
What is AWS Athena
Last updated on Jun 12, 2024


- Reviewed by
- Deeksha (Expert in Cloud Computing and Devops)
- What is AWS Athena?
- How does AWS Athena work?
- AWS Athena Benefits
- Amazon Athena Use case
- Optimization Techniques for AWS Athena
- Pros and Cons AWS Athena
What is AWS Athena?
AWS Athena is a service offered by Amazon. It enables data analysts to query data from S3 (Simple Storage Service) by using Standard SQL (Structures Query Language) syntax. AWS is a leader in cloud computing technology. The most popular service in the Amazon analytics domain is known as AWS Athena. As Athena is a serverless query service, therefore there is no requirement for managing infrastructure or loading S3 data for analysis also. An analyst can access data via the AWS Management Console, an application programming interface. The user has to then design a scheme and start building to execute SQL queries.
What is Amazon Athena used for?
An Amazon Athena user can query the encrypted data with the help of keys that are managed by AWS Key Management Service and then encrypt query results. It is thereby an analytical tool for two-way and responsive query service which helps organisations to analyse data of Amazon S3. It also enables cross-account access to any S3 buckets owned by other users.
Athena users can manage data catalogues to store all the information and schemes related to searches on Amazon S3 data. Thus, it can process unstructured, semistructured, and also structured data sets. This can be further used for research, log analysis, and also online analytical processing.
How does AWS Athena work?
AWS Athena works directly with all the data that is stored in S3. It is used to run queries with the help of Presto which is a distributed SQL engine. It also uses Apache Spark hive for the creation and alteration of tables and partitions.
Before we find out how Athena works, let us understand all the prerequisites to start working on it!
A user needs to have an AWS account
- Make sure that you have enabled your account to export the cost and sausages data into an S3 bucket.
- The user has to prepare buckets for AWS Athena to connect.
- Every time Athena writes to the bucket AWS creates manifest files using the metadata.
- To simplify data, the user can use one region. I.e. US-West 2 region.
- The last step is to download the credentials for the new IAM user. These credentials will then directly map to the database credentials to connect.
Become a AWS Certified professional by learning this HKR AWS Training !

AWS Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
1. Create Databases - To begin, create both an Athena database and a table. Remember you need to create a table that will match CSV formats and files in the S3 billing bucket.
Few unseen errors that can be viewed are as follows
- Users can parse the CSV file by using the open CSV serde plugin.
- The plugin only supports gzip files and not zip files. You will need to convert the compression format to gzip or any of the supporting formats.
- The plugin claims to support skip. Line. header. Count to skip header rows, it seems to be broken though. Then, you will have to rewrite the CSV files manually without the header.
- You can run the Data Definition Language using either the AWS web console or via the product for creating databases.
2. Partitioning Data - Users generally store their data in time series format and require to query specific data considering period time i.e day, months, and year. Without partitioning data, Athena will scan all the data without executing queries. By partitioning the data you can restrict Athena, thus reducing time, and effort, and lowering cost. This will help to improve performance also.
3. Convert data into columnar facts - Customers can use open sources columnar formats such as Apache ORC and Apache Parquet. It will save cost as well as improve the performance.
4. Compare the Performance - The user can compare the performance of the same query between Parquet files and text files.
AWS Athena charges the users by the amount of data that is scanned per query. By converting the data to columnar formats, Partitioning, and compressing it, you will save cost and also get better performance.
AWS Athena Benefits
1. Serverless: As AWS Athena is serverless there is no need for infrastructure to use the tool. You can quickly query the data without the need of setting up servers or data warehouses. It allows the user to tap all the data easily. All you need is to set up a schema and begin querying by using the inbuilt query editor.
2. Cost Effective: For using AWS Athena users have to only pay for the queries they run. They only have to shell money for the amount of data that is scanned per query. Also, there are no additional charges for storage as the user has to perform queries directly in S3.
3. Widely Accessible: It is accessible on a larger scale for everyone from developer’s engineers to business analysts to other data specialists, as it is merely a query tool that uses normal Structure Query Language. The queries are simple & easy hence can be used by anyone.
4. Flexibility: A versatile and open architecture of AWS Athena guarantees that the user is not limited or tied up with a single provider, tool, or technology. For instance, the user can work with the Nth number of file formats that are open source without changing the schema swap amongst query engines.
5. Secure: Amazon provides its users with services that are secured. Security is its priority. The effectiveness of which is regularly tested and verified by third-party auditors which is a part of AWS compliance programs.
6. Integration: AWS Athena can integrate with a variety of tools such as AWS Glue, Key Management Service, and Amazon Quicksight. For example, If a user integrates Athena with Glue then the user can access the Glue catalogue which will help him to create a metadata repository across various services.
