
Informatica Interview Questions
Last updated on Nov 11, 2023

Informatica offers data integration products. It offers products for ETL, data masking, data quality, data replica, data virtualization, master data management, etc. It delivers enterprise data integration and management software powering analytics for big data and cloud.
In this article, you can go through the set of Informatica interview questions most frequently asked in the interview panel. This will help you crack the interview as the topmost industry experts curate these at HKR trainings.
Let us have a quick review of the Informatica interview questions.
Most Frequently Asked Informatica Interview Questions and Answers
What do you understand by INFORMATICA? What is the need to use it?
- What is the difference between Mapping and Mapplet?
- What are the different mapping design tips for Informatica?
- Source Qualifier and Filter Transformation- Explain the Differences.
- What is Workflow Monitor?
- What do you understand by the term Worklet?
- What do you understand by the term INFORMATICA PowerCenter?
- What is the best way to use the Batches?
- Explain the different sorts of Caches in lookup transformation?
- Illustrate the differences between the STOP and ABORT?
- Explain data-driven sessions?
- What is the pmcmd command, and how to use it?
- What are the differences between Informatica and Datastage?
- Name the various output files that Informatica Server builds at runtime
- How can we create indexes after completing the load process?
- What is a User-Defined Event?
1. What do you understand by INFORMATICA? What is the need to use it?
Ans: INFORMATICA is a product advancement firm that offers various information incorporation solutions for ETL, information virtualization, ace information the executives, information quality, information imitation, ultra informing, and so forth.
Want to Become a Master in Informatica? Then visit here to Learn Informatica Training
A portion of the well-known INFORMATICA items are:
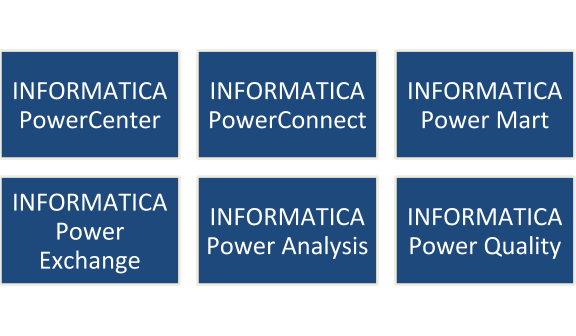
The IT community needs INFORMATICA while working with information frameworks that contain information to play out specific activities alongside a lot of rules. It encourages tasks line cleaning and altering information from organized and unstructured information frameworks.
2. What is the difference between a database, a data warehouse and a data mart?
Ans:
Database:
It includes a set of sensible data. This affiliated data is normally small in size as compared to a data warehouse.
Data Warehouse:
It includes the assortments of all sorts of data. The data is taken out only according to the customer's needs.
Datamart:
It is also a set of data which is designed to cater to the needs of different domains. For instance, an organization having a different chunk of data for its different departments i.e. sales, finance, marketing etc.
3. Name the different lookup caches?
Ans: Informatica Lookup Caches have different natures, such as Static or Dynamic. They can also be persistent or non-persistent, and the following are the different types of lookup caches.
- Static cache
- Persistent cache
- Shared cache
- Dynamic cache
- Recache
4. What are the components of Informatica PowerCenter?
Ans: The various components of the Informatica PowerCenter are

5. How can we store previous session logs?
Ans: If you run the session in the time stamp mode then automatically session log out will not overwrite the current session log.
- Go to Session Properties –> Config Object –> Log Options
- Select the properties as follows:
- Save session log by –> SessionRuns.
- Save session log for these runs –> Change the number that you want to save the number of log files (Default is 0).
- If you want to save all of the log files created by every run, and then select the option Save session log for these runs –> Session TimeStamp. You can find these properties in the session/workflow Properties.
Get ahead in your career by learning Informatica course through hkrtrainings Informatica Training in Hyderbad !
6. What is the difference between Mapping and Mapplet?
Ans:
Mapping:
- It is a collection of source, target and transformation.
- It is developed with different transformations and is not reusable.
- It is developed around what data to move the target and what modification is performed on it.
Mapplet:
- It is a collection of transformation only.
- It can be reused with other mapping and also mapplets.
- It is developed for complex calculations used in multiple mappings.
7. How are indexes created after completing the load process?
Ans:
- Command tasks at session-level are used to create the indexes after the load process.
- Index creating scripts can be brought in line with the session's workflow or the post-session implementation sequence.
- This type of index creation cannot be controlled after the load process at the transformation level.
8. Here are the names of the 4 popular types of tracing level:
Ans:

9. What is the meaning of Enterprise Data Warehousing?
Ans: Enterprise Data Warehousing is about organizing the data that can be created or developed at a single point of access. The data is globally accessed and viewed through a single source as the server is linked to a single source. Enterprise data warehousing also includes the periodic analysis of the source.
