
Azure Data Factory
Last updated on Jun 12, 2024


- Reviewed by
- Deeksha (Expert in Cloud Computing and Devops)
- What is Azure Data Factory?
- Purpose of using Azure Data Factory
- Scheduling Jobs and Orchestration
- Overview of components in Azure Data Factory
- What makes Azure Data Factory different from other ETL Tools?
- Working with Azure Data Factory
- Features in Azure Data Factory
- Working with other Azure resources
- Conclusion
What is Azure Data Factory?
Azure Data Factory (ADF) is a cloud integration system. The data can be moved between on-premises and cloud systems, scheduling and orchestrating data flows with the support of ADF. The platform of ADF is mostly based on Extract and Load Transform and Transform and Load rather than ETL (Extract Transform and Load) platforms. The following approaches are used in achieving the Extract and Load.
The data transfer between file systems and database systems which are located on-premises and on cloud is configured with simple ADF built-in features. Various databases such as SQL Server, Oracle, MySQL, DB2, Azure SQL Database, Azure Data Lake, blob storage, local file system and HDFS can be connected with ADF.
The SISS packages are initiated using ADF which can implement more sophisticated data movement and transformation tasks.
Purpose of using Azure Data Factory
These are the challenges which are faced by the Azure Data in moving data to or from the cloud. The below measures explains the purpose of using ADF.
Scheduling Jobs and Orchestration
The SQL Agent services like Azure scheduler and Azure automation will trigger the data integration tasks to move the data. The features like scheduling the jobs are also included in ADF. Event-based dataflows and dependencies are allowed in ADF.
We have the perfect professional Azure Solutions Architect Training course for you. Enroll now!
Scalability
Within a few hours, the large volume of gigabytes of data can be transferred into the cloud. ADF has features like build-in parallelism and time slicing which can handle large volumes of data.
Security
ADF ensures security by encrypting the data transit between on-premises and on cloud sources.
Less Coding
The ADF v2 provides an interactive interface which requires less coding in developing the components with the Azure portal and this is configured with JSON files.
Integration and delivery
ADF can integrate with GitHub to develop and deploy the build automatically into Azure. The entire configuration will be downloaded as Azure ARM Template and used to deploy ADF in other environments. The skilled PowerShell developers can able to create and deploy all the components of ADF.
Overview of components in Azure Data Factory
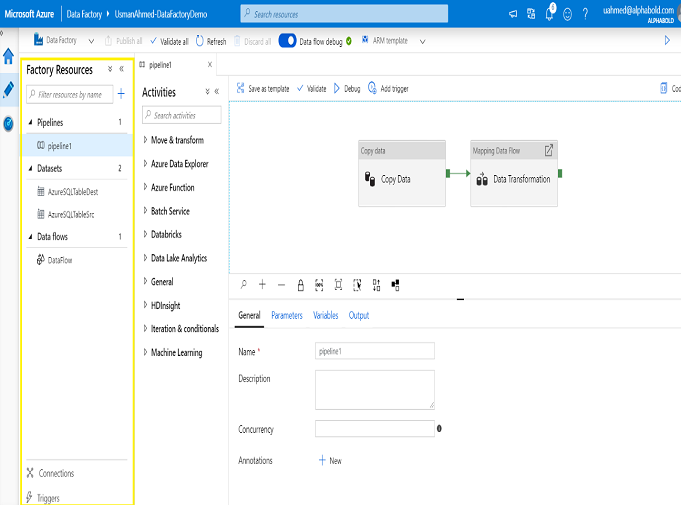
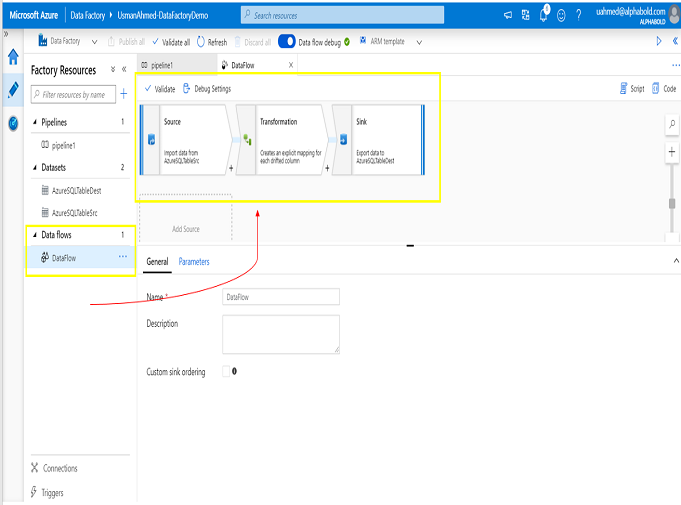
The following are the components in Azure Data Factory. To understand how ADF works it is important to know about the components of ADF. The below picture represents the ADF component resources comprising a pipeline, two datasets and one data flow.