Join our AWS Technical Training today and enhance your skills to new heights!
Subscribe to our YouTube channel to get new updates..!
Amazon Athena Use case
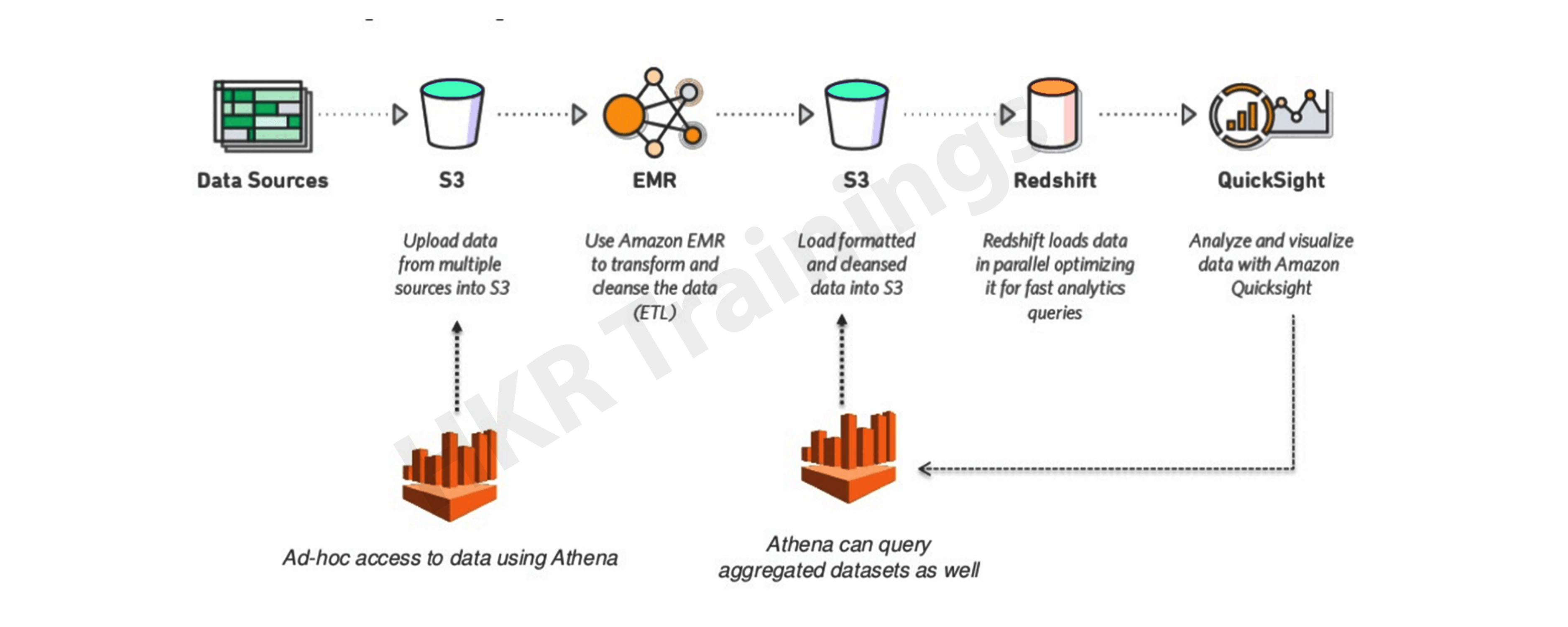
Let’s take an example. As shown in the diagram given above. It depicts a data pipeline whereby data is retrieved and then put in S3 buckets taken from many sources. As the image indicates, unprocessed data depicts that they are not transferred yet. So, the user now can connect the data to S3 using AWS Athena and start analyzing them.
There is no requirement of setting up a database or using external tools for querying the raw data, hence a very straight approach. Once you complete your research and get the desired results. You can use EMR as seen in the diagram to do data transformations and complex analytics and return to S3 after cleaning and processing the data that is raw
The user can then use Athena for querying the processed data to analyse it further. Quick sight can also connect directly with AWS Athena and create images of the data which is stored on S3. You can also migrate the data to Amazon RedShift which is a MPP data warehouse for data analysis, then the user should use QuickSight to view the data from the Redshift.
Optimization Techniques for AWS Athena
AWS Athena has proved to be decently priced. But its billing process is not simple. It will let you know the funds used but would be difficult to see how and when.
Following are the optimization techniques that you can use to optimise AWS Athena
Partitioning the data in S3: Partitioning the data will help to divide it into parts and keep the related data in one place based on column values such as date, region, and country. It acts as virtual columns. First, you need to define the table and then reduce the data that needs to be scanned for the query. You can restrict the query i.e., the amount of data that should be scanned based on the partition. Therefore, Athena will only scan the necessary data and charge accordingly.