10. Explain sessions. Explain how batches are used to combine executions?
Ans:
- A session is a teaching set that is implemented to convert data from a source to a target. Session's manager is used to carry out a session or by using the “pmcmd” command.
- Batch execution can be used to combine sessions executions either in a serial manner or in a parallel. Batches can have different sessions carrying forward in a parallel or serial manner.
11. Explain the difference between mapping parameter and mapping variable?
Ans:
Mapping variable:
- Mapping variables are the values which change during the session’s execution.
- After completion, the Informatica server stores the end value of a variable and is reused when session restarts.
Mapping parameter:
- Mapping parameters are the values which do not change during the session execution.
- Mapping procedure explains mapping parameters and their usage. Values are allocated to these parameters before starting the session.
12. What are the different mapping design tips for Informatica?
Ans: The different mapping design tips are as follows.
- Standards: The design should be of a good standard. Long run projects are proven to have consistent standards. These standards include naming descriptions, conventions, environmental settings, documentation and parameter files etc.
- Reusability: Using reusable transformation is the best way to react to the potential changes as quickly as possible. Mapplets and worklets are the two best-suited types of Informatica components which can be used.
- Scalability: It is crucial to scale while designing. In the development of mappings, the volume must be correct.
- Simplicity: It is always better to create different mappings instead of creating one complex mapping. Simplicity all about creating a simple and logical process of designing.
- Modularity: This includes reprocessing and using modular techniques for designing.
13. Define Power Centre repository of Informatica?
Ans: Power Centre repository of Informatica consists of the following metadata.
- Source Definition
- Session and session logs
- Workflow
- Target Definition
- Mapping
- ODBC Connection
There are two repositories as follows.
- Global Repositories
- Local Repositories
Mainly Extraction, Loading (ETL) and Transformation of this metadata are performed through the Power Centre Repository.
14. What is a Repository Manager?
Ans: Repository Manager is GVI based administrative client which allows performing the following administrative tasks:
- Creating, editing and deleting the folders.
- Assigning access permissions such as read, write and execute to users for accessing folders.
- Backup and Restore repository objects.
15. What is Workflow Manager?
Ans: Workflow Manager is a GUI based client which allows creating the ELT objects as follows.
- Session.
- Workflow.
- Scheduler.
Session:
- It is a task that executes mapping.
- It is created for each Mapping.
- It is created to provide runtime properties.
- It is a set of instructions that tells ETL server to move the data from source to destination.
Workflow:
It is a set of instructions that tells how to run the session tasks and when to run the session tasks
Scheduler:
A scheduler is an automation process which runs the workflow at a given date and time.
16. What is Informatica PowerCenter?
Ans:
- Informatica PowerCenter is an integration tool which combines the data from multiple OLTP source systems and transforms the data into a homogeneous format to deliver the data throughout the enterprise at any speed.
- It is a GUI based ETL product from Informatica corporation which was founded in the year 1993 at Redwood City, California.
- There are many products in Informatica corporation as follows:
- Informatica Analyzer.
- Life cycle management.
- Master data.
- Informatica power centre is also one of the products of Informatica.
- Using Informatica power centre you can perform Extraction, transformation and loading.
17. Source Qualifier and Filter Transformation- Explain the Differences.
Ans: There are two ways to filter rows in Informatica.
- Source Qualifier Transformation:
- It filters rows while reading data from a relational data source.
- It minimizes the number of rows while mapping to enhance the performance.
- Standard SQL is used by the filter condition for executing in the database.
- Filter Transformation:
- It filters rows within a mapped data from any source.
- It is added close to the source to filter out the unwanted data and maximize the performance.
- It generates true or false values based on conditions.
18. Illustrate the differences that exist between joiner and Lookup Transformation.
Ans:
Joiner:
- It is not possible to override the query.
- Only the ‘=’ operator is available.
- Users can’t restrict the number of rows while reading relational tables.
- Tables are joined using Joins.
Lookup:
- It is possible to override the query.
- All operators are available for use.
- Users can restrict the number of rows while reading relational tables.
- It behaves as Left Outer Join while connecting with the database.
19. What do you understand by the term Lookup Transformation? What are the different types of Lookup transformation?
Ans:
- To retrieve the relevant data, the Lookup transformation is used to look up a source, source qualifier, or target.
- Lookup transformation is used to look up a “flat file”, “relational table”, “view’ or “synonym”.
- The Lookup can be configured as Active or Passive as well as Connected or Unconnected transformation.
- When the mapping contains the lookup transformation, the integration service queries the lookup data and compares it with lookup input port values. Multiple lookup transformations can be used in a mapping.
- The lookup transformation is created with the following type of ports:
- Input port (I)
- Output port (O)
- Look up Ports (L)
- Return Port (R)
20. What is Load Order?
Ans: Load Order is the design mapping application that first loads the data into the dimension tables and then will load the data into the fact table.
- Load Rule: If all dimension table loadings are successful then it loads the data into the fact table.
- Load Frequency: Database gets refreshed on daily loads, weekly loads and monthly loads.
