
Hadoop Tutorial
Last updated on Nov 17, 2023

Hadoop Tutorial - Table of Content
- What is Hadoop
- Big Data Overview
- Hadoop Architecture Overview
- Hadoop installation guide
- Hadoop- HDFS overview
- Important components of YARN
- Conclusion
What is Hadoop?
Hadoop is an Apache product, and it is a collection of open-source software utilities that provide a network of many computer devices to solve complex problems that involve a massive amount of data and perform computations. It offers a storage framework to process the Big Data modules with the help of MapReduce programs.
This Hadoop also provides massive data storage for any data and vast data processing power. Also, it allows users to handle huge concurrent tasks or jobs. This Hadoop framework is written using coding languages like Java but never uses OLAP or online analytical processing. It is used for batch or offline data processing. Hadoop is used by major companies like Facebook, Yahoo, Google, LinkedIn, and many more to store a large volume of data.
Why learn Hadoop Tutorial?
You don't need any high-end degree or coding skills to start with Hadoop. It best fits middle and senior-level professionals who want to enhance their careers. Also, it is useful for experts like Architects, Programmers, and individuals with database skills. IT experts can also learn Hadoop skills in ETL, BI, testing, etc. Individuals from non-IT space can also begin with Hadoop Certification.
Hadoop Features
The following are the top features of Hadoop:
- Flexibility
- Reliability
- Scalability
- Cost-effective
- Fault-tolerant
Flexibility: Hadoop is highly flexible, as it deals with multiple data types.
Scalability: It is highly scalable as it can flawlessly integrate with many cloud services.
Reliability: Hadoop is very reliable software because when one system fails, another will take over its work.
Cost-effective: Hadoop is a cost-effective framework as it overcomes traditional DBs.
Fault-tolerant: It processes data much faster using DDP and cheap hardware systems to deal with failures.
Why use Hadoop?
The following are the few advantages of using Hadoop technology:
- One of the key benefits of using Hadoop is its cost-effectiveness compared to other traditional database technologies. It helps store and perform data calculations well.
- Hadoop can easily access different types of business solution data and has proven its decision-making benefits.
- This Hadoop also enables social media, log processing, data storage, emailing, and error detection.
- By mapping the data sets wherever they are placed, Hadoop technology minimizes the time to unfold any data sets. It can also work hourly on many petabytes of data, making it super-fast.
- Hadoop is flexible, agile, scalable, and highly adaptable with other languages.
Big Data Overview:
Now it’s time to learn about one of the popular Hadoop technologies, Big data.
New technologies, communication media, devices, networking sites, and data production have grown rapidly in the current tech market. The amount of data we produce every day is about 20 GB. So, it’s always good to process, integrate, transfer, and produce error-free data. To overcome this hustle, we now have Big Data technology.
Let’s begin with the definition:
What do you know about Big Data?
Big data is a collection of large data sets that traditional systems cannot process. It includes multiple tools, processes, methods, and data frameworks that make it a complete subject.
Big Data is composed of different devices and apps. The following are some major fields that come under the Big Data umbrella.
- Black box data: format is mainly used in helicopters, jets, and airplanes. This tool helps to capture the voices of the flight crews, recording information from microphones, performance information of the aircraft device, and earphones.
- Stock Exchange data: The stock exchange data format consists of information only about “Sell” and “buy.” Here, the decision is made on different companies' shares made by the customer.
- Social media data format: Social media platforms like Facebook and X contain information, and millions of people view the posts across the globe.
- Transport data format: The transport data comprises the model, distance, availability of the vehicle, and capacity information.
- Power grid data format: The power grid data consists of information that is consumed by a particular node with respect to base station methods.
- Search engine data format: The search engine helps to retrieve lots of data from multiple databases.
- Weather report data: Many weather reporting agencies and satellites provide large-size data stored and used for weather prediction.
- E-commerce data: Many top e-commerce companies, like Amazon, Myntra, Flipkart, etc., produce large-size data. It also helps trace users' buying behavior and trends.
Big data offers many benefits, such as huge data volume storage, high velocity, and a wide variety of data. These data can be divided into three different types:
1. Structured data – an example is Relational data.
2. Semi-structured data – an example is XML data.
3. Unstructured data – examples are Word, Text, Notepad, PDF, and media logs
Become a Hadoop Certified professional by learning this HKR Hadoop Training

Hadoop Administration Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Benefits of Big Data:
The following are the few benefits of big data:
1. Using information from social media networks like Facebook, marketing agencies are learning how to respond to their promotions, campaigns, and other advertising forums.
