
Components of Hadoop
Last updated on Jan 22, 2024

- What is Hadoop
- Why Hadoop
- Key features of Hadoop
- Components of Hadoop
- Features of HDFS
- Hadoop MapReduce
- YARN components
- Conclusion
What is Hadoop?
As data generation grew over time, higher volumes and more formats appeared. To save time, multiple processors were needed to process data. However, due to the network overhead caused, a single storage unit became the bottleneck. As a result, each processor now has a distributed storage facility, which makes data access much simpler. Parallel processing with distributed storage is the term for this system, in which multiple computers run processes on different storages.
This article provides a comprehensive overview of Big Data problems, as well as what Hadoop is, what its components are, and how it can be used. Next, we'll look at the components of Hadoop to get a better understanding of what it is.
Become a Hadoop Certified professional by learning this HKR Hadoop Training
Why Hadoop?
It's quick to get Hadoop contagious. Its adoption in one organization may contribute to the adoption of similar practices in other organizations. Handling massive data seems to be much simpler today, thanks to this piece of technology's robustness and cost-effectiveness. Another great function is the ability to incorporate HIVE into an EMR workflow. It's extremely easy to start a cluster, install HIVE, and begin running basic SQL analytics in no time. Let's take a closer look at why Hadoop is so strong.
Key features of Hadoop
1. Flexible:
Since only 20% of data in enterprises is organized and the remaining is unstructured, managing unstructured data that goes unattended is critical. Hadoop is a software platform that handles various kinds of Big Data, whether structured or unstructured, encoded or formatted, or some other kind of data, and makes it usable for decision-making. Hadoop is also easy, appropriate, and schema-free! Though Hadoop is better known for supporting Java programming, the MapReduce technique allows any programming language to be used in Hadoop. Hadoop is better suited for Windows and Linux, but it can also run on BSD and OS X.
2. Scalable
Hadoop is a flexible framework in the sense that new nodes can be introduced to the system as required without having to change data formats, data loading practices, program writing methods, or even current applications. Hadoop is free and open-source software that runs on commodity hardware. Hadoop is also fault resistant, which ensures that if a node fails or goes out of operation, the machine will simply reallocate work to another place in the data and resume processing as if nothing has happened!
3. Building a more efficient data economy:
Hadoop has revolutionized big data mining and analysis all over the world. Until now, businesses have been concerned with how to handle the constant inflow of data into their applications. Hadoop is more akin to a "dam," collecting an infinite number of data and generating a great deal of power in the form of related data. Hadoop has fully altered the economics of data storage and analysis!
4. Robust Ecosystem:
Hadoop provides a rather versatile and rich environment that is well-tailored to developers, web start-ups, and other organizations’ computational needs. The Ecosystem is made up of several similar initiatives, including MapReduce, Hive, HBase, Zookeeper, HCatalog, and Apache Pig, which make it capable of delivering a wide range of services.
5. Hadoop is getting more “Real-Time”!
Have you ever wondered how to feed data into a cluster and test it in real-time? It's a problem for which Hadoop has a solution. Yes, skills are becoming more real-time. It also offers a standardized approach to a diverse range of big data analytics APIs, such as MapReduce, query languages, and database access, among others.
6. Cost-Effective:
With so many wonderful features, the icing on the cake is that Hadoop saves money by adding massively parallel processing to commodity servers, resulting in a significant decrease in the cost per terabyte of storage, making it possible to model all of your files. The basic concept here is to do cost-effective data analysis through the internet!
7. Upcoming Technologies using Hadoop:
Hadoop is contributing to phenomenal technological advances by bolstering its capability. HBase, for example, is quickly becoming a critical platform for Blob Stores (Binary Large Objects) and Lightweight OLTP (Online Transaction Processing). It's also been a stable basis for new-school graph and NoSQL databases, as well as enhanced relational databases.
8. Hadoop is getting cloudy!
Hadoop is becoming hazier! In reality, many companies are synchronizing with cloud storage to handle Big Data. Hadoop is going to be one of the most important cloud computing apps. The number of clusters provided by cloud providers in different industries shows this. As a result, it will soon be in the cloud!
Become a Big Data Hadoop Certified professional by learning this HKR Big Data Hadoop Training

Hadoop Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Components of Hadoop
Enterprise data is generating at an accelerated pace these days, and how we use it for a company's growth is critical. With its tremendous support for big data storage and analytics, Hadoop is hitting new heights. Companies all over the world began moving their data to Hadoop to join the early adopters of the technology and get the best out of their data.
Hadoop is a Big Data storage and management system that makes use of distributed storage and parallel processing. It is the most widely used program for dealing with large amounts of data. Hadoop is made up of three components.
- Hadoop HDFS - Hadoop's storage unit is the Hadoop Distributed File System (HDFS).
- Hadoop MapReduce - Hadoop MapReduce is the Hadoop processing unit.
- Hadoop YARN - Hadoop YARN is a Hadoop resource management unit.
Hadoop Common
As it functions as a channel or a SharePoint for all other Hadoop components, it is regarded as one of the Hadoop core components. Hadoop Common is a set of libraries and utilities that help other Hadoop modules work together. Consider the following scenario: To access HDFS, HBase or Hive must first use the Hadoop Common's Java archives (JAR files).
Hadoop HDFS
HDFS is Hadoop's default data storage, and data is saved there before it's required for processing. The data in HDFS is divided into several units called blocks and distributed throughout the cluster. It generates several replicas of data blocks and distributes them through clusters for consistent and convenient access.
Namenode, Data Node, and Secondary Name Node are the other three key components of HDFS. It employs a Master-Slave architecture paradigm. In this architecture, the Namenode serves as a master node to control the storage system, while the Data node serves as a slave node to manage the Hadoop cluster's various structures.
HDFS is a file system designed specifically for storing large datasets on commodity hardware. For the full processor, an enterprise version of a server costs about $10,000 per terabyte. If you need to purchase 100 of these enterprise-level servers, the cost would exceed a million dollars. Data nodes in Hadoop can be commodity devices. You won't have to spend millions on data nodes this way. The word node, on the other hand, has always been an enterprise server.
Features of HDFS
- Distributed storage is provided.
- It is possible to implement it on product hardware.
- Provides data protection.
- Highly fault-tolerant - if one system breaks down, the data from that machine is transferred to the next.
Master and Slave Nodes
HDFS is composed of master and slave nodes. The master is the name node, while the slaves are the data nodes.
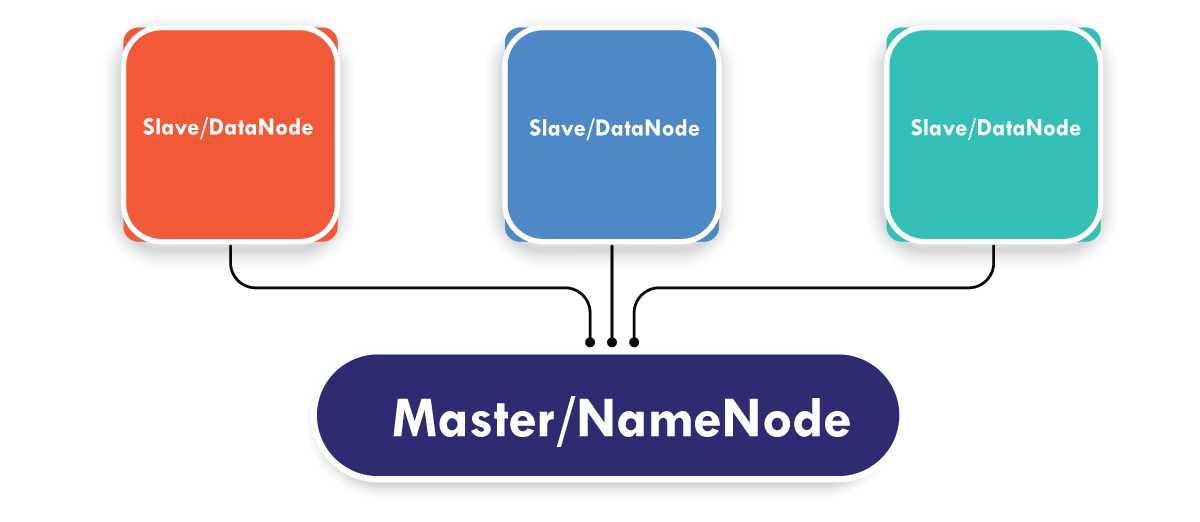
The name node is in charge of the data nodes' operations. It also keeps track of metadata.
The data nodes are responsible for reading, writing, processing, and replicating information. They often relay signals to the name node known as heartbeats. The data node's status is indicated by these heartbeats.

Consider the fact that the name node contains 30TB of data. This data is replicated among the data notes by the name node, which delivers it across the data nodes. The blue, grey and red data are replicated among the three data nodes, as seen in the image above.
By default, data replication takes place three times. This is achieved so that if a commodity machine breaks down, a new machine with the same data can be used to replace it.
In the next section of the What is Hadoop post, we'll concentrate on Hadoop MapReduce.
Get ahead in your career with our Hadoop Tutorial!
Subscribe to our YouTube channel to get new updates..!
Hadoop MapReduce
Hadoop MapReduce is the Hadoop processing unit. The processing takes place on the slave nodes, and the final output is sent to the master node in the MapReduce approach.
To handle all of the data, a data containing code is used. Concerning the raw data, this coded data is normally very small. To run a heavy-duty operation on computers, you only need to submit a few kilobytes of code.
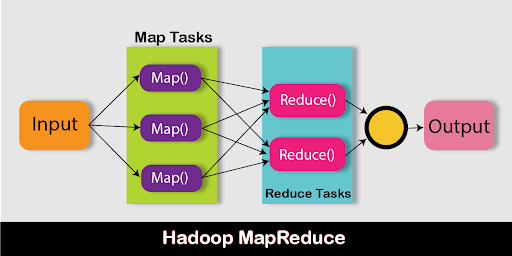
Apache Hadoop includes MapReduce as a key feature. It allows programmers to handle massive amounts of data while writing programs. MapReduce is a Java program that can process vast volumes of data. Its main function is to divide the data into small, separate bits that can be processed in parallel.
The MapReduce algorithm is made up of two main parts: Map and Reduce. When the Map function completes its mission, the Reduce function begins. The map takes a set of data and converts it into tuples. The Reduce function takes the Map function's output and combines it with another set of tuples to generate a new set of tuples. Hadoop relies heavily on MapReduce's parallel processing functionality. It enables big data processing to be performed on several computers in the same cluster.
Let's take a closer look at each feature.
Map Stage:
The input data is converted using the mapper tool. The data can be stored in HDFS in a variety of formats, such as folders or directories. The entire data set is sequentially transferred through the Map Function, which transforms it into tuples.
Reduce stage:
The data is shuffled and reduced to some extent at this point. It uses the Map function's output to perform the data processing function. It generates a new output after the reduced operation is completed, which is automatically stored in the Hadoop Distributed File System.
In this article, we'll focus on Hadoop YARN, which is the next concept we'll look at.
Hadoop YARN
The YARN's key concept is to separate the resource control and work scheduling functions into various daemons. YARN is responsible for allocating resources to the Hadoop cluster's various applications.
Resource manager and Node manager are the two key components of YARN. The data computation system is made up of these two components. The resource manager is in charge of delegating work to all applications in the system, while the node manager is in charge of containers and tracks their resource usage (CPU, disk, memory, and network) and sends the same information to the Resource manager.
Hadoop's YARN acronym stands for Yet Another Resource Negotiator. It is Hadoop's resource management unit, and it is used in Hadoop version 2 as a component.
Hadoop YARN serves as an operating system for Hadoop. It's a file system that uses HDFS as a foundation.
It's in charge of handling cluster resources to prevent overloading a single server.
It manages work schedules to ensure that jobs are planned in the right places.
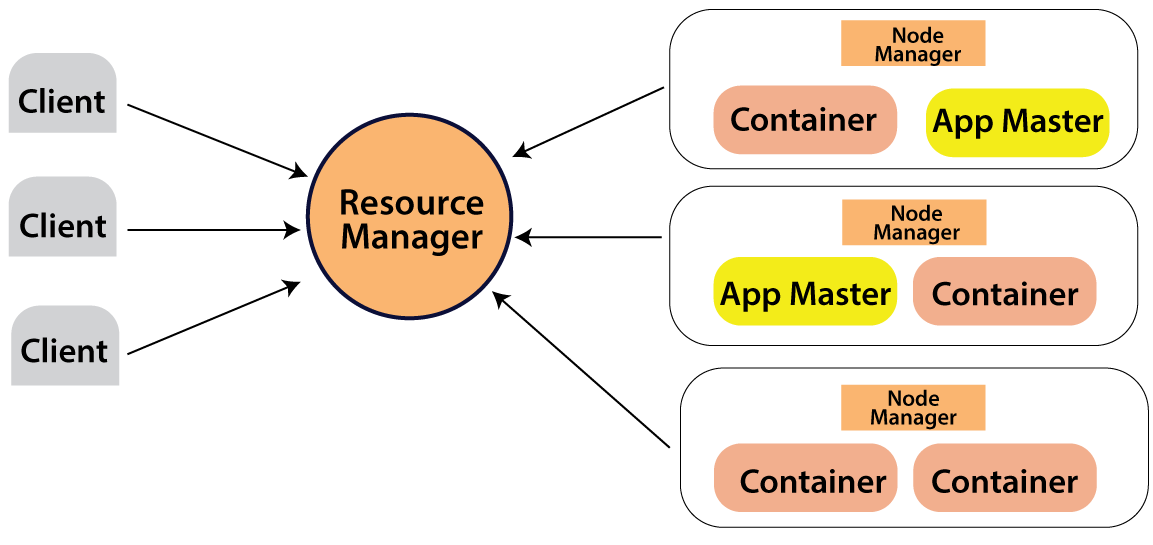
Assume a client computer requires the execution of a query or the retrieval of code for data processing. The resource manager (Hadoop Yarn), who is responsible for the resource allocation and management, receives this job request.
Each node has its node manager in the node section. These node managers are responsible for the nodes and keep track of their resource usage. Physical resources such as RAM, CPU, and hard drives are contained within the containers. The app master requests the container from the node manager whenever a job request is received. The resource is returned to the Resource Manager until the node manager has received it.
Top 30 frequently asked Big Data Hadoop interview questions & answers for freshers & experienced
YARN components : (Yet Another Resource Negotiator)
Hadoop YARN distributes work among its components and keeps them accountable for completing the task at hand. The tasks assigned to the various Core components of YARN are described below.
- A global Resource manager is in charge of accepting user work submissions and scheduling them by allocating resources.
- To the Resource manager, a Node manager is a Reporter. Each Node has a node manager who reports back to the Resource Manager on the functionality of each node.
- Each framework has its Application Master, which aids the Node Manager in executing and monitoring tasks and smoothing out the resource allocation process.
- The Resource container, which is operated by Node managers and distributed with the system resources allocated to individual applications, is another aspect of YARN.
Conclusion:
So far, we have focused on what Hadoop is, why Hadoop is necessary, and what are the various Hadoop components that make it up. Thus you have now learned the essential knowledge to understand different components of Hadoop that will assist you when you start working on Hadoop.
Related articles
About Author
Upcoming Hadoop Training Online classes
| Batch starts on 27th Jul 2026 |
|
||
| Batch starts on 31st Jul 2026 |
|
||
| Batch starts on 4th Aug 2026 |
|