21. What is Rank Transformation in Informatica?
Ans:
- Rank Transformation is a type of an active T/R which allows you to find out either top performance or bottom performers.
- Rank T/R is created with the following types of the port:
- Input Port (I).
- Output Port (O).
- Rank Port (R).
- Variable Port (V).
22. What is a Dimensional Model?
Ans:
- Data Modeling: It is a process of designing the database by fulfilling business requirements specifications.
- A Data Modeler or Database Architect Designs the warehouse Database using a GUI based data modeling tool called “ERWin”.
- The ERWin is a data modeling tool from Computer Associates (A).
- Dimensional modeling consists of following types of schemas designed for Data Warehouse:
- Star Schema.
- Snowflake Schema.
- Gallery Schema.
- A schema is a data model which consists of one or more tables.
23. What is Workflow Monitor?
Ans:
- Workflow Monitor is a GUI based client application which allows users to monitor ETL objects running an ETL Server.
- It collects runtime statistics such as:
- No. of records extracted.
- No. of records loaded.
- No. of records rejected.
- Fetch session log.
- Throughput.
- Complete information can be accessed from the workflow monitor.
- A log file is created for every session.
24. What can we do to improve the performance of Informatica Aggregator Transformation?
Ans:
- Aggregator performance improves extremely if records are sorted before passing to the aggregator and the “sorted input” option under aggregator properties is checked.
- The recordset should be sorted on those particular columns that are used in the “Group By” operation. It is a good scenario to sort the record set in the database level.
25. Define OLAP. What are the different types of OLAP?
Ans: OLAP stands for Online Analytical Processing which is special software that allows users to analyze information from multiple database systems simultaneously. With the help of OLAP, the analysts are able to extract and view the business data from different sources or points of view.
There are three types of OLAP as follows.
- ROLAP: ROLAP or Relational OLAP is an OLAP server that maps multidimensional operations to standard relational operations.
- MOLAP: MOLAP or Multidimensional OLAP uses array-based multidimensional storage engines for multidimensional views on data. Many MOLAP servers use two levels of data storage representation for handling dense and sparse datasets.
- HOLAP: It combines both ROLAP and MOLAP for faster computation and higher scalability of data.
26. What are the features of connected lookup?
Ans: The features of connected lookup is as follows.
- It takes in the input directly from the pipeline.
- It actively participates in the data flow, and both dynamic and static cache is used.
- It caches all lookup columns and returns default values as the output when the lookup condition does not match.
- It is possible to return more than one column value to the output port.
- It supports user-defined default values.
27. Define a Sequence Generator transformation.
Ans:
- This feature is available in both passive and connected configurations.
- It is responsible for generating the primary keys or a sequence of numbers for calculations or processing.
- It has two output ports that can be connected to numerous transformations within a mapplet as follows.
- NEXTVAL: This can be connected to multiple transformations for generating a unique value for each row or transformation.
- CURRVAL: This port is connected when NEXTVAL is already connected to some other transformation within the mapplet.
28. What are the different ways to filter rows using Informatica transformations?
Ans: Ways to filter rows using Informatica transformations are as follows.
- Source Qualifier.
- Joiner.
- Filter.
- Router.
29. What do you understand by the term Worklet?
Ans:
Worklet:
- A worklet is defined as a group of related tasks.
- There are 2 types of worklet:
- Reusable worklet.
- Non-Reusable worklet.
- A worklet expands and executes the tasks inside the workflow.
- A workflow which contains the worklet is known as Parent Workflow.
Types of worklets:
- Reusable Worklet:
- These are created using a worklet designer tool.
- It can be assigned to multiple workflows.
- Non-Reusable Worklet:
- This is Created using the workflow designer tool.
- It is created specifically for the workflow.
30. What are the different transformations where you can use a SQL override?
Ans: Various transformations that can use a SQL override are as follows.
- Source Qualifier.
- Lookup.
- Target.

Informatica Certification Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
31. How to use Normalizer Transformation in Informatica?
Ans:
- Normalizer Transformation is a type of an Active T/R which reads the data from COBOL files and VSAM sources (virtual storage access method).
- Normalizer T/R acts like a source Qualifier T/R while reading the data from COBOL files.
- The Normalizer T/R converts each input record into multiple output records. This is known as Data pivoting.
32. State the differences between SQL Override and Lookup Override?
Ans:
SQL Override:
- The role of SQL Override is to limit the number of incoming rows entering the mapping pipeline.
- It doesn’t use the “Order By” clause and it should be manually entered in the query if we require it. SQL Override can provide any kind of ‘join’ by writing the query.
- It will not give a record if it finds multiple records for a single condition.
Lookup Override:
- It is used to limit the number of lookup rows to avoid the whole table scan by saving the lookup time and the cache it uses.
- It uses the “Order By” clause by default. Lookup Override provides only Non-Equi joins.
- It gives only one record even if it finds multiple records for a single condition.
