
Data Science Interview Questions
Last updated on Nov 20, 2023

In recent times, we have seen rapid growth in the field of Data Science. With this, the number of opportunities for professionals in Data Science has increased as well. To pursue a Data Science career, I think you are in search of Data Science interview questions. In this blog, you will gain knowledge about the frequently asked Data Science interview questions, which are curated by professionals to help you crack the job opportunity in Data Science technology. Let's start with the latest Data Science interview questions now.
Most Frequently Asked Data science Interview Questions and Answers
- What is Data Science?
- What is meant by imbalanced data?
- What is meant by Selection bias?
- What is meant by dimensionality reduction?
- When will the Resampling be performed?
- What is meant by the recommender system?
- What is meant by the term deep learning?
- What is meant by uniform distribution?
- What is a star schema?
- What are the feature vectors?
- What is collaborative Filtering?
- How can outlier values be treated?
- What is RMSE?
- What is a normal distribution?
What is Data Science?
Ans: Data Science is referred to as an interdisciplinary field in computer science that comprises tools, algorithms, scientific processes, and techniques of machine learning that help in gathering valuable insights based on the raw data by using mathematical and statistical analysis.
Become a Data Science Certified professional by learning this HKR Data Science Training !
Elucidate the differences between Data Science and Data Analytics.
Ans: Data Science is referred to as technology that comprises many various subsets that include data mining, data Analytics, data visualization, etc., whereas data analytics is a subset of Data Science. The primary goal of Data Science is to focus on discovering new insights which help in deriving the best solutions to clear the issues in business, whereas the primary goal of Data Analytics is to identify and present clear details of the insights that are retrieved. Data Science requires a keen knowledge of advanced programming languages, whereas Data Analytics does not require advanced programming language knowledge. The primary roles and responsibilities of a data scientist are to identify and provide meaningful insight into data visualizations from the available raw data, whereas the data analyst is responsible for data analysis to make precise decisions.
What are the different types of techniques used for sampling?
Ans: Data analysis cannot be performed when the volume of data is large, for example, large data sets. Hence, it is important to ensure that some of the data samples are taken for representation purposes and also to perform an analysis based on the sample data. It is very necessary to ensure the sample data is taken out from the huge data for sampling purposes. There are two different categories of sampling techniques that are used based on the statistics data. They are:
- Non-probability sampling techniques: These techniques include convenience sampling, quota sampling, snowball sampling, etc.
- b. Probability sampling techniques: These techniques include simple random sampling, clustered sampling, stratified sampling, etc.
Define the terms Eigenvalues and Eigenvectors?
Ans: Eigenvectors, otherwise called right vectors, are referred to as the unit vectors or the column vectors whose magnitude or length will be equal to 1. Eigenvalues are referred to as coefficients that are applicable to the Eigenvectors. A matrix can be composed of angle values in Eigenvectors, and this process of decomposition is called Eigen decomposition. These are utilized in the machine learning methods to gain some valuable insights based on the matrix.
What is meant by imbalanced data?
Ans: Imbalanced Data refers to that data is not distributed equally within different categories. Such kinds of data sets will result in accuracy and come up with errors that will affect the performance levels.
What is meant by linear regression?
Ans: Linear regression is referred to as a process that helps in gaining an understanding of the relationship that exists between the independent variables and dependent variables. It is also considered a supervised learning algorithm that is used for determining the relationship that exists between two variables. With linear regression, one will be able to understand the changes between a dependent variable and the independent variable. It is called simple linear regression when there is only one independent variable, while it is called multiple linear regression when there is more than one independent variable.
Explain the major differences between traditional programming and Data Science?
Ans: The approach is totally different in Data Science when compared to the traditional system application development.
In the traditional system or traditional programming, the input needs to be analyzed, and the expected output also needs to be figured out along with the coding part, which requires some statements and rules to be transformed to deliver the output based on the provided input. It is not an easy task to write the rules, and it takes a long time for the computers to have an understanding of the data.
With Data Science, the process or approach has been changed, which requires accessing large volumes of data, which includes the required inputs, and then mapping the input to obtain the required outputs or expected outputs. Data Science makes use of the Data Science algorithms, which hands in performing analysis and generating the rules that are required for mapping the inputs to outputs. The process that is used for generating the rule is called training.