2. To plan their production, use the various information, such as social media preferences and product awareness of the respective customers, retail firms, and product companies.
3. Using the previous medical history, such as patients’ details, hospitals can offer better and quicker services.
Big Data Technologies:
Big Data technologies are essential in offering more accurate analysis, leading to decision-making. It also results in greater operational efficiency, cost-cutting, and risk reduction. There are various popular technologies, like Amazon, IBM, Microsoft, etc., to handle big data methods. Here, we are going to differentiate into two different classes:
1. Operational Big Data: In this section, systems like MongoDB offer real-time operational features, workloads, and interactives to capture and store the data. NoSQL's Big Data system is also designed to use cloud computing architecture and massive computations to run data economically and efficiently. This type of big data workload is much easier to manage, has faster implementations, and is cheaper.
2. Analytical Big Data: These include systems like MPP or massively parallel processing database systems and Map-reduce. They offer extensive analytical features and complex analysis reductions. In contrast, Map-reduce provides a new data analysis method supporting the SQL database's features.
Major Challenges of Big Data:
- Data capturing
- Storage
- Data curation
- Sharing of data
- Searching
- Analytical purpose
- Transfer a large volume of data
- Presentation techniques.
Big Data solutions:
The following are the essential approaches offered by Big Data solutions such as;
1. Traditional Approach:
In this traditional approach, an enterprise will have a computer to store and process the data. For storage purposes, the developer or programmer will take the help of their database vendors like Oracle, IBM, and PeopleSoft. In this approach, the user usually interacts with the device, which helps with data storage and analysis functions.
2. Google Solution:
Google solved problems like storing and processing data using an algorithm called MapReduce. It divides the multiple tasks into smaller tasks, assigns them to many computers, and collects the results. These results are integrated into result databases.
3. Hadoop Solution:
Doug Cutting and the team developed an open-source database project known as “HADOOP.” It is created using Google's solutions.
This Hadoop runs the applications using Map Reduce's algorithm; data is processed parallelly here. Hadoop is mainly used to develop various apps and helps to perform complete statistical analysis functions.
Hadoop Architecture Overview:
This section will explain the basic uses, components, and work nature.
The following diagram explains the architectural overview of Hadoop:
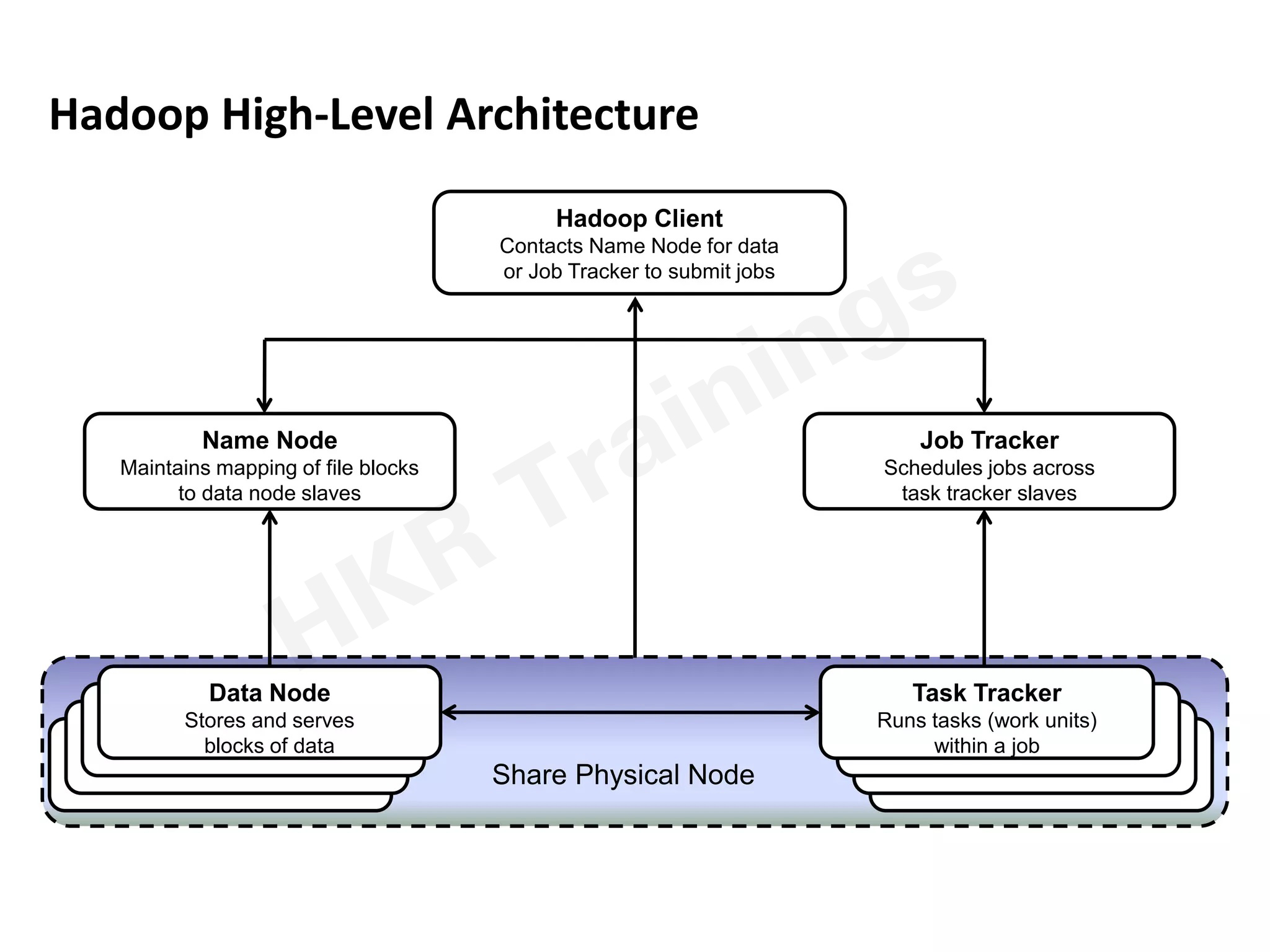
Hadoop elements available, and they play different roles in the architecture;
1. Hadoop distributed file system or HDFS – this is a type of pattern used in UNIX file systems.
2. Hadoop Map reduces components.
3. Resource negotiator or YARN (Yet another resource negotiator).
When you start to learn about Hadoop architecture, every layer of this architecture requires knowledge to understand its various components. These components perform operations like designing the Hadoop cluster, performance tuning, and chain responsible for data processing. As I said earlier, it follows a master-slave architecture design containing a master node or name node, where the master node is used for parallel data processing using a job tracker.
Hadoop installation guide:
Follow the steps that are used to install 2.4.1 in pseudo-distributed mode.
Step 1: Setting up of Hadoop environment
Here, you can start the Hadoop environment variable with the help of appending commands stored in the ~/.bashrc file.
Step 2: Get all Hadoop configuration files in the location: “$HADOOP_HOME/ETC/Hadoop.” This file requires making any changes in the configuration files according to the Hadoop infrastructure:
$ cd $ HADOOP_HOME /etc/Hadoop //Hadoop home page
To develop any program in JAVA, you first have to reset the Java environment variables stored in Hadoop-env. sh, file just by replacing the JAVA_HOME value.
export JAVA_HOME = /usr/local/jdk1.7.0_71.
Some of the essential XML files will be used while installing Hadoop:
1. Yarn-site.xml
This file system is used to configure the Yarn into the Hadoop environment. First, you need to open the yarn with -site.xml file and add the properties like tags.
2. Mapred-site.xml:
This file system is used to specify the Map-reduce framework. By default, we use Hadoop, which contains a template of yarn-site.xml. First, it is necessary to copy the file from map red site.xml. Template to mapred.site.xml files with the help of the following command.
$ cp mapred-site.xml. Template mapred-site.xml.
Verifying Hadoop installation:
The following are the steps required to verify the Hadoop installation:
1. Name node setup:
Set up the name node using the below commands in “hdfs namenode –format” as follows:
$ cd ~
$ hdfs namenode –format
2. Verifying the Hadoop dfs:
The following are the commands used to get started with DFS. Execute the below command to start the Hadoop file system:
$ Start –dfs. sh
3. Verifying the yarn script:
The following command is used to start the yarn script. Execute the following command to start YARN daemons.
$ Start –a yarn. sh
4. Accessing Hadoop on the browser:
To access any Hadoop system, the default port number is 50070. You need to use the following URL to work with the Hadoop service.
http: //localhost: 50070/

5. Verify all the applications for the cluster:
Here, the default port number used to access all kinds of apps is 8088. You should use the following URL to visit the service:
Subscribe to our YouTube channel to get new updates..!
Hadoop- HDFS overview:
Hadoop file systems are specially developed using a distributed file system management design. It is usually run on commodity hardware. HDFS module is a highly fault-tolerant and low-cost hardware design. HDFS consists of a large volume of data and offers easier data access. To store big-size data, the files are used to store these data files across multiple machines. The HDFS file is usually stored in a redundant system to overcome possible data losses and reduce failure. HDFS also makes any application available for parallel processing.
Important features of HDFS:
The following are the essential features of HDFS namely:
1. HDFS is suitable for distributed data processing and storage management.
2. Hadoop HDFS also provides a command interface that mainly connects with multiple systems.
3. The built-in servers, such as name and data nodes, help users check the cluster status quickly.
4. Offers data streaming to access various file system data.
5. The HDFS module offers mechanisms like file permission and authentication services.
Goals of the HDFS module:
The following are the essential goals of the HDFS module:
1. Helps in fault detection and recovery: The HDFS module consists of many commodity hardware resources and elements that have failed. So, HDFS should support various mechanisms for quick defect recovery and automatic fault detection.
2. Helps to store massive data sets: HDFS consists of hundreds of node clusters mainly used to manage the application database that holds vast data sets.
3. Offers hardware capabilities at data: A requested task will be done efficiently only during computational tasks. It happens especially when large volumes of data sets are used; this reduces the network data traffic and increases it throughout the process.
Essential operations of HDFS:
The following are the major operations of the HDFS module:
1. Starting with HDFS:
It is an initial stage, where you need to format the configured file system (HDFS file types), open name node cluster or HDFS server, and execute the below command:
$ Hadoop name node - format
This command formats the HDFS cluster node and will start the distributed file system. The following command will start the name node in the cluster;
$ start – dfs. Sh
2. List the files in HDFS:
This step will occur once you load the information into the server system; after this, you can find the list of files in a record or directory and a file status using “ls.” The following syntax helps to pass the data to a directory or a file name in the argument.
$ $ HADOOP _ HOME /bin/hadoop fs -ls
3. Inserting the data into HDFS:
Consider that we have data in the file system called file.txt in the local system directory and we only save the HDFS file system. The following are the important commands used to perform these operations:
$ $HADOOP _ HOME /bin/Hadoop fs -mkdir /user/input
Now, we will transfer and store data files from the local systems to the HADOOP file systems by using the below command;
$ $ HADOOP_HOME / bin/Hadoop fs –put /home /file.txt /user/input
To verify the file systems, use the command:
$ $HADOOP_HOME /bin/hadoop fs –ls /user/input
4. Retrieving of data from HDFS:
Usually, a file in HDFS is called outfile. Below are the simple commands used to perform the operations in the Hadoop file system.
Firstly, view the data from HDFS by using the cat command:
$ $HADOOP _HOME /bin/ hadoop fs –cat /user/output/outfile
Now gets the file from HDFS to the local file system using the “get” command
$ $HADOOP _HOME /bin/hadoop fs –get/ user/output / / home /hadoop_tp/
5. Shutting down the HDFS file system:
With the help of the below command, you can shut down the file system:
$ Stop-dfs.sh
YARN
YARN is another resource manager that helps take the coding to the next level and makes this programming app interact with other apps, such as Hbase, SPARK, etc. Another important point to look into is that different YARN apps can exist on the same cluster; for example, Map Reduce, Hbase, and Spark run parallel to offer compliance and clustering usage benefits.
Important components of YARN:
1. Client: This component is used to submit the Map-reduce jobs.
2. Resource manager: this component manages the resources across the cluster.
3. Node manager: used for launching and monitoring the computer containers on various machines in the cluster.
4. Map Reduce application master component: this will check the tasks running the Map-reduce job. The application master and the Map-reduce tasks will run in containers scheduled by the resource manager and managed by node managers.
The previous Hadoop version used a job and task tracker to handle resources and check progress management. The latest version of Hadoop 2.0 consists of a resource manager and a node manager to overcome the shortfalls of the job and task tracker components.
Benefits of YARN:
The following are the crucial benefits of YARN:
1. Offers high-level scalability: Map-reduce 1.0 offers scalability consisting of 4K nodes and 40000 tasks, but here, YARN is designed for 10K nodes and 1 lakh major tasks.
2. Better Utilization: Here, the node manager helps to manage a pool of hardware resources, other than fixing the number of designated tools, so this increases the utilization.
3. Multitenancy: Different versions of Map-Reduce will run on YARN, making the upgrading process of Map-Reduce difficult.
Hadoop – command references:
Many commands are available in Hadoop, located in the “$HADOOP_HOME/bin/hadoop fs” file. Running this command will list all the commands with no extra arguments, and all these arguments will be stored in the Fs Shell system.
Below are a few essential commands and their descriptions:
1. –ls = This command will list all the contents of the directory, which is specified by path, names, owner, size, permissions, and modified date for each individual entry.
2. –lsr = This command behaves like the –ls command and displays the entries in all sub-directories of the path.
3. –du = It offers disk usage in terms of bytes, consisting of a path, and the file name is reported with the HDFS protocol prefix.
4. –dus = This command will print the summary of the total disk usage of all file types and directories in the path.
5. –mv = This command helps move the file or directory, indicated by using src or dest in HDFS.
6. –cp = This command copies the file or directory specified by src to the destination.
7. –rm = This command removes the file or directory specified by the path. It will also help to delete the child entries.
8. –put = This command will copy the file or directory from the local file system, identified by local src, to a destination within the DFS.
9. –movefromlocal = This copies the file or directory from the local file system specified by localsrc to dest within the HDFS and deletes the local copy files.
10. –get [-crc] = This command is used to copy the file or directory in the HDFS module specified by src file to the local file system by localDest.
Hadoop – MapReduce:
MapReduce is just like the processing of techniques and programming models used for distributed computing based on the Java programming environment. Here, the Map-reduce algorithm consists of two vital tasks: mapping and reducing the data set and converting it into another data set. The elements are broken down into tuples or (Key/value pairs).
The major advantage of Map Reduce is that it offers easy-to-scale data processing using multiple computing nodes. Under this Map Reduce model, the data processing data primitives are called mapping and reducing. The simple scalability attracts many programmers to make use of the MapReduce model.
The Map-Reduce Algorithm:
The following are the key points of the Map-Reduce algorithm:
1. The Map-Reduce algorithm is developed based on sending the computer to where the data sets reside.
2. This algorithm can generally be divided into three stages: map stage, reduce stage, and shuffle stage.
3. During the Map-reduce job, the Hadoop program sends both maps and reduces the tasks to the relevant cluster.
4. Here, the framework manages all the relevant data processing details, such as issuing tasks, validating task completion, and copying data around the node cluster.
5. Most of the computing performance occurs on the data nodes located on the local disk, which will reduce the networking traffic.
6. Once you finish the given tasks, the server on the cluster node collects and reduces the data to form an appropriate result and sends it back to the Hadoop server.
The following diagram explains the Map Reduce Algorithm:
Become a master of Big Data Hadoop through this HKR Big Data Hadoop Training!
Map Reduce Algorithm Terminology:
1. Payload: These apps implement both the reduce and map functions and form the core of the Hadoop job.
2. Mapper: It maps the input key-value pairs to set the intermediate type of key-value pair.
3. Named Node: this node manages the HDFS or Hadoop distributed file system.
4. Data Node: This node processes the tasks where data is displayed in advance.
5. Master Node: This is the node where the Job tracker runs and accepts the job requests from respective clients.
6. Slave Node: This node helps to run Map and reduce programs.
7. Job tracker: This schedules the job and tracks to assign the relevant job to the task tracker.
8. Job: Job is a program that executes the mapper and reducer datasets across the cluster node.
9. Task: A task executes a mapper or reducer in a slice of data sets.
10. Task attempt: A particular instance helps to attempt the execution of a given task on a slave node.
Additionally, you can explore the Pig and Hive components of Hadoop.
Pig
Here, we will discuss Pig, a leading scripting and high-level data flow platform. It helps process and analyze big data sets. It can store the outcomes in HDFS using structured and unstructured data to get usable insights. It has two key elements: Pig Latin language and Runtime engine. These elements help to analyze and process Map-reduce programs. Pig works in different stages, covering data loading, scripting, operations, and plan execution.
Hive
In the Hadoop Tutorial, Hive is a data warehouse that uses HiveQL, a querying language via distributed databases. Hive mainly offers functionality to read, write, and handle big datasets. It supports DML and DDL languages. It has two data types: Primitive data types and Complex data types. The former includes string, numeric, date & time data types, and the latter covers maps, units, arrays, etc. data types. Further, it runs HiveQL language that internally converts into Map-reduce tasks.
Top 30 frequently asked Big Data Hadoop interview questions & answers for freshers & experienced
Conclusion:
We hope you enjoyed this Hadoop tutorial. Big data is a popular product developed with the help of Hadoop technology. Hadoop big data learning helps to get proper and error-free data. As per the latest research, we produce almost 20 GB of data daily. So, it’s always good to process the data to get accurate data sets. From this Hadoop tutorial, you will be able to learn map-reduce, Hive, YARN, Big Data, and algorithms that will make you an expert in the platform. You can expect huge job openings for Big Data analysts across the globe.
Related Articles:
About Author
Upcoming Hadoop Administration Training Online classes
| Batch starts on 5th Aug 2026 |
|
||
| Batch starts on 9th Aug 2026 |
|
||
| Batch starts on 13th Aug 2026 |
|