33. What is XML Source Qualifier Transformation in Informatica?
Ans:
- XML Source Qualifier Transformation reads the data from XML files.
- XML source definition associates with XML source Qualifier.
- The XML files are case sensitive markup language.
- The files are saved with an extension “.XML”.
- The XML file formats are of the hierarchical or parent-child relationship.
- The files can be normalized or denormalized.
34. What are the various advantages of INFORMATICA?
Ans: After having been considered as the most preferred Data Integration apparatus, numerous focal points should be enrolled.
They are:
- It can viably and proficiently convey and change the information between various information sources like Mainframe, RDBMS, and so forth.
- It is typically exceptionally quicker, powerful, and simple learning than some other accessible stage.
- With the assistance of INFORMATICA Workflow Monitor, employments can be effortlessly observed, bombed occupations can be recouped just as moderate running occupations can be called attention to.
- It has highlights like simple handling of database data, information approval, relocation of ventures starting with one database then onto the next, venture advancement, cycle, and so on.
35. What do you understand by the term INFORMATICA PowerCenter?
Ans: Informatica PowerCenter is an ETL/Data Integration device that is utilized to interface and recover information from various sources and information handling. PowerCenter forms a high volume of information and supports information recovery from ERP sources, for example, SAP, PeopleSoft, and so on.
You can associate PowerCenter to database management frameworks like SQL and Oracle to coordinate information into the third frame.
36. What are the databases that you can use to integrate data?
Ans: In the Informatica, you can easily link to an SQL Server Database as well as the Oracle Database to successfully integrate the requisite data into a third system.
37. Briefly describe the ETL program with the help of some examples.
Ans: Known for its uniqueness, ETL device represents Extract, Transform, and Load instrument which essentially tackles the reason for extricating information and sending someplace as characterized by changing it.
To be exact:
- The extraction task is to gather information from sources like the database, documents, and so on.
- Transformation is considered as modifying the information that has been gotten from the source.
- Loading characterizes the way toward taking care of the modified information to the characterized target.
To comprehend in a specialized manner, the ETL instrument gathers information from heterogeneous sources and modifies to make it homogeneous with the goal that it tends to be utilized further for the examination of the characterized task.
38. What is the procedure to elongate the Tracing Level?
Ans: The tracing level can be defined as the amount of information that the server writes in the log file. Tracing level is created and configured either at the transformation level or at session-level else at both the levels.
In Informatica, the tracing level can be characterized as the measure of data that the server writes in the log document. The following level is made and designed either at the change level or at the meeting level else at both the levels.
39. What do you gather by the term Enterprise Data Warehousing?
Ans: At the point when a lot of information is collected at a solitary passage then it is called Enterprise Data Warehousing. This information can be reused and dissected at customary spans or according to the need of the time necessary.
Considered as the focal database or state a solitary purpose of access, venture information warehousing gives a total worldwide view and consequently helps in choice help.
It tends to be progressively comprehended from the accompanying focuses which characterize its highlights:
- All significant business data put away in this bound together database can be gotten to from anyplace over the association.
- Although the time required is increasing, occasional investigation on this single source consistently creates better outcomes.
- Security and honesty of information are never undermined while making it open over the association.
40. Elucidate the advantage of Session Partitioning.
Ans: Right at the time when the integration administration is running in the condition, the work process is divided for better execution. These segments are then used to perform Extraction, Transformation, and Loading.
41. What do you understand by the term Sessions?
Ans: In Informatica, the term Session refers to a lot of guidelines that are utilized while moving information from the source to the goal. We can parcel the meeting to actualize a few groupings of meetings to improve server execution.
In the wake of making a meeting, we can utilize the server chief or order line program pm cmd to stop or start the session.
42. What is the best way to use the Batches?
Ans: Batches are the collection of sessions that are used to migrate the data from the source to target on a server. Batches can have the largest number of sessions in it but they cause more network traffic whereas fewer sessions in a batch can be moved rapidly.
Batches are the assortment of meetings that are utilized to move the information from the source to focus on a server. Clusters can have the biggest number of sessions in it however they cause more system traffic though fewer meetings in a group can be moved quickly.
43. What do you understand by the term Mapping, transformation, and expression transformation?
Ans: Mapping is an assortment of source and targets that are connected through specific arrangements of changes, for example, Expression Transformation, Sorter Transformation, Aggregator Transformation, Router Transformation, and so forth.
44. What do you understand by Aggregator Transformation and Union Transformation?
Ans: Aggregator transformation is a functioning change that is utilized to perform total counts like whole, normal, etc. The total tasks are performed over a gathering of columns, so an impermanent placeholder is required to store every one of these records and play out the figuring.
The Union transformation is a functioning change that you use to consolidate information from various pipelines into a solitary pipeline. As the planning runs, it consolidates information into a solitary yield bunch dependent on the field mappings
45. What do you understand by the term Dimensional Table? What are the different kinds of dimensional tables that are available?