In simple terms, traditional programming requires the writing of the rules and statements manually to map the input and receive the expected output, whereas, in Data Science, the rules will be automatically generated based on the given data, which will help in deriving solutions for the challenges that are faced by multiple organizations.
What is meant by Logistic regression?
Ans: Logistic regression is referred to as a classification algorithm that is utilized when the dependent variable is a binary variable.
Define the term confusion matrix?
Ans: A Confusion matrix is referred to as a table that is used for estimating the performance of the model. It is represented in a tabular format which includes the predicted and actual values represented in a 2x2 format.
. What is meant by underfitting and overfitting models?
Ans: Overfitting: In overfitting, the model will be capable of performing well only for a certain data which is the sample training data. In the overfitting type of condition, the result will be zero if you provide any different input. This happens when there is high variance and low bias in the model.
Underfitting: Underfitting comprises of a simple model and is not capable of identifying the relationship in the data, which in turn does not perform well on the test data as well. This usually happens due to low variance and high bias.
. What is meant by Selection bias?
Ans: A Selection bias is considered as an error that takes place when the person who researches is deciding on who is going to be studied. Selection bias is based on the research where participants are not selected randomly. If selection bias is not considered, then the decisions or the conclusions may not be correct.

Data Science Certification Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
. Explain the significance of data cleaning in data analysis?
Ans: Data cleaning is referred to as one of the phases in the Data Science life cycle and is considered one of the difficult tasks to be performed as the time required for data cleaning will increase when there is an increase in the data sources. This happens due to the large volumes of data being generated by the additional sources. In order to perform a data analysis task, data cleaning will take up almost 80% of the total time. Some of the important reasons why data cleaning is used in data analysis are listed below.
- It helps in increasing the accuracy level.
- It helps in cleaning the data from the various resources and also helps in transforming the data into an easy format.
. What is meant by false positive rate and true positive rate?
Ans: TPR is called the true positive rate, the percentage between the two positive numbers and the total value of false-negative and true positive together is calculated as TPR. FPR, called the false-positive rate, as the percentage between the number of false positives and the total number of false positives and true negatives is calculated as FPR.
. Can you explain why Python is used for data cleaning in Data Science?
Ans: Python is one of the popular programming languages which includes a set of libraries like Pandas and NumPy. With these libraries, it is easy to eliminate the data values that are inaccurate and helps in data cleaning efficiently.
. What is meant by dimensionality reduction?
Ans: Dimensionality reduction is referred to as a process that helps in converting the given data set with more dimensions or a field to a data set with less number of dimensions for data sets. This takes place by dropping some of the fields from the columns from the given data set. It is important to make sure that the remaining information is still available and will be enough when certain fields of dimensions are dropped during the process of dimensionality reduction.
. List out the different libraries that are used in the Data Science field?
Ans: Below listed are some of the popular libraries that are used for performing the activities in Data Science models:
- Pandas: This library is used for implementing the three main ETL activities - extraction, transformation, and loading of the data sets in the different business applications.
- Matplotlib: This library is an open-source and free one that is available for the users or replacement available for Matlab with its primary goal to improve the performance level and reduce the memory consumption levels.
- Tensorflow: This library provides extensive support to parallel computing with its great feature of library management.
- Pytorch: This library is used in those projects which include deep neural networks and machine learning algorithms and is identified as the best library for such projects.
- SciPy: This library will help in providing its support for solving multidimensional programming, differential equations, data visualization, and manipulation using charts and graphs.
. When will the Resampling be performed?
Ans: Resampling is referred to as a process that makes use of the sample data to increase the efficiency levels and also quantifies the population parameters. Resampling is performed to ensure that the model is good enough to perform the training activity on the model using the different patterns of the data set. It is performed in those cases when there is a need for validation to be performed on the models by making use of the random subsets.
. What is meant by bias-variance tradeoff?
Ans: Let's discuss and gain an understanding of the meaning of variance and bias first.
Bias: A Bias is referred to as an error that occurs when there is an oversimplification of a machine learning algorithm. After the model training is completed, simple assumptions are made to make sure that the model is capable of understanding the target function. Decision trees are some of the algorithms that have low bias, and linear regression algorithms and Logistic algorithms are those which have a higher bias.
Variance: Variance is also referred to as an error that occurs when the machine learning algorithm is highly complex. There is a high chance of overfitting taking place when they perform badly.
When there is an increase in the model complexity, there is a high chance that error can be reduced. This usually takes place if there is a low bias in the model. Whenever it reaches a particular point called the optimal point, and then we are increasing the model complexity, there is a chance of lifting, which leads to a high variance problem.
. List out the different types of biases that take place during the sampling process?
Ans: There are three different types of biases that take place during the sampling process. They are:
- Survivorship bias
- Undercoverage Bias
- Selection bias
. What is meant by the decision tree algorithm?
Ans: A Decision tree algorithm is referred to as a supervised machine learning algorithm that is used for performing the regression and classification of the data sets. The decision tree will help in breaking down a large volume of data set into a smaller subset and is also capable of handling both numerical and categorical based
data.
. What is meant by the recommender system?
Ans: A recommender system is referred to as a subclass of information filtering techniques. This is used to help you in predicting the ratings and preferences that users might provide you based on your product.
. Elucidate the differences between the mean value and expected value?
Ans: There are no differences between the mean value and expected value, but they are represented in different contexts. A Mean value is referred to as the value, which is a term based on your probability distribution, whereas the expected value is represented in the context of a random variable.
. What is the primary goal of a/b testing?
Ans: A/B testing is used for performing random experiments on the variables, especially with two sets of variables, A and B. The primary focus of this testing method is to identify the changes that take place for the maximization of the webpage or to improve and increase the outcome level of a strategy.
. List out the different steps in the life cycle of a Data Analytics project?
Ans: Some of the steps to be followed in an analytics project are:
- Gain an understanding of the problem in the business
- Try to explore the data and have a keen idea of it
- Start preparing the data for modeling purposes and identify the variables and values.
- Run the business model and start analyzing the result of the big data
- Perform the validation of the model with a new data set
- Deploy and implement the model, performing the tracking process to ensure that the performance is good.
. What is meant by the term deep learning?
Ans: Deep learning refers to a subset of machine learning, which includes this set of algorithms based on the structure called artificial neural networks.
. List out the different types of deep learning frameworks?
Ans: a. Keras
- Microsoft cognitive Toolkit
- Chainer
- Pytorch
- Caffe
- Tensorflow
Subscribe to our YouTube channel to get new updates..!
. What is meant by random forest?
Ans: A Random forest is referred to as a machine learning method that helps in performing all the different kinds of regression and the tasks that are related to the classification as well.
. What is meant by skewed distribution?
Ans: When the data is represented or distributed on any side of the plot, then skewed distribution occurs.
. What is meant by uniform distribution?
Ans: When the data is spread equally in the defined range, then uniform distribution takes place.
. Difference between Point Estimates and Confidence Interval
A point estimate is a single value estimation of a parameter, and a confidence interval is an interval, and both are closely related. Further, it tells us a point estimate is located precisely in the centre of the confidence interval, and the confidence interval gives us more information than a point estimate and is preferred to make a decision.
. What does NLP stand for?
NLP abbreviates for Natural Language Processing, it is the ability of a computer to recognise human language in written and verbal format. It deals with the study of computers and how they learn textual data through programming. Applications like medical research, business intelligence, and search engines are included in NLP.
. Why is R used in Data Visualisation?
R is a language designed to analyse statistical computing and graphical data.
- By using R we can create graphs with data visualisation tools.
- R is used in customising graphics.
- It consists of multiple libraries such as leaflet, lattice, ggplot2 etc and consists of many inbuilt functions also.
- It is used in exploratory data analysis and feature engineering.
. What is a star schema?
Star schema is a conventional database schema with a multi-dimensional data model. It is called a star schema as its relationship with the entity represents a star. The central table is divided into points, and the main table is called a lookup table. The design is optimised to query big data sets.
. What are the drawbacks of the linear model?
- It only looks at linear relationships between independent and dependent variables.
- It is not flexible enough to capture complex patterns
- It cannot be used to count binary outcomes
- It assumes that the data is independent.
. What is the ROC curve?
The receiver Operator Characteristic (ROC) curve is the relation between the False Positive Rate and The True Positive Rate. True Positive Rate is to be taken on the Y-axis and False Positivity Rate on the X-axis. ROC is used in binary classification.
. What is the equation of precision and recall rate?
Precision = True Positive / (True Positive + False Positive)
Precision = TP / (TP+ FP)
Recall rate = True Positive / (True Positive + False Negative)
Recall rate = TP/ (TP+FN)
. What is a random forest model?
Its learning is a controlled learning model which consists of labels and mappings between outputs and inputs. A Random forest depends on the number of decision trees present. If the data is split into various packages, it makes each decision tree into a different data group, and the random forest will bring all the trees together.
. Write a function that, when called with a confusion matrix for a binary classification model, returns a dictionary with its precision and recall.
We can use the below for this purpose:
Which of the following machine learning algorithms can be used for inputting missing values of both categorical and continuous variables?def calculate_precsion_and_recall(matrix):
true_positive = matrix[0][0]
false_positive = matrix[0][1]
false_negative = matrix[1][0]
return { 'precision': (true_positive) / (true_positive + false_positive),
'recall': (true_positive) / (true_positive + false_negative) }
. If You are given a data set consisting of variables with more than 30 percent missing values. How will you deal with them?
There are two ways to address the missing values in python.
In the first method, if the data is simple, we can replace missing values by using the average or mean of the remaining data with the help of pandas’ data frame.
The easiest and the second method is that if the data is large, we can remove the rows with missing data values and predict the values with the help of the remaining data.
. What are the feature vectors?
A feature vector is a vector that contains multiple features or elements which are arranged in a specific way. Feature vector describes objects with a pattern that is recognised by machine learning. Feature vectors represent symbolic or numeric characteristics called Features of an object to analyse.
. What are the assumptions required for linear regression?
There are many assumptions required for linear regression. They are :
- The primary observation is that each observation is independent of all other observations.
- The second assumption is the misspecification of a model, it means you have used all the appropriate explanatory variables in your model. If you don’t do this, you will get the results of the wrong model.
- The third assumption is that the relation between the dependent and independent variables is linear.
- The variance of the residual is similar to any value of an independent variable and is denoted as X.
- The independent variable is the general distribution to any value of an independent variable.
. What is selection bias?
Selection bias is a phenomenon of selecting data, individuals or groups to analyse and prevent proper randomization and the collected sample is not representative of the population. It is also called the selection effect. Without selection effects, we can’t get a clear conclusion, and the study is not up to the mark. There are many types of selection bias like Participation bias, Sampling bias etc.
. What does root cause analysis mean?
Root Cause Analysis (RCA) is the method to find out the root cause of a problem and find the correct solution. This technique was initially used to analyse industrial accidents, later developed and used in various sectors.
. Explain TF/IDF vectorization.
TF means team frequency and IDF means inverse document frequency. TF-IDF vectorization is a numerical measure that allows us to determine how a word is significant to document in a corpus. A corpus is a collection of documents, and TF/IDF is mainly used in information retrieval and text mining.
. What is collaborative Filtering?
Collaborative Filtering is a technique used to select the items that the users like depending on the reaction of similar users. In this, we categorise the users into clusters depending on their taste and recommend users according to the cluster. It has two senses: a narrow sense and a general sense.
. What is survivorship bias?
Survivorship bias is also called ‘survival’. Survivorship bias will happen when we focus on the people or things that made it through the selection process. Overlooking of those will not work as they lack of prominence and often leads to wrong conclusions in numerous ways.
. What does the word ‘Naive’ mean in Naive Bayes?
Naive Bayes is a data science algorithm. Naive Bayes is called Naive as it assumes that every input variable is not dependent. For actual data, the assumptions are strong and non-realistic. Generally Naive Bayes will work on huge and complicated problems like spam, email classifications.
. Describe Markov chains?
A Markov process or Markov chain is a stochastic process type category that describes a sequence of probable events. The probability depends on the previous event’s state, and it depends only on the current state and defines a state’s future probability.
. Difference between Normalisation and Standardisation
There are many differences between Normalisation and Standardisation. Let us know some of them:
Normalisation :
- The values lies between (0,1) or (-1,1)
- It is also called Scaling Normalisation.
- For scaling, minimum and maximum features are used.
- It is used when we don’t know about the distribution.
Standardisation:
- We can not decide the range
- It is also called Z-Score Normalisation
- For scaling, the mean and standard deviation are used.
- It is used when the feature distribution is Gaussian or Normal.
. Explain cross-validation.
Cross-validation is a validation technique to evaluate how statistical analysis outcomes generalize independent data sets. It is used in the background process, and the main objective is to test, evaluate the data, and reduce the problems and errors in the data.
. How can outlier values be treated?
Outlier values can be treated in many ways
- If it is a garbage value, you can remove the outliers.
- To remove the value
- To bring in and change the value within a range.
- By normalising data, the points are pulled to a similar range.
. Explain boosting in Data Science.
Boosting is one of the methods used in machine learning to minimise errors in predictive data analysis. In boosting, multiple models are created and trained sequentially by joining weak models. Training a new model will depend on the model which is trained before. Boosting is used to reduce bias in models.
. Explain how Machine Learning is different from Deep Learning.
Machine Learning is a much more general umbrella of tools than deep learning. Machine learning is a subset of data science, and deep learning is a subset of Machine Learning. It uses data to find perfect results and focuses on developing computer programs that access the data. Deep learning networks use neural networks with many layers.
. What is ensemble learning?
Ensemble learning is a normal approach to machine learning which looks for a better approach by joining the predictions from multiple models.
Machine learning which looks for better performance by combining the predictions in multiple models, is called Ensemble learning.
For example, When we are building models using Data Science and Machine Learning, our aim is to get a model that can understand the underlying trends in the training data and can make predictions or classifications with a high level of accuracy. However, sometimes some datasets are very complex, and it is difficult for one model to be able to grasp the underlying trends in these datasets. In such situations, we combine several individual models together to improve the performance.
. What is RMSE?
RMSE means Root Mean Square Error. It is a measure of the accuracy of the regression. RMSE can figure out an account of the error that a regression model produces. RMSE can be calculated as
First, we must calculate the difference between the predicted and the actual values. Then we have to square the errors. Then calculate the mean of the squared errors and finally, take the square root of the mean of these squared errors. This number is RMSE. The lower the RMSE value indicates lower errors produced.
The formula is:
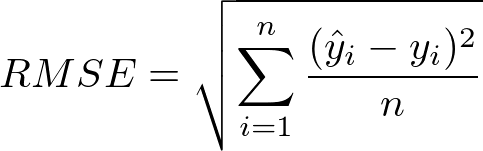
. What is a p-value?
P-value is used in hypothesis testing. P-value is the measure of the statistical importance of observation or the random chance of getting the observed data. The lower the p-value indicates the stronger evidence to reject the null hypothesis. It mainly helps in selecting whether to reject or accept the null hypothesis.
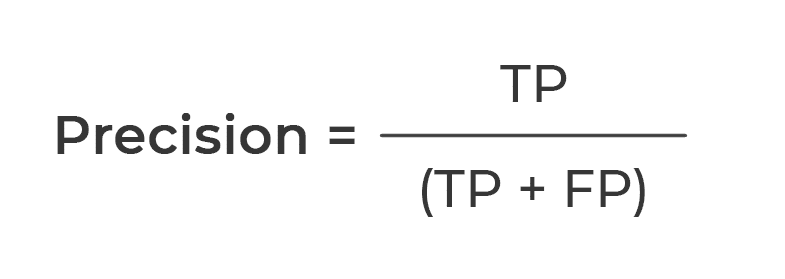
. What is precision?
Precision is measuring the accuracy of true positive predictions. It refers to the number of true positives divided by the total number of positive predictions. Precision is one of the indicators of a machine learning model’s performance.
It is calculated by using the formula:
. What is a normal distribution?
A normal distribution is also known as Gaussian or Gauss distribution. Normal distribution means the continuous probability distribution with a probability density function which gives you a symmetrical bell curve. The Data distribution is a visualisation tool that analyses how data is distributed. Data can be distributed in many ways, like mean, median, etc., this kind of data is called a normal distribution.
. What is k-fold cross-validation?
K-fold cross-validation is a method in which data is resampled to evaluate a machine learning model. The data is split into k different equal parts. When we loop over the dataset for k times, then in each loop, one of the k parts is utilized in the testing, and the remaining k-1 parts are utilised in training.
. What is an RNN (recurrent neural network)?
RNN is a kind of Machine Learning algorithm that uses the artificial neural network. The recurrent neural network is a type of neural network that works on the principle of saving the output of a particular layer and feeding it as the input in the current step and predicting the output of the layer. The vital feature of RNN is the Hidden state, where some information about a sequence is stored.
About Author
Upcoming Data Science Certification Training Online classes
| Batch starts on 30th Jul 2026 |
|
||
| Batch starts on 3rd Aug 2026 |
|
||
| Batch starts on 7th Aug 2026 |
|