Use Data Compression Techniques: AWS Athena supports many compression formats for both readings and writing the data. It can successfully read the data from a table that uses Parquet file format when it is compressed with snappy and others with GZIP. The same condition applies to text files, ORC, and JSON storage formats. Various compression formats that Athena supports are GZIP, LZO, SNAPPY, DEFLATE, and others.
Optimise JOIN conditions in queries: Selecting the right join order is important for better query performance. In case you are joining two tables, mention the larger table and smaller table on the left and right side of the join respectively. It distributes the table to worker notes which is on the right and then the left side of the table is streamed to do the join. If the right-side table is smaller then less memory is utilised and also the query runs faster.
Top 50+ frequently asked AWS interview questions !
Amazon Athena Pricing
AWS Athena is very cost-effective. The charges are calculated on the quantity of data that is scanned during query execution. It costs around $5 per Terabyte of data. An additional advantage of using Athena is it allows users to compress data and have Columnar formats, and also routinely delete the old results sets.
Additional charges: Since Amazon Athena reads your data that is stored in Amazon S3 there will be nominal charges for the storage of the data depending on the nature of its storage. History & results are also stored in the S3 bucket therefore, there will be charges which are very nominal for the data stored in that bucket too.
For Instance - Let us consider a table with equal size on S3 with three columns with a size of 3 TB in total as an uncompressed file. Since the text formats are impossible to be divided, running queries to extract the data from each column of the table would require AWS Athena to scan the whole file.
Thus the query would cost approximately $15. Price of 3 TB ( Terabyte) of data scanned i.e. 3*5= 15 $
Pros and Cons AWS Athena
Pros:
- The query of the data is possible for 24 X 7 without running servers.
- It is a cost-effective method as compared to traditional databases.
- Glue and Athena use the same data catalog. Therefore, data analysis becomes easy.
- No need for any configuration.
- Ad hoc to make check the data
- It integrates easily with QuickSight.
Cons:
- Data optimization is not possible. It can only optimise the queries but not the underlying data.
- All the users of AWS Athena across the globe share the same sources while running the queries.
- It does not support data manipulation operations. Because AWS Athena provides merely a query service. It does not have a DTL interface to insert, delete, and update the data.
- It requires data partitioning.
- It does not have an indexing feature.
Conclusion
AWS Athena is thus very cost-effective when compared with its competitors in the market. As it charges only when the user utilises it. Athena helps the user with the ability to use the standard SQL statements on data that is stored in S3 buckets. As seen, there are many benefits of using Amazon Athena along with a few limitations. All you need is to understand the requirements of your organisation and make a sound decision.
About Author
Upcoming AWS Training Online classes
| Batch starts on 26th Jul 2026 |
|
||
| Batch starts on 30th Jul 2026 |
|
||
| Batch starts on 3rd Aug 2026 |
|
FAQ's
S3 is a lightweight solution that is designed to let the analyst use SQL to perform a single object but Athena can be used for querying multiple objects at once. Athena can also be used for complex queries while a user can use S3 only for simple queries. AWS Console can use Athena whereas S3 is an API.
The advantages and disadvantages of using Athena are as follows:
- Users can run multiple & complex queries parallelly.
- Presto can be used to run SQL queries. It is open source and also optimised for data analysis.
- Athena is serverless and hence there is no need for infrastructure.
- Cost effective, as you only pay for the data that is scanned. It costs approx $5 per terabyte of data that is scanned.
Disadvantages :
- Data that is stored in S3 cannot be optimised. Optimization is limited to only queries.
- The column and row size cannot be increased by more than 32 megabytes
- If a source file starts with an underscore or a dot it will be treated as hidden.
- Athena can be timed out if a user queries a table with thousands of partitions.
The limitations of AWS Athena are:
- AWS has database limits, for instance, the Amazon S3 bucket limit is only 100 buckets per user/account by default. Though one can increase it to 1000 S3 per user.
- The Amazon Athena query string hard limit is only 262144 bytes.
- The Athena Data Manipulation Language query is also limited to 30 minutes.
Both Redshift spectrum and Amazon Athena are serverless but they differ in various aspects from one another.
- To return query results Athena relies on pooled resources which are provided by AWS whereas, in Spectrum Redshift cluster size allocates the resources.
- Redshift Spectrum gives users more control as compared to Athena.
- In case you want any specific query to return quickly you can allocate an additional computer resource. The same cannot be done using Athena.
Amazon Glue is an ETL service that allows users to manipulate data and also the management of data pipelines. Therefore it is more of a transformation and data movement tool. On other hand, Amazon Athena is majorly used as a query tool for the analysis of data.