1.Connectors
The connectors are the linked services that are configured with the settings for accessing certain data sources. The setting preferences include server/database name, file folder, credentials etc. Each data flow may have one or more linked services which are dependant on the job nature.
2.Datasets
The configuration settings for Dataset include table name, file name, structure etc. Each dataset is referred by a linked service which determines a list of possible dataset properties.
3.Activities
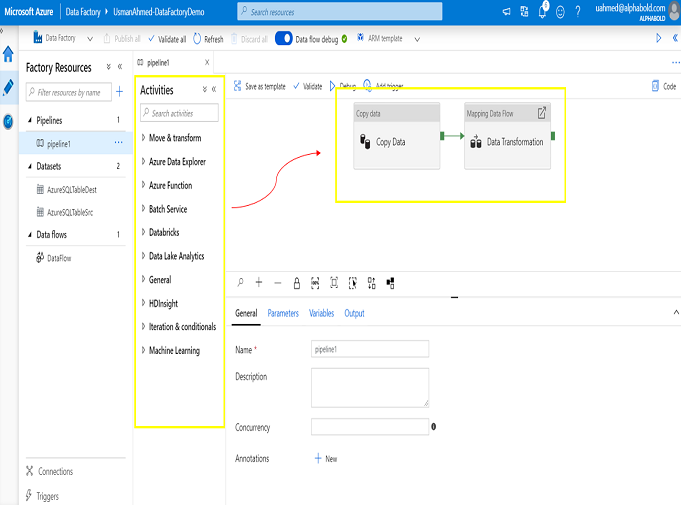
The activities are the actions which are performed like data movement, data transfer. The activity configurations settings include database query, stored procedure name, parameters, script locations etc.
4.Data flows
The data flows allows the data engineers to develop a transformation logic visually without writing code. These data flow activity types are executed in ADF Pipeline on Azure Databricks for scaled out processing using Spark. ADF handles large amounts of data by controlling the data flow execution and code translation.
Join our Azure Solutions (204) Training today and enhance your skills to new heights!

Microsoft Azure Certification Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
5.Pipelines
The logical group of activities are called pipelines. A data factory can have one or more pipelines and each pipeline may have one or more activities. The task scheduling and monitoring the multiple logical activities become easy with pipelines.
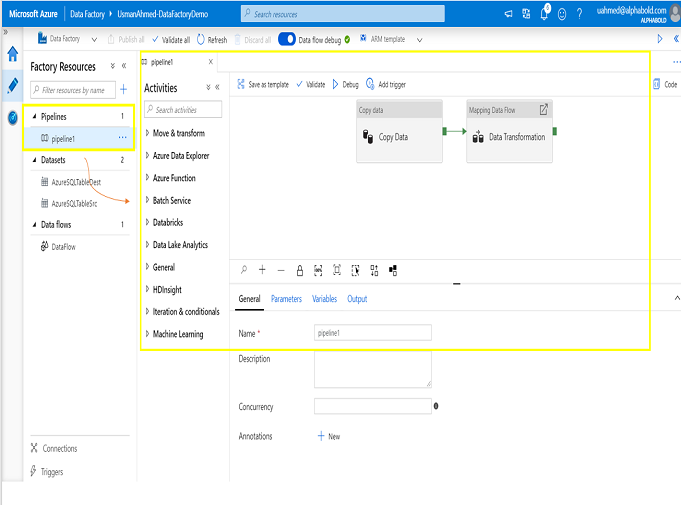
6.Triggers
Scheduling the configuration for pipelines are called triggers. The settings include start/end date, execution frequency etc.

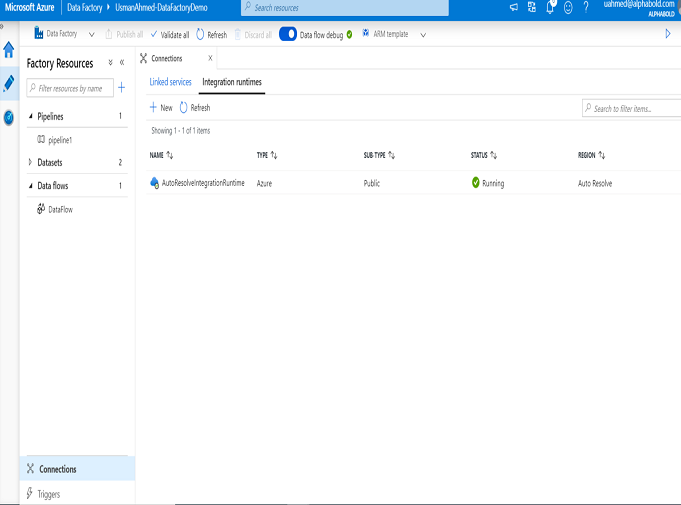
7.Integration runtime(IR)
ADF provides the data movement, compute capabilities across different network environments by running this integration service. It is a complete infrastructure made of below main runtime types.
Azure IR: It provides a fully managed serverless compute in Azure which handles the data moment activities in the cloud.
Self-hosted IR: The copy activities between a cloud data store and a data store in a private network along with transformation activities are managed by Self-hosted IR.
Azure SSIS IR: The SSIS packages are executed with Azure SSIS IR.
The below picture represents the overview of ADF and the relationship between different ADF entities of data set, activity, pipeline and linked services.
IMAGE
What makes Azure Data Factory different from other ETL Tools?
The features that distinguish in using ADF from other ETL tools are.
- Running SSIS packages.
- Fully managed PaaS product that auto-scales by given workload.
- Gateway to bridge on-premise and Azure cloud.
- Handling large data volumes.
- Connecting and working together with other computing services such as Azure Batch, HDInsights.
Want to Become a Master in Azure Data Factory? Then visit HKR to Learn Azure Data Factory Training!
Subscribe to our YouTube channel to get new updates..!
Working with Azure Data Factory
Working with Azure Data Factory is very easy and simple. The ADF is designed with GUI features which offer to create/manage the activities and pipelines by reducing the coding effort. Only the complex transformations require coding skills.
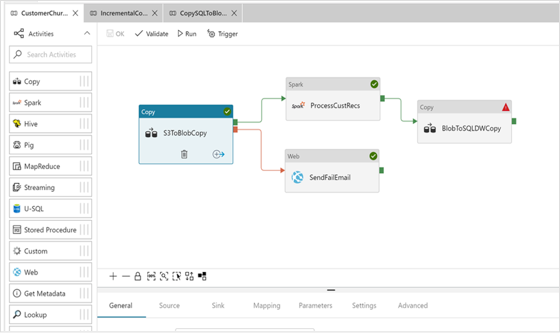
Features in Azure Data Factory
The ADF contains the default connectors with all data sources including MySQL, SQL Server, Oracle DBs.
- The branching feature support triggers the output of one activity to start another activity.
- The tumbling window trigger feature supports creating the partitioned data and an event trigger automatically triggers a transformation for an event.
- ADF enables the parameters dynamically between datasets, pipelines and triggers.
- ADF provides the monitoring and alerting feature which can monitor the execution of different pipelines and also can set up alerts during failures.
- ADF works well with Azure Databricks in scheduling the Machine Learning Algorithms.
Working with other Azure resources
The ADF integrates well with other Azure compute and storage resources with linked services that define the connection to the external resources. You can define two kinds of linked services.
Data Store service
This linked service provides the data storage services for Azure SQL Database, a Data Lake, Azure SQL Data-warehouse, a filesystem, an on-premises database, a NoSQL DB, etc.
Compute service
This service is used in transforming and enriching the data for Azure HDInsight, Azure Machine Learning, Stored Procedure in any SQL, U-SQL activity, Data Lake Analytics Azure Databricks and/or Azure Batch.
IMAGE
Conclusion
The Azure Data Factory is a very unique application which can transform and enrich the complex data. It is very easy to integrate the cloud with on-premises data. The delivery of integration services is scalable and available at low costs that can develop the data flow building blocks for any data platform and machine learning projects.
About Author
Upcoming Microsoft Azure Certification Training Online classes
| Batch starts on 22nd Jul 2026 |
|
||
| Batch starts on 26th Jul 2026 |
|
||
| Batch starts on 30th Jul 2026 |
|