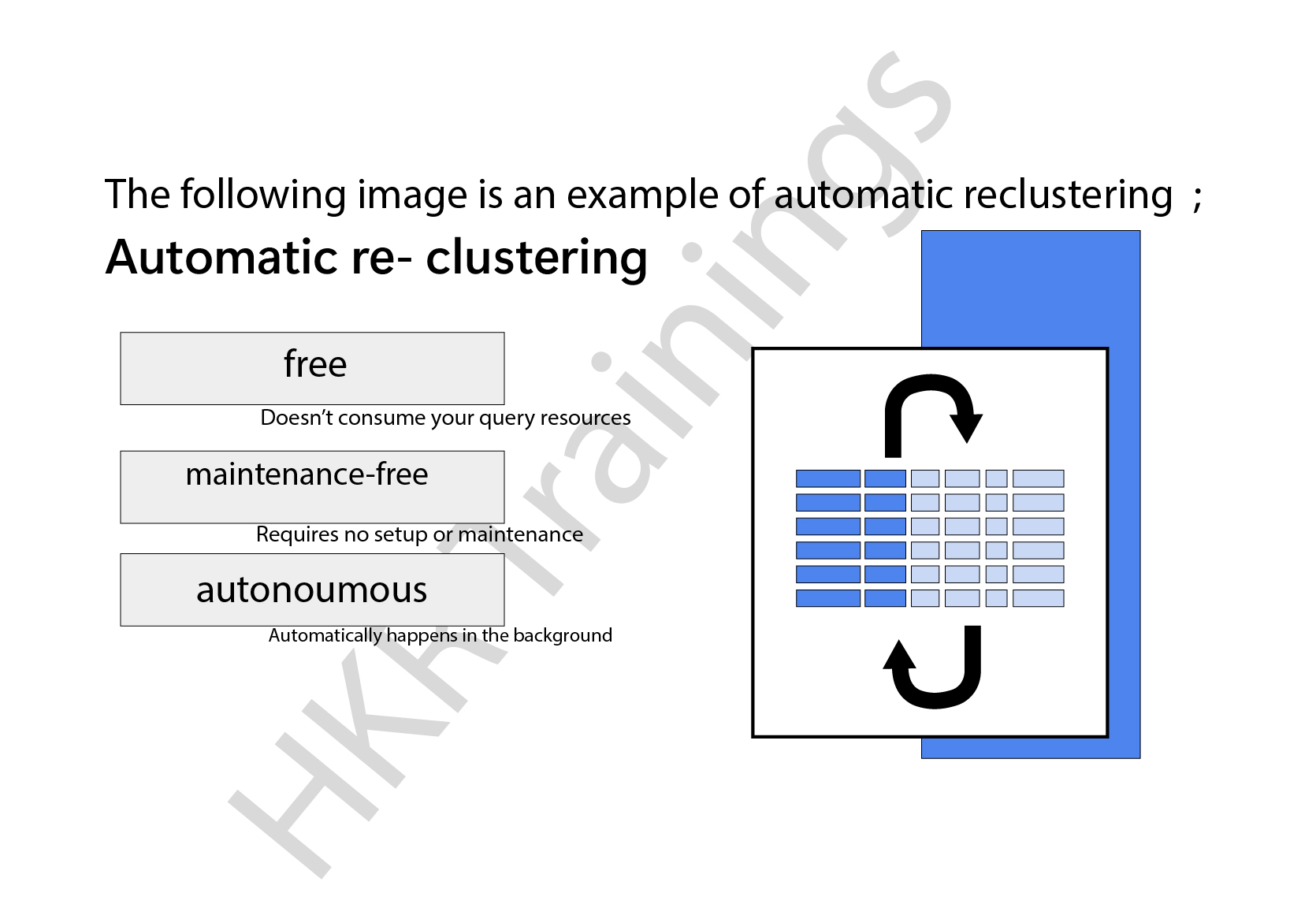
How does automatic reclustering work?
The most common question that comes to your mind is, how does this automatically reclustering work? Here is the answer;
- Automatic re-clustering works in a manner that is similar to the tree (Log structured merge tree).
- In a steady-state, most of the partitioned data is fully sorted into blocks they are referred to as a “baseline”.
- As new data is inserted into the partition, the query data may either perform a local sort for the new data or defer such sorting until there is a sufficient amount of data required to write.
- Once there is a sufficient amount of data, the system generates locally sorted blocks, which are known as “deltas”.
- After having deltas, the big queries (a fully managed, and a serverless data warehouse) attempt to merge the partitioned data. The auto-reclustering helps to avoid any duplicate data storage.
When to use clustering?
The following are a few examples that define when to use clustering:
- When you are starting from a large and unstructured data set.
- When you dont have any idea about how many or which classes your data is divided into.
- When you are manually dividing and annotating data if it is too resource insensitive.
- When you are looking out for anomalies to use in your data.
Defining a clustering key for a table :
As we know that snowflake supports both the partitioned and non-partitioned clustering. The below are the few scenarios that will explain when we need to use clustering;
1st scenario: you have fields that are accessed frequently in WHERE clauses: for example:
Select *from orders
Where product = ‘kindle’
- Here you have the tables that contain data in the multi-terabyte (MT) range.
- You have table columns that are actively used in filter clauses and queries that perform data aggregation. For example; when you have queries that frequently use the data column as a filter condition, choosing the data column is a good choice.
The below example describes it;
Select * from Orders
Where date
between ‘01-01-2020’ and ‘30-01-2020’
- You need more granularity than partitioning alone allows.
- To get clustering benefits in addition to partitioning benefits, you can use the same column for both partitioning and clustering.
2nd scenario:
Snowflake clustered table syntax:
You can use the following syntax to create clustered tables in Snowflake;
Create table…. Cluster by ( , , ….
3. Scenario:
Defining a clustering key for a table:
The following example creates a table with a clustering key by appending a cluster by clause to create a table.
For example:
— cluster by base columns
Create or replace table t1 (c1 date, c2 string, c3 number) cluster by (c1, c2);
–cluster by expression
Create or replace table t2 (c1 timestamp, c2 string, c3 number) cluster by (to_date(c1) , substring(c2, 0, 10) );
At any point in time, you can change or add clustering to an existing table using the alter table clause:
For example:
-- cluster by base columns
alter table t1 cluster by (c1, c3);
-- cluster by expressions
alter table t2 cluster by (substring(c2, 5, 15), to_date(c1));
-- cluster by paths in variant columns
alter table t3 cluster by (v:"Data":name::string, v:"Data":id::number);
You can also drop the clustering keys for a table using the alter table clause.
alter table t1 drop clustering key;
Get ahead in your career with our Snowflake Tutorial!
Subscribe to our YouTube channel to get new updates..!
Snowflake clustering best practices:
- If you define two or more columns/ expressions as the clustering keys for a table, the order has an impact on how the data is clustered in micro-partitions.
- Existing clustering keys are copied when a table is created using CREATE TABLE……CLONE.
- If the existing clustering is not propagated when a table is created using CREATE TABLE …..LIKE.
- An existing clustering is not supported when a table is created using the CREATE TABLE …..AS SELECT. However, you can define the clustering key once you create a table.
- Defining a clustering key directly on top of the VARIANT is not supported, however, you can specify the VARIANT column in a clustering key if you provide an expression consisting of the path and the target type.
Final take:
In this snowflake clustering article, we have defined many core topics like micro-partitions, data clustering, clustering key usage, maximizing the query performance, and auto clustering. I hope we are able to justify our reader’s expectations and help them to achieve great success in the respective technologies.
Related Articles:
About Author
Upcoming Snowflake Training Online classes
| Batch starts on 31st Jul 2026 |
|
||
| Batch starts on 4th Aug 2026 |
|
||
| Batch starts on 8th Aug 2026 |
|