
Pyspark Tutorial
Last updated on Nov 07, 2023

What is Pyspark?
PySpark is a Spark library written in Python to run the Python application using the functionality of Apache Spark. Using PySpark, we can run applications parallel to the distributed cluster.
In other words, PySpark is an Apache Spark Python API. Apache Spark is an analytical computing engine for large-scale, powerfully distributed data processing and machine learning applications.
Spark basically built in Scala and later due to its industry adaptation, the PySpark API released for Python using Py4J. Py4J is a Java library that is embedded into PySpark and allows Python to dynamically communicate with JVM objects, so running PySpark would also require Java to be installed along with Python and Apache Spark.
In comparison, for development, you can use the Anaconda distribution (widely used in the Machine Learning community) which comes with a number of useful tools, such as Spyder IDE, Jupyter Notebook, to run PySpark applications.
In real time, PySpark has made a great deal of use in the Machine Learning & Data Science environment, thanks to a huge python machine learning library. Spark performs billions and trillions of data on distributed clusters 100 times faster than standard python applications.
Who uses Pyspark?
PySpark seems to be well used within the Data Science and Machine Learning community, as there are many commonly used data science libraries written in Python, including NumPy, and TensorFlow is often used for efficient processing of large datasets. PySpark has been used by many companies such as Walmart, Trivago, Sanofi, Runtastic, and many others.
Features:
The features of the pyspark are:
- In-memory computation
- Distributed processing using parallelize
- Can be used with many cluster managers (Spark, Yarn, Mesos e.t.c)
- Fault-tolerant
- Immutable
- Lazy evaluation
- Cache & persistence
- Inbuild-optimization when using DataFrames
- Supports ANSI SQL
Advantages of pyspark:
Some of the advantages of the pyspark are:
- PySpark is a purpose built, in-memory, distributed processing engine that allows you to process data efficiently in a distributed way.
- Applications running on PySpark are 100x faster than conventional systems.
- You will benefit greatly from using PySpark for data ingestion pipelines.
- We can process data from Hadoop HDFS, AWS S3, and many file systems using PySpark.
- PySpark is also used to access data in real time using Streaming and Kafka.
- You can also stream files from the file system and also stream files from the socket using PySpark streaming.
- PySpark wirelessly has machine learning and graphics libraries.
Take your career to next level in PySpark with HKR. Enroll now to get PySpark Training !
Pyspark Architecture:
Apache Spark operates in a master-slave architecture where the master is appointed "driver" and slaves are called "workers." If you run a Spark programme, Spark Driver provides a context that is a point of entry for your application, and all activities are performed on worker nodes, and the resources are handled by the Cluster Manager.
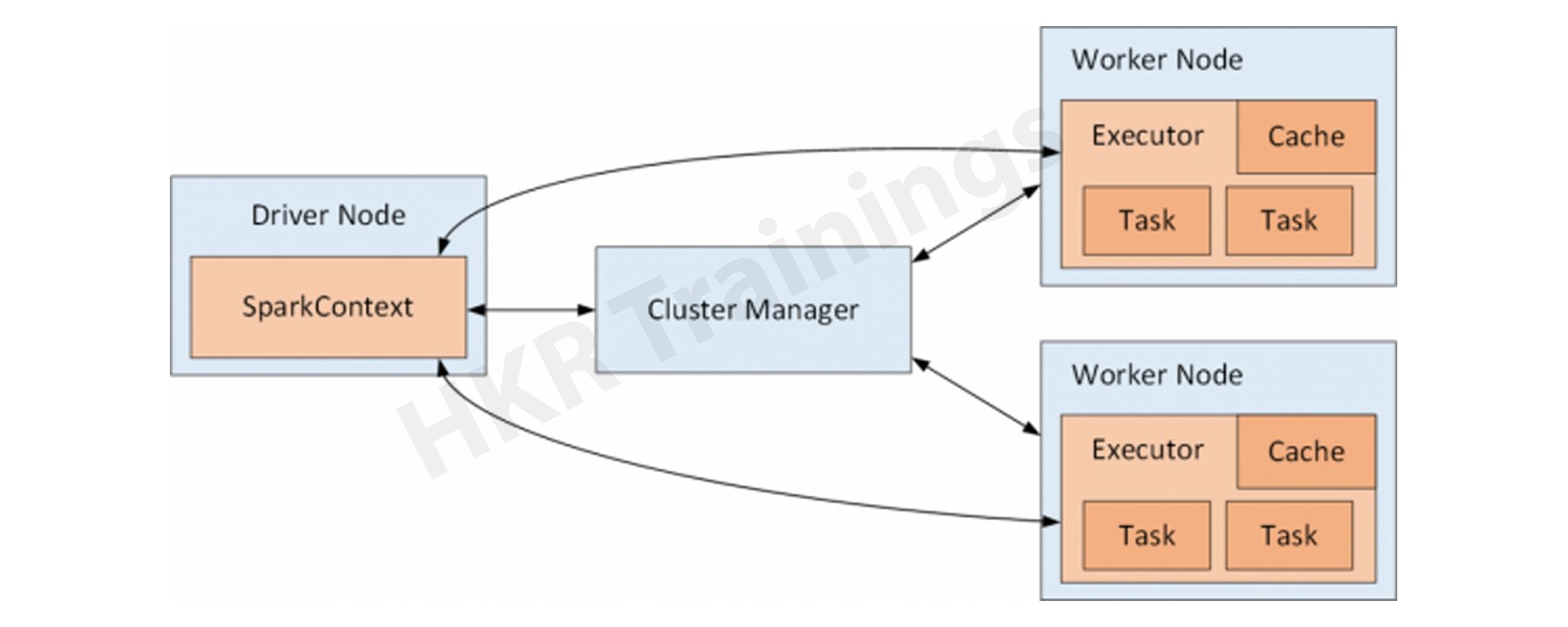
Cluster Manager Types:
Spark supports the following cluster managers:
- Standalone – a basic cluster manager with Spark that makes it easy to set up a cluster.
- Apache Mesos – Mesons is a cluster manager that can run Hadoop MapReduce and Spark applications as well.
- Hadoop YARN – the Hadoop 2 resource manager. This is often used by the cluster manager.
- Kubernetes – an open-source framework for optimising the deployment, scale and maintenance of containerized applications.
- Local – which is not really a cluster manager, but I still wanted to note that we use "local" for master() to run Spark on your laptop/computer.
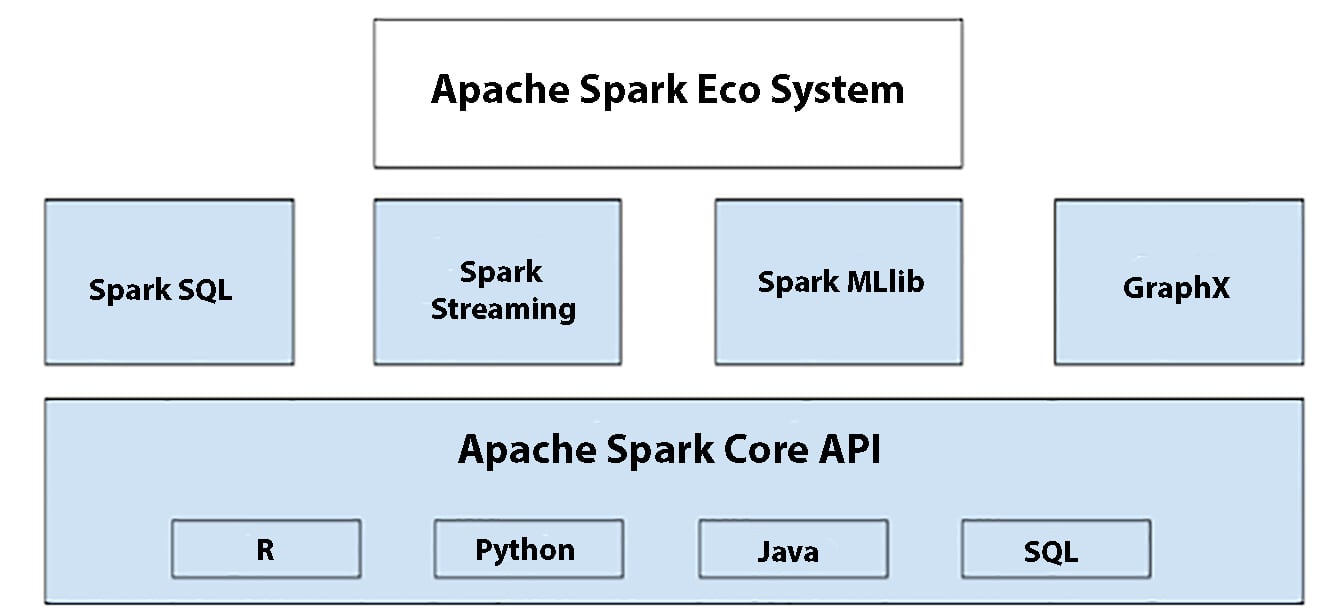
Pyspark Modules and Packages
The pyspark modules and packages are as follows:
- RDD of PySpark
- DataFrame and SQL PySpark (pyspark.sql)
- Streaming of the Pyspark (pyspark.streaming)
- MLib Pyspark (pyspark.ml, pyspark.mllib)
- GraphFrames of PySpark (GraphFrames)
- PySpark Resource (pyspark.resource) is new to PySpark 3.0.
The apache spark ecosystem and you can find the third party libraries at https://spark-packages.org/.
Pyspark Installation:
In order to run the PySpark examples listed in this tutorial, you need to have Python, Spark and the tools you need to instal on your computer. Since most developers are using Windows for development, I'll explain how to instal PySpark on windows.
Installing python:
Download and instal Python from Python.org or Anaconda, which includes Python, Spyder IDE, and Jupyter notebook. I would suggest using Anaconda as common and used by the Machine Learning & Data Science community.
Installing java 8:
To run the PySpark programme, you will need Java 8 or later, so download the Java version from Oracle and instal it on your device.
Post installation, set the JAVA_HOME and PATH variables. You need to set java_home and path variables as follows:
JAVA_HOME = C:\Program Files\Java\jdk1.8.0_201
PATH = %PATH%;C:\Program Files\Java\jdk1.8.0_201\bin
Installing Apache Spark:
Download Apache spark by clicking on the Spark Download page and pick the connection under "Download Spark (point 3)." If you want to use a different version of Spark & Hadoop, pick the one you want from the drop-down menu and change the link on point 3 to the selected version and provide you with a modified download link.
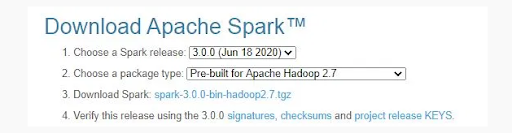
After downloading, untar the binary using 7zip and copy the underlying folder spark-3.0.0-bin-hadoop2.7 to c:\apps.
Set the following environment variables now.
SPARK_HOME = C:\apps\spark-3.0.0-bin-hadoop2.7
HADOOP_HOME = C:\apps\spark-3.0.0-bin-hadoop2.7
PATH=%PATH%;C:\apps\spark-3.0.0-bin-hadoop2.7\bin
Setup Winutiles.exe:
Download the wunutils.exe file from the winutils and copy it to the SPARK HOME percent \bin folder. Winutils are different with each version of Hadoop, so download the correct version from https:/github.com/steveloughran/winutils.
Pyspark Shell:
Now open the prompt and enter the pyspark command to run the Pyspark shell. You're going to see something like below.
Spark-shell also produces a Spark web UI, which can be accessed from http:/localhost:4041 by default.

PySpark Training Certification
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Spark Web UI
Apache Spark offers a suite of Web UIs (Jobs, Stages, Tasks, Storage, Environment, Executors, and SQL) to monitor the status of your Spark programme, Spark cluster resource usage, and Spark configuration. You can see how the operations are performed on the Spark Web UI.
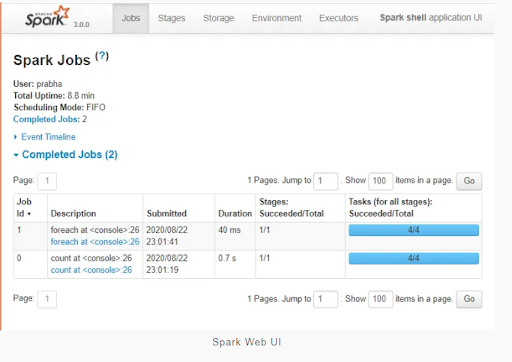
Spark History Server:
Spark History servers hold a log of all Spark applications you send by spark-submit, spark-shell. You first need to set the configuration below to spark-defaults.conf before you start.
spark.eventLog.enabled true
spark.history.fs.logDirectory file:///c:/logs/path
Now, start the Linux or Mac Spark History Server by running
$SPARK_HOME/sbin/start-history-server.sh
If you are running Spark on windows, you can start the history server by starting the command below.
$SPARK_HOME/bin/spark-class.cmd org.apache.spark.deploy.history.HistoryServer
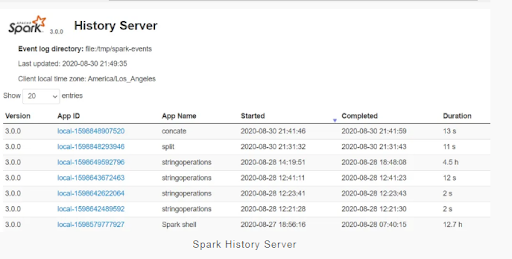
By clicking on each app ID, you can find the application information in the PySpark web UI.
Spyder IDE and Jupyter Notebook
You will need an IDE to write PySpark applications, there are 10 IDEs to work with and I prefer to use Spyder IDE and Jupyter notebook. If you have not installed Spyder IDE and Jupyter Notebook along with Anaconda Distribution, update them before continuing.
Set the following environment variable now.
PYTHONPATH =>% SPARK HOME%/python;$SPARK HOME/python/lib/py4j-0.10.9-src.zip;% PYTHONPATH%
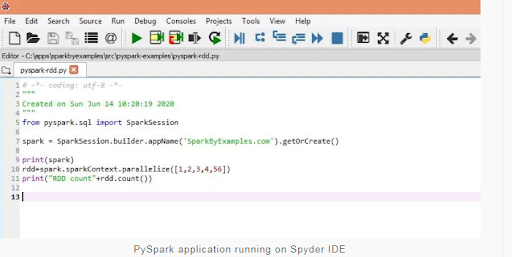
Now open the Spyder IDE and build a new file with a simple PySpark program below and run it. You're expected to see 5 in production.
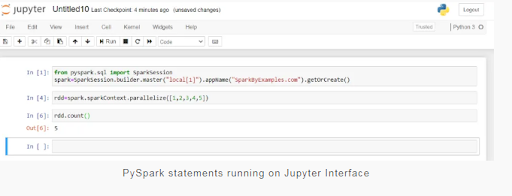
Now let’s start the Jupyter Notebook
Pyspark RDD-Resilient Distributed Dataset:
In this section of the PySpark tutorial, I will present the RDD and explain how to construct it and use its transformation and action operations with examples.
PySpark RDD (Resilient Distributed Dataset) is a basic data structure of PySpark that is defect, persistent, distributed object collection, which means that after you create an RDD, you cannot modify it. Each dataset in the RDD is divided into logical partitions that can be computed on different cluster nodes.
RDD Creation:
To build an RDD, first you need to create a SparkSession that is an entry point for the PySpark application. SparkSession can be built using the SparkSession builder() or newSession() methods.
Spark session internally generates a SparkContext variable. You can create multiple SparkSession items, but only one SparkContext per JVM. If you want to create another new SparkContext, you can avoid using the current Sparkcontext before creating a new one.
spark=SparkSession.builder()
master("local[1]")
.appName ("SparkByExamplescom") ("SparkByExamples.com")
-getOrCreate () ()
Using parallelize()
SparkContext has a variety of functions to use with RDDs. For example, the parallelize() method is used to construct an RDD from a list.
#Create RDD from parallelize
dataList = [("Java", 20000), ("Python", 100000), ("Scala", 3000)]
rdd=spark.sparkContext.parallelize(dataList)
Using text file()
You can also construct RDD from a text file using the SparkContext textfile() feature.
//Create RDD from external Data source
rdd2 = spark.sparkContext.textFile("/path/textFile.txt")
You can conduct transformation and intervention operations once you have an RDD. Any operation you perform on the RDD will run in parallel.
RDD Operations:
You may conduct two kinds of operations on PySpark RDD.
- RDD Transformation – Transformation is a lazy operation. When you run a transformation (e.g. update) instead of modifying the current RDD, these operations return another RDD.
- RDD behaviour – operations that trigger computing and return RDD values to the driver.
RDD Transformations:
Transformations on Spark RDD returns another RDD, and transformations are lazy meaning they don't run until you call an action on RDD. Some RDD transformations are flatMap(), map(), reduceByKey(), philtre(), sortByKey() and return a new RDD instead of updating the existing one.
RDD Actions:
RDD Behavior Returns the values from the RDD to the driver node. In other words, every RDD function that returns non-RDD[T] is considered to be an action.
Some RDD acts are count(), collect(), first(), max(), reduce() and more.
Pyspark DataFrame:
DataFrame description is really well defined by Databricks, so I don't want to describe it again and confuse you. Below is the concept I've taken from Databricks.
If you're coming from a Python context, I guess you already know what Pandas DataFrame is; PySpark DataFrame is mostly identical to Pandas DataFrame, with the exception that PySpark DataFrames are distributed in clusters (meaning that data in DataFrame is stored in different cluster machines) and any PySpark operations run parallel on all machines, while Panda Dataframe stores.
If you don't have a Python history, I would recommend that you learn some basics about Python before continuing with this Spark tutorial. For now just know that PySpark DataFrame data is stored in various cluster machines.
DataFrame Creation:
The best way to build a DataFrame is from the Python Data List. DataFrame can also be built from an RDD and by reading files from a variety of sources.
Using the createDataFrame()
You can create a DataFrame by using the createDataFrame() feature of the SparkSession.
data = [('James','','Smith','1991-04-01','M',3000),
('Michael','Rose','','2000-05-19','M',4000),
('Robert','','Williams','1978-09-05','M',4000),
('Maria','Anne','Jones','1967-12-01','F',4000),
('Jen','Mary','Brown','1980-02-17','F',-1)
]
columns = ["firstname","middlename","lastname","dob","gender","salary"]
df = spark.createDataFrame(data=data, schema = columns)
Since DataFrame is a structure format that contains names and columns, we can use df.printSchema to get the dataFrame schema ()
data = [('James','','Smith','1991-04-01','M',3000),
('Michael','Rose','','2000-05-19','M',4000),
('Robert','','Williams','1978-09-05','M',4000),
('Maria','Anne','Jones','1967-12-01','F',4000),
('Jen','Mary','Brown','1980-02-17','F',-1)
]
columns = ["firstname","middlename","lastname","dob","gender","salary"]
df = spark.createDataFrame(data=data, schema = columns)
df.show() shows the 20 elements from the DataFrame.
DataFrame Operations:
Like RDD, DataFrame also has operations such as Transformations and Behavior.
DataFrame from external sources:
In real-time applications, DataFrame is generated from external sources such as local system files, HDFS, S3 Azure, HBase, MySQL table e.t.c. Below is an example of how to read a csv file from a local system.
df = spark.read.csv("/tmp/resources/zipcodes.csv")
df.print scheme ()
The DataFrame supported file formats are: csv, text, Avro, Parquet, tsv, xml and many more.
Top 30 frequently asked PySpark Interview Questions !
Subscribe to our YouTube channel to get new updates..!
Pyspark SQL:
PySpark SQL is one of the most common PySpark modules used for the processing of structured columnar data formats. Once a DataFrame has been developed, you can interact with the data using SQL syntax.
In other words, Spark SQL brings native RAW SQL queries to Spark meaning that you can run conventional ANSI SQL queries on Spark Dataframe, and in the later section of this PySpark SQL tutorial you can learn information using SQL select, where, group by, join, union e.t.c.
To use SQL, first create a temporary DataFrame table using the createOrReplaceTempView() function. Once developed, this table can be accessed in the SparkSession using sql() and will be dropped along with your SparkContext termination.
Use the sql() method of the SparkSession object to run the query and return a new DataFrame.
df.createOrReplaceTempView("PERSON_DATA")
df2 = spark.sql("SELECT * from PERSON_DATA")
df2.printSchema()
df2.show()
Let’s see another pyspark example using group by.
groupDF = spark.sql("SELECT gender, count(*) from PERSON_DATA group by gender")
groupDF.show()
This yields the below output
Output:gender|count(1)|
+------+--------+
| F| 2|
| M| 3|
You can also run some typical SQL queries on DataFrame using PySpark SQL.
Pyspark Streaming:
PySpark Streaming is a scalable high-throughput, fault-tolerant streaming framework that supports both batch and streaming workloads. It is used to process real-time data from sources such as the file system folder, TCP socket, S3, Kafka, Flume, Twitter, and Amazon Kinesis, to name a few. The processed data can be moved to databases, Kafka, live dashboards, etc.
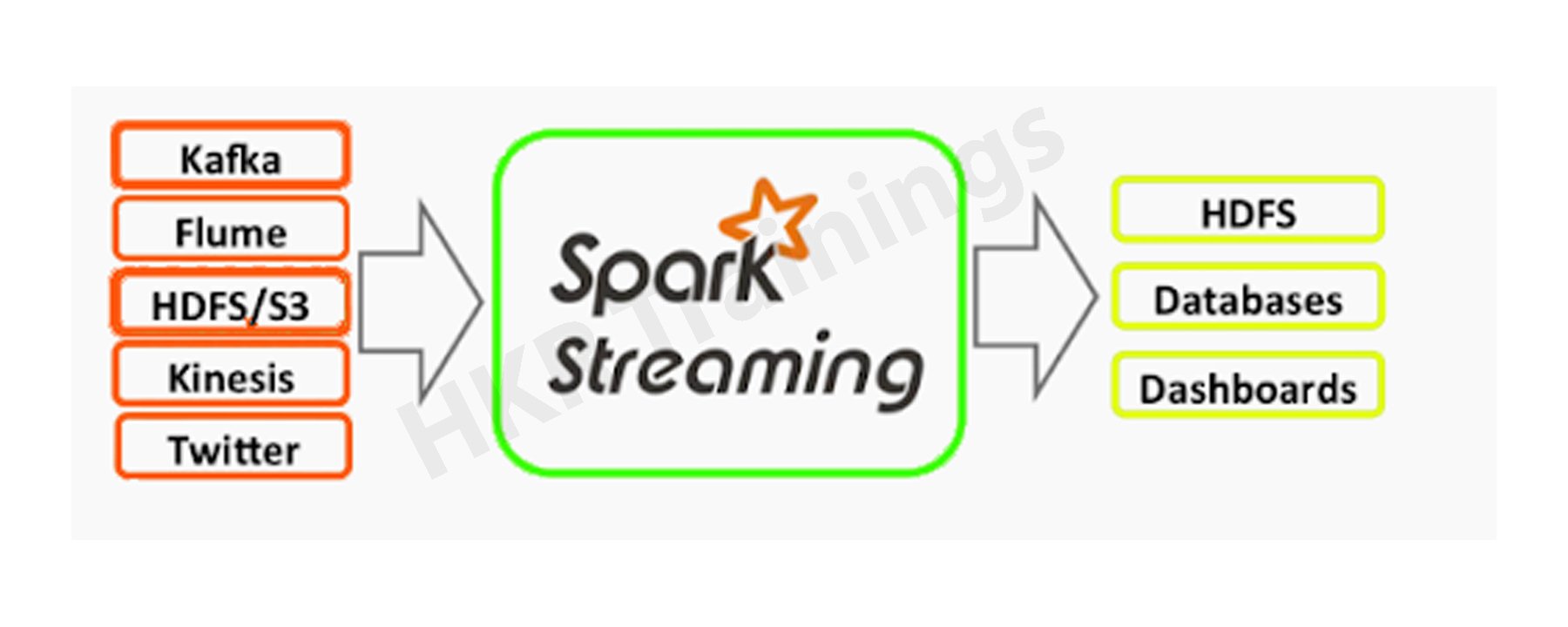
Use readStream.format('socket') from the Spark Session object to read data from the socket and provide host and port options where you want to stream data from.
df = spark.readStream
.format("socket")
.option("host","localhost")
.option("port","9090")
.load()
Spark reads the data from the socket and represents it in the DataFrame "value" column. Outputs df.printSchema()
root
|-- value: string (nullable = true)
You can stream the DataFrame to the console after processing. Ideally, we stream it to Kafka, database e.t.c, in real-time.
query = count.writeStream
.format("console")
.outputMode("complete")
.start()
.awaitTermination()
Pyspark GraphFrames:
PySpark GraphFrames are implemented in the Spark 3.0 version to support DataFrame Graphs. Prior to 3.0, Spark has a GraphX library that is best run on RDD and loses all data frame capabilities.
GraphFrames is an Apache Spark kit that offers dataframe-based graphics. It offers high-level APIs for Scala, Java, and Python. It aims to include both the functionality of GraphX and the expanded functionality of Spark DataFrames. This expanded functionality includes motif discovery, dataframe-based serialisation, and highly expressive graph queries.
GraphX operates on RDDs where GraphFrames works on DataFrames.
Conclusion:
As one of the most common frameworks when it comes to Big Data Analytics, Python has gained so much prominence that you wouldn't be surprised if it were a de facto platform for analysing and dealing with massive datasets and Machine Learning in the coming years.
Apache Spark has so many applications in various sectors that it was only a matter of time for the Apache Spark community to set up an API to support one of the most common high-level and general-purpose programming languages, Python. Not only is Python easy to learn and use with its English-like syntax, it already has a large community of users and supporters.
So being able to incorporate all of Python's main features in the Spark framework, while still using Spark's Python building blocks and operations with Apache Spark's Python API, is truly a gift from the Apache Spark community.
Related Articles:
About Author
Upcoming PySpark Training Certification Online classes
| Batch starts on 22nd Jul 2026 |
|
||
| Batch starts on 26th Jul 2026 |
|
||
| Batch starts on 30th Jul 2026 |
|