Ans: The term dimension table is the one that portrays business substances of a venture, spoke to as progressive, clear cut data, for example, time, divisions, areas, items, and so on.
- Sorts of measurements in an information distribution center
- A measurement table comprises the characteristics of the realities. Measurements store the literary depictions of the business. Without the measurements, we can't quantify the realities. The various sorts of measurement tables are clarified in detail beneath.
- Conformed Dimension: Confirmed measurements mean precisely the same thing with each conceivable reality table to which they are joined.
- Eg: The date measurement table associated with the business realities is indistinguishable from the date measurement associated with the stock realities.
- Junk Dimension: A garbage measurement is an assortment of arbitrary value-based code banners as well as text credits that are disconnected to a specific measurement. The garbage measurement is just a structure that gives a helpful spot to store the garbage characteristics.
- Eg: Assume that we have a sexual orientation measurement and conjugal status measurement. In the reality table, we have to keep up two keys alluding to these measurements. Rather than that make a garbage measurement that has all the blends of sexual orientation and conjugal status (cross join sex and conjugal status table and make a garbage table). Presently we can keep up just one key in the real table.
- Degenerated Dimension: A savage measurement is a measurement that is gotten from the real table and doesn't have its measurement table.
- Eg: A value-based code in a real table.
- Role-playing measurement: Dimensions which are frequently utilized for different purposes inside a similar database are called pretending measurements. For instance, a date measurement can be utilized for "date of the offer", just as "date of conveyance", or "date of recruit".
46. What do you understand by the term Fact Table? What are the different kinds of Fact Tables?
Ans: The brought together table that has been centralized in the star construction is known as the Fact table. A Fact table ordinarily contains two kinds of sections. Segments that contain the measure called realities and segments, which are remote keys to the measurement tables. The Primary key of the real table is normally the composite key that is comprised of the remote keys of the measurement tables.
47. What is the manner in which one can increase the performance of the data during the joiner transformation?
Ans: The following are the manners by which you can improve the exhibition of Joiner Transformation.
- Perform participates in a database whenever the situation allows.
- At times, this is beyond the realm of imagination, for example, joining tables from two unique databases or level record frameworks. To play out a participate in a database, we can utilize the accompanying alternatives:
- Make and Use a pre-meeting putaway strategy to join the tables in a database.
- Utilize the Source Qualifier chance to play out the join.
- Join arranged information whenever the situation allows
- For an unsorted Joiner change, assign the source with fewer columns as the ace source.
- For an arranged Joiner change, assign the source with less copy key qualities as the ace source.
48. Explain the different sorts of Caches in lookup transformation?
Ans: Given the designs done at the query change/Session Property level, we can have the following kinds of Lookup Caches.
- Un-stored query Here, the query change doesn't make the reserve. For each record, it goes to the query Source, plays out the query, and brings an incentive back. So for 10K lines, it will go to the Lookup source 10K occasions to get the related qualities.
- Cached Lookup–In request to diminish the back and forth correspondence with the Lookup Source and Informatica Server, we can design the query change to make the reserve. Thus, the whole information from the Lookup Source is reserved and all queries are performed against the Caches.
Because of the sorts of the Caches designed, we can have two kinds of reserves, Static and Dynamic.
The Integration Service performs distinctively dependent on the kind of query reserve that is arranged. The accompanying table contrasts Lookup changes and an uncached query, a static reserve, and a powerful store:
49. Persistent Cache
Ans: As a matter of course, the Lookup stores are erased post-effective culmination of the separate meetings, be that as it may, we can design to protect the reserves, to reuse it next time.
50. Shared Cache
Ans: We can share the query store between various changes. We can share an anonymous store between changes in similar planning. We can share a named reserve between changes in the equivalent or various mappings.
51. What is the method to load two different source structure tables in one target table?
Ans: We can utilize the joiner, on the off chance that we need to join the information sources. Utilize a joiner and utilize the coordinating segment to join the tables.
- We can likewise utilize a Union change if the tables have some basic segments and we have to join the information vertically. Make one association change include the coordinating ports structure the two sources, to two distinctive info gatherings, and send the yield gathering to the objective.
The essential thought here is to utilize, either Joiner or Union change, to move the information from two sources to a solitary objective. Because of the prerequisite, we may choose which one ought to be utilized.
52. Explain the term Status Code.
Ans: The Status-Code gives an Error taking care of the system during every meeting. Status Code is given by the put-away system to perceive whether it is submitted effectively or not and gives data to the INFORMATICA server to choose whether the meeting must be halted or preceded.
53. What do you understand by the term Junk Dimensions?
Ans: The term junk dimension is a structure that comprises a gathering of some garbage qualities, for example, irregular codes or banners. It shapes a structure to store related codes for a particular measurement at a solitary spot as opposed to making different tables for the equivalent.
54. Define the term Mapplet.
Ans: The term Mapplet is a reusable object that includes a set of changes. It is built using an applet designer and helps reuse change logic across different mappings. There are two applet types available: Active and Passive.
Subscribe to our YouTube channel to get new updates..!
55. What do you understand by the term Decode?
Ans: To comprehend Decode, we should consider it as like the CASE proclamation in SQL. It is essentially the capacity that is utilized by an articulation chance to look through a particular incentive in a record.
- There can be boundless inquiries inside the Decode work where a port is indicated for returning outcome esteems. This capacity is generally utilized in situations where it is required to supplant settled IF explanations or to supplant query esteems via looking in little tables with steady qualities.
- Decode is a capacity that is utilized inside Expression change. It is utilized simply like the CASE articulation in SQL to look through a particular record.
56. What do you understand by the term Code Page Compatibility in Informatica?
Ans: At the point when information is moved from the source code page to the objective code page then all the qualities of the source page must be available in the objective page to forestall information misfortune, this component is called Code Page Compatibility.
Code page similarity comes into picture when the INFORMATICA server is running in Unicode information development mode. For this situation, the two code pages are supposed to be indistinguishable when their encoded characters are essentially indistinguishable and along these lines brings about no loss of information.
For complete exactness, it is said that the source code page is the subset of the objective code page.
57. Highlight the differences between Connected LookUp & Unconnected LookUp.
Ans: Connected Lookup is a piece of the information stream which is associated with another change, it takes information input legitimately from another change that plays out a query. It utilizes both static and dynamic reserve.
Detached Lookup doesn't take the information contribution from another change yet it very well may be utilized as a capacity in any change utilizing LKP (LookUp) articulation. It utilizes the main static reserve.
58. What is the method to execute Security measures with the help of a Repository manager?
Ans: There are 3 different ways to actualize safety efforts.
They are:
- Folder authorization inside proprietors, gatherings, and clients.
- Locking (Read, Write, Retrieve, Save, and Execute).
- Repository Privileges viz.
- Browse Repository.
- Use the Workflow Manager(to make meetings and clumps and set its properties).
- Workflow Operator(to execute Session and clumps).
- Use Designer, Admin Repository(allows any client to make and oversee storehouse).
- Admin User(allows the client to make an archive server and set its properties).
- SuperUser(all the benefits are allowed to the client).
59. Illustrate the differences between the pre-defined event and User-defined event?
Ans: Predefined events are framework characterized occasions that hold up until the appearance of a particular document in a particular area. It is likewise called a File-Watcher event.
Client Defined events are made by the client to bring whenever up in the work process once made.
60. Illustrate the differences between the Target Designer and Target Load Order?
Ans: Target Designer is utilized for characterizing the Target of information.
When there are numerous sources or a solitary source with various parcels connected to various focuses through the INFORMATICA server then the server utilizes Target Load Order to characterize the request in which the information is to be stacked at an objective.
61. What do you understand by the phrase Staging Area?
Ans: The organizing zone is where transitory tables associated with the work territory are put away or reality tables to give contributions to information preparation.
62. Illustrate the differences between the STOP and ABORT?
Ans:
- STOP command runs on Session task when it is raised, the incorporation administration stops just perusing the information in the information source yet keeps preparing and composing it to the objective.
- ABORT command is utilized to prevent the joining administration from perusing, preparing, and composing information to the objective. It has its own break time of 60 seconds to complete the handling and composing of information through incorporation administration if not, at that point it kills the meeting.
63. What is SUBSTR in Informatica?
Ans: SUBSTR is a command in Informatica that you return the string characters from the database that is under scrutiny.
In case you have any queries, please get back to us, our experts will get back to you.
64. What is parallel processing in Informatica?
Ans. Parallel processing means running two or more processors to handle different parts of a complete task. Splitting up a task between multiple processors will eventually decrease the time to run a program. Parallel processing is mainly used to accomplish computations and complex tasks. In Informatica, we can modify the partition type.
65. How can we delete duplicate rows from flat files?
Ans: You can delete duplicate rows from flat files using an aggregator, a dynamic lookup, or a sorter. Select a distinct option to delete the duplicate rows.
66. Why is sorter an active transformation?
Ans: Sorter is an active transformation as it sorts distinct rows whenever we need and once sorting is done, we get the rows by eliminating duplicate data. Sorter transformation sorts data in descending and ascending order using specified conditions. Sorter transformation.
67. What are the types of groups in router transformation?
Ans: There are three groups in router transformation they are:
- Default group: it consists of data that is unsatisfied with any user.
- Input group: it gets data from the source pipeline. Only one i/p group is present in it.
- Output group: consists of two groups: defined group and default group are the two types of O/P groups.
68. Name different types of transformation that are important?
Ans: Many types of transformations are present in Informatica, which carry out specific functions. Some of them are:
- Source: which reads data from the given source.
- Aggregator: Active transformation performs calculations like sum and average across multiple groups and rows.
- Expression: the passive transformation is suitable for calculating values in individual rows
- Filter: it filters the data in rows and mappings which doesn't meet requirements.
69. Explain the difference between the active and passive transformation.
Ans: Transformations are divided into two types :
Active transformation: This transformation is used to modify the number of rows that pass through the transformation. Rows that do not meet transformation are removed, and it can also modify the row type.
Passive transformation: in this transformation, we can not modify the rows and, in addition to it, maintain the row type and transaction boundary.
70. Explain data-driven sessions?
Ans: In an Informatica server, the data-driven property determines how the data should be treated whenever there is an update strategy transformation in the mapping. The information must be specific whether we need DD_UPDATE, DD_DELETE, or DD_INSERT. Update Strategy Transformation consists of more than one mapping.
71. What is the Informatica domain?
Ans: The domain includes nodes and services, and PowerCenter services are effectively managed by it. Further, the domain explains all the interconnected relationships and nodes undertaken by some administrative point. Moreover, a field contains a service manager, application service components, and one or more nodes.
72. What are different ways of parallel processing?
Ans: Parallel processing means processing data in parallel to increase performance. Informatica parallel processing can be done using several methods depending on the user's choice. The following types are used in implementing parallel processing.
- Round-Robin Partitioning: with this partitioning algorithm, the data is distributed equally among all partitions.
- Database Partitioning: this technique queries the database for table partitioning. It also reads the partitioned data from respective nodes in the database.
- Hash User-keys partitions: integration service uses a hash function. The data is partitioned according to the user's desired way or user-friendly way. Ports are selected by the user individually that define the partition key.
- Hash Auto-keys partitioning: PowerCenter uses a hash auto-key function for grouped data partitioning. The integration service utilises all sorted or grouped ports as compound partition keys.
73. What do you mean by surrogate key?
Ans: A surrogate key is a system-produced identifier and a substitute for the natural primary key. They are also referred to as artificial keys that are added with each record within a dimension table. Also, these keys help to update the table quickly.
74. What is the pmcmd command, and how to use it?
Ans: Pmcmd is a command-line program that is used to manage workflows and communicate integration services. By using the pmcmd command, one can schedule, start, and stop workflows and sessions in the Power Centre domain.
Pmcmd has many uses; they are
Start workflows.
Start a workflow from a specific task.
Stop, Abort workflows and Sessions.
Schedule the workflows.
75. Explain the tracing level?
Ans: Informatica tracing level means the amount of data that the Informatica server writes to the session log file. It is an important component that is helpful in locating bugs and error analysis for every transformation. There are different types of tracing levels they are:
- Normal
- Verbose
- Verbose init
- Verbose data
76. Explain what a DTM (Data Transformation Manager) Process is.
Ans: DTM is an operating system process started by PowerCenter Integration Service (PCIS). Data Transformation Manager (DTM ) or pmdtm main function is to create and manage service level, mapping level, expand session level, variables and parameters. DTM performs many tasks like reading session information, creating partition groups, validating code pages, sending post-session emails, etc.
77. What do you mean by the star schema?
Ans: Star Schema is the sheer data warehouse schema with fact tables and more than a dimension. Due to its star-like shape, it is called Star Schema and helps create data warehouses and dimensional data marts.
78. How does Informatica's update strategy function?
Ans: The active and associated transformation, which permits you to add, delete, or update records in the target table, is the update strategy. It also prevents files from failing to reach the destination table.
79. What are the differences between Informatica and Datastage?
Ans: The following are the significant differences between the popular ETL tools- Informatica and Datastage.
- Informatica has dynamic partitioning, whereas Datastage has a static partitioning system.
- Datastage includes a client-server architecture, whereas Informatica holds a service-oriented structure.
- Informatica offers a stepwise integration process, but Datastage offers the same based on projects.
80. Define Transaction Control Transformation in Informatica.
Ans: In Informatica, an active and associated transformation called "Transaction Control" enables committing and rolling back transactions while a mapping is executed. A group of rows bound by commit or rollback rows is known as a transaction. A transaction is defined based on modification in no input rows. Operations such as commit and rollback assure data availability.
81. How Rank Transformation manages string values?
Ans: We can obtain session sort order's top or bottom strings from a rank transformation. When the Integration Service operates under Unicode mode, text data in the session is sorted based on the chosen sort order for the IS's chosen code page, which could be any language like French, German, Russian, etc. Moreover, the ASCII mode of the Integration Service ignores this parameter. Also, it sorts character data using a binary sort order.
82. Name the various output files that Informatica Server builds at runtime.
Ans: The following are the various types of output files that Informatica server creates at runtime:-
- Informatica Server Log
- Session Detail File
- Reject File
- Indicator File
- Performance Detail File
- Session Log File
- Control File
- Output File
- Cache File
- Post Session Email
83. What are the new features of Informatica 9.x Developer?
Ans:
Informatica 9.x introduces several exciting new features for developers. Here are some of these noteworthy additions:
1. Enhanced Lookup Transformation: The Lookup transformation now includes an option to configure it as an active transformation. This allows it to return multiple rows upon a successful match. Previously, this capability was limited to a single-row return. Additionally, developers can now write SQL overrides on uncached lookups, expanding their flexibility and control.
2. Improved Session Log Control: In Informatica 9.x, developers have the ability to manage the size of the session log. Particularly useful in real-time environments, this feature enables developers to set precise limits on the log file size or log duration, allowing for more efficient log management.
3. Database Deadlock Resilience: Informatica 9.x introduces a valuable feature to handle database deadlocks. When encountering a deadlock, instead of immediately failing the session, the new resilience feature allows the operation to be retried. Developers have the capability to configure the number of retry attempts, enhancing session reliability and stability.
These new features in Informatica 9.x empower developers with added functionality and control, improving the overall development experience and performance of Informatica workflows.
84. Which files are created during the session RUMs in Informatics?
Ans: During session RUMs (Real-time Usage Monitoring) in Informatics, the creation of several types of files takes place. These files include an errors log, which provides a record of any errors encountered during the session. Another file created is the bad file, which contains any data that failed to meet specified criteria or encountered processing errors. Additionally, a workflow log is generated during the session, which provides detailed information on the execution of the workflow. Finally, a session log is also created, logging all activities and details related to the session, such as start time, end time, and status updates.
85. How can we identify whether a mapping is correct or not without a connecting session?
Ans: To determine whether a mapping is correct or not without a connecting session, one approach, as suggested in Passage_1, is to utilize the debugging option. By using this tool, we can effectively assess the accuracy of a mapping without the need for establishing a connecting session.
86. How can we create indexes after completing the load process?
Ans: After completing the load process, indexes can be created using the command task at the session level. This task allows for the creation of indexes in a seamless manner. By specifying the appropriate command and parameters, the indexing procedure can be efficiently executed. This ensures that the necessary indexes are created, enabling faster data retrieval and improved query performance.
87. How can we access repository reports without SQL or other transformations?
Ans: To access repository reports without relying on SQL or other transformations, one approach is to utilize a metadata reporter. This method allows users to directly retrieve repository reports through a web application, eliminating the need for any SQL queries or additional data transformations. By leveraging the capabilities of the metadata reporter, users can effortlessly access and retrieve the desired reports from the repository without any intermediary steps or complex data manipulation.
88. What are the advantages of using Informatica as an ETL tool over Teradata?
Ans:
Informatica offers several advantages over Teradata as an ETL tool:
1. Metadata repository: Informatica serves as a comprehensive metadata repository for an organization's ETL ecosystem. This feature simplifies the maintenance and analysis of metadata, enhancing overall data management efficiency.
2. Job monitoring and recovery: Informatica Workflow Monitor allows for easy monitoring of ETL jobs and provides a quick recovery mechanism in case of any failures or errors during the process. This ensures minimal downtime and increases the reliability of data integration.
3. Extensive toolset and accelerators: Informatica provides a wide range of tools and accelerators that accelerate the software development life cycle. These tools enhance application support and make the development process faster, enabling organizations to be more agile in their data integration initiatives.
4. Diverse developer pool: Informatica boasts a larger pool of developers with varying skill levels and expertise. This availability of skilled resources facilitates smoother implementation and support of ETL processes, leading to efficient data integration.
5. Database connectivity: Informatica offers connectors to various databases, including Teradata. It supports Teradata utilities like MLoad, TPump, FastLoad, and Parallel Transporter, simplifying data extraction and loading processes.
6. Surrogate key generation: Informatica excels in generating surrogate keys efficiently, particularly through shared sequence generators. This feature speeds up the key generation process, enhancing overall performance during data integration.
7. Migration capabilities: If a company decides to migrate away from Teradata, Informatica provides automated solutions that enable quick and efficient migration projects. This feature minimizes the challenges associated with transitioning between different data platforms.
8. Pushdown optimization: Informatica allows for pushdown optimization, which means that data processing can be performed directly within the database. This optimization reduces data movement, improves performance, and leverages the processing power of the underlying database.
9. Load balancing: Informatica offers the capability to efficiently balance the processing load between the ETL server and the database server. This feature optimizes system resources and ensures efficient data integration without overwhelming any particular component.
10. Web service integration: Informatica empowers organizations to publish their ETL processes as web services. This capability enables seamless integration with other applications, systems, or external partners, enhancing the overall flexibility and usability of the ETL solution.
These advantages of Informatica as an ETL tool over Teradata demonstrate its comprehensive functionality, enhanced performance, and flexibility for efficient data integration and management.
89. What are the features of Informatica Developer 9.1.0?
Ans:
Informatica Developer 9.1.0 comes with several new features that enhance its capabilities. One notable feature is the ability to configure the lookup transformation as an active transformation. This means that it can now return multiple rows when there is a successful match. This allows for more flexibility and versatility in data transformation processes.
Additