
Hadoop Ecosystem
Last updated on Jan 19, 2024

- The important features of Hadoop are
- Hadoop Ecosystem
- HDFS
- Components of YARN
- Components of HBase
- Advantages of HCatalog
- Conclusion
The important features of hadoop are:
- It is an open source programming language code where you can change the code as per your need.
- Hadoop manages flaws through the replica creation process.
- In HDFS, Hadoop stores massive amounts of data in a distributed manner. On a cluster of nodes, process the data in parallel.
- Hadoop is a free and open source platform. As a result, it is an extremely scalable platform. As a result, new nodes can be easily added without causing any downtime.
- Even after machine failure regarding data replication, information is accurately stored on the cluster of machines. As a result, even if one of the nodes fails, we can still store data reliably.
- Information is particularly accessible despite hardware failure due to multiple copies of data. As a result, if one machine fails, data can be retrieved from the other path.
- Hadoop is extremely adaptable when it comes to dealing with various types of data. It handles structured, semi-structured, and unstructured data.
- There is no need for the client to deal with distributed computing because the framework handles everything. As a result, it is simple to use.
Become a Hadoop Certified professional by learning this HKR Hadoop Training
Hadoop Ecosystem:
Hadoop Ecosystem is a framework or a suite that offers a variety of services to fix complex problems. It includes Apache projects as well as a variety of commercial tools and solutions.Hadoop is composed of four major components: HDFS, MapReduce, YARN, and Hadoop Common. The majority of the techniques or strategies are used to augment or assist these key components. All of these tools work together to provide services such as data absorption, analysis, storage, and maintenance.
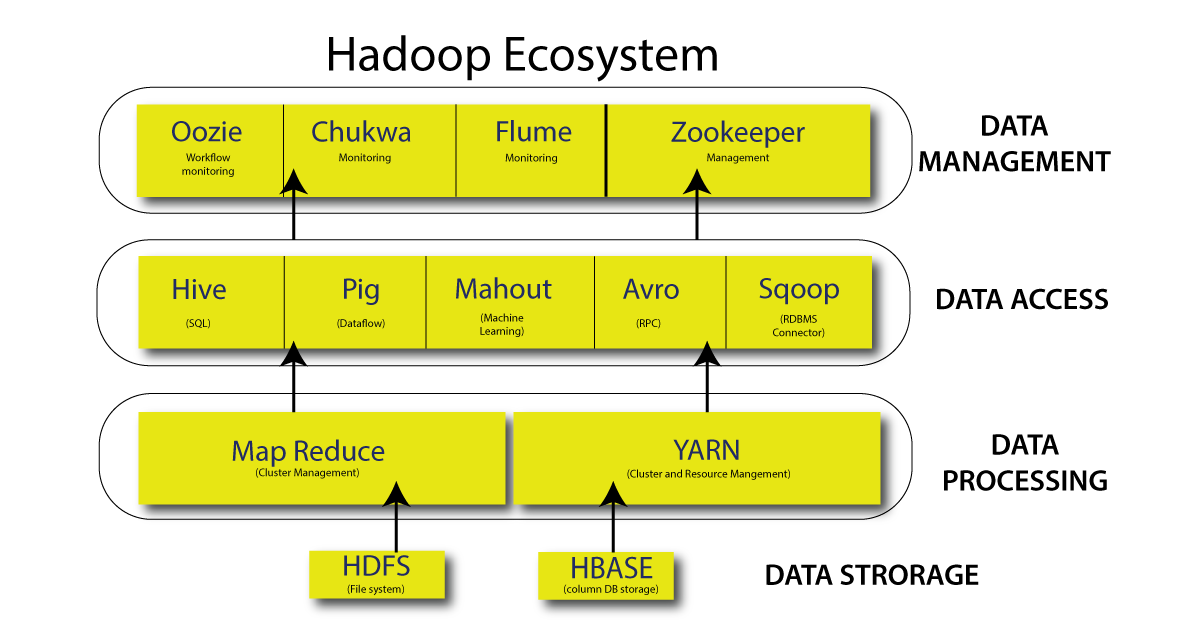
Now let us discuss each and every component of the hadoop ecosystem in detail.
HDFS:
Hadoop's primary storage system is the Hadoop Distributed File System (HDFS). HDFS is a file system that stores very large files on a cluster of commodity hardware. It adheres to the principle of storing fewer large files rather than a large number of small files. HDFS reliably stores data even in the event of hardware failure. As a result, by obtaining in parallel, it offers superior utilization access to the database.
Elements of HDFS:
The two elements of HDFS are namenode and datanode.
- NameNode – It serves as the master node in a Hadoop cluster. Namenode stores meta-data, such as the number of blocks, replicas, and other information. Meta-data is stored in the master's memory. The slave node is assigned tasks by NameNode. Because it is the heart of HDFS, it should be deployed on dependable hardware.
- DataNode – It functions as a slave in a Hadoop cluster. DataNode in Hadoop HDFS is in charge of storing actual data in HDFS. DataNode also performs read and write operations for clients based on their requests. DataNodes can be deployed on commodity hardware as well.
MadReduce:
Hadoop is an acronym for Hadoop Distributed File Hadoop's data processing layer is MapReduce. It works with large amounts of structured and unstructured data stored in HDFS. MapReduce can also handle massive amounts of data in parallel. It accomplishes this by breaking down the job (submitted job) into a series of independent tasks. MapReduce in Hadoop works by dividing the processing into two phases: Map and Reduce.
- Map – The first stage of processing in which we define all of the complicated control code.
- Reduce – This is the second step in the implementation phase of the project. Lightweight processing, such as aggregation/summation, is specified here.
YARN:
The resource management is handled by Hadoop YARN. It is Hadoop's operating system. As a result, it is in charge of managing and monitoring workloads, as well as implementing security controls. It serves as a centralized platform for delivering data governance tools to Hadoop clusters.
YARN supports a variety of data processing engines, including real-time streaming, batch processing, and so on.
Components of YARN:
The components of YARN are resource and node manager.
The Resource Manager is a cluster-level component that is installed on the Master machine. As a result, it manages resources and schedules applications that run on top of YARN. It is made up of two parts: the Scheduler and the Application Manager.
Node Manager is a component at the node level. It is executed on each slave machine. It communicates with the Resource Manager on a regular basis in order to stay up to date.
Become a Big Data Hadoop Certified professional by learning this HKR Big Data Hadoop Training

Hadoop Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Hive:
The Apache Hive is a free open source data warehouse system that can query and analyze huge databases stored in Hadoop files. In Hadoop, it processes structured and semi-structured data. Hive also supports the analysis of large datasets stored in HDFS and the Amazon S3 filesystem. Hive employs the HiveQL (HQL) language, which is similar to SQL. HiveQL automatically converts SQL queries into mapreduce jobs.
Pig:
It is a high-level language platform designed to run queries on massive datasets stored in Hadoop HDFS. PigLatin is a pig language that is very similar to SQL. Pig loads the data, applies the necessary filters, and dumps the data in the appropriate format. Pig also converts all operations into Map and Reduce tasks that are efficiently processed by Hadoop.
Components of pig:
The components of pig are: extensible, self optimizing and handles all kinds of data.
- Extensible Pig users can write custom functions to meet their specific processing needs.
- Self-optimization allows the system to optimize itself. As a result, the user can concentrate on semantics.
- Handles all types of data i.e both structured and unstructured data.
HBase:
Apache HBase is a NoSQL database that runs on Hadoop. It's a database that holds structured data in tables with billions of rows and millions of columns. HBase also allows you to read or write data in HDFS in real time.
Components of HBase:
HBase Master – This is not a data storage system. However, it is in charge of administration (interface for creating, updating and deleting tables.).
The Region Server is the worker node. It handles client read, write, update, and delete requests. The region server process is also executed on each node in the Hadoop cluster.
Get ahead in your career with our Hadoop Tutorial!
Subscribe to our YouTube channel to get new updates..!
HCatalog:
On top of Apache Hadoop, it is a table and storage management layer. Hive relies heavily on HCatalog. As a result, it allows the user to save their data in any format and structure. It also allows different Hadoop components to read and write data from the cluster with ease.
Advantages of HCatalog:
- Make data cleaning and archiving tools visible.
- HCatalog's table abstraction frees the user from the overhead of data storage.
- Allows data availability notifications.
Arvo:
It is an open source project that provides Hadoop with data serialization and data exchange services. Service programs can serialize data into files or messages by using serialization. It also stores both the data definition and the data in a single message or file. As a result, programs can easily understand information stored in an Avro file or message on the fly.
Arvo provides the following.
- Persistent data is stored in a container file.
- Call for a remote procedure.
- Data structures that are rich.
- Binary data format that is small and fast.
Thrift:
Apache Thrift is a software framework that enables the development of scalable cross-language services. Thrift is also used to communicate with RPCs. Because Apache Hadoop makes a lot of RPC calls, there is a chance that Thrift can help with performance.
Drill:
The drill is used to process large amounts of data on a large scale. The drill is designed to scale to thousands of nodes and query petabytes of data. It is also a distributed query engine with low latency for large-scale datasets. In addition, the drill is the first distributed SQL query engine with a schema-free model.
The characteristics of drill are:
- Drill decentralized metadata – Drill does not necessitate centrally controlled metadata. Drill users do not need to create or manage metadata tables in order to query data.
- Drill provides a hierarchical columnar data model for flexibility. It is capable of representing complex, highly dynamic data while also allowing for efficient processing.
- To begin the query execution process, use dynamic schema discovery. Drill does not require any data type specifications. Drill instead begins processing the data in units known as record batches. During processing, it also discovers schema on the fly.
Mahout:
It is a free and open source framework for developing scalable machine learning algorithms. Mahout provides data science tools to automatically find meaningful patterns in Big Data sets after we store them in HDFS.
Sqoop:
It is primarily used for data import and export. As a result, it imports data from external sources into Hadoop components such as HDFS, HBase, and Hive. It also exports Hadoop data to other external sources. Sqoop is compatible with relational databases like Teradata, Netezza, Oracle, and MySQL.
Flume:
Flume efficiently collects, aggregates, and moves a large amount of data from its origin to HDFS. It has a straightforward and adaptable architecture based on streaming data flows. Flume is a fault-tolerant and dependable mechanism. Flume also allows data to be flowed from a source into a Hadoop environment. It employs a simple extensible data model that enables online analytic applications. As a result, we can use Flume to immediately load data from multiple servers into Hadoop.
Top 30 frequently asked Big Data Hadoop interview questions & answers for freshers & experienced
Ambari:
It is a management platform that is open source. It is a platform for setting up, managing, monitoring, and securing an Apache Hadoop cluster. Ambari provides a consistent, secure platform for operational control, making Hadoop management easier.
Advantages of ambari are:
- Simplified installation, configuration, and management – It can create and manage large-scale clusters quickly and easily.
- Ambari configures cluster security across the entire platform using a centralized security setup. It also reduces the administration's complexity.
- Ambari is fully configurable and extensible for bringing custom services under management.
- Full visibility into cluster health – Using a holistic approach to monitoring, Ambari ensures that the cluster is healthy and available.
Become a Hadoop Certified professional by learning this HKR Hadoop Hive Training !
ZooKeeper:
Zookeeper is a centralized service in Hadoop. It stores configuration information, handles naming, and offers distributed synchronization. It also has group services. Zookeeper is also in charge of managing and coordinating a large group of machines.
The benefits of zookeeper are:
- Fast – Zookeeper performs well in workloads where reads to data outnumber writes. The ideal read/write ratio is ten to one.
- Ordered – Zookeeper keeps a record of all transactions, which can be used for high-level reporting.
Oozie:
It is a system for managing Apache Hadoop jobs via a workflow scheduler. It sequentially combines multiple jobs into a single logical unit of work. As a result, the Oozie framework is fully integrated with the Apache Hadoop stack, with YARN serving as the architecture center. It also supports Apache MapReduce, Pig, Hive, and Sqoop jobs.
Oozie is both scalable and adaptable. Jobs can be easily started, stopped, suspended, and rerun. As a result, Oozie makes it very simple to rerun failed workflows. It is also possible to bypass a particular failed node.
There are two kinds of Oozie jobs:
- Oozie workflow is used to process and run workflows made up of Hadoop jobs such as MapReduce, Pig, and Hive.
- Oozie coordinator schedules and executes workflow jobs based on predefined schedules and data availability.
Conclusion:
Hadoop Ecosystem supports multiple components that contribute to its prominence. Several Hadoop job roles also are available as a result of these Hadoop components. I hope you found this Hadoop Ecosystem tutorial useful in comprehending the Hadoop family and their responsibilities. If you have any questions, please just leave them in the comment stream.
Related articles
About Author
Upcoming Hadoop Training Online classes
| Batch starts on 30th Jul 2026 |
|
||
| Batch starts on 3rd Aug 2026 |
|
||
| Batch starts on 7th Aug 2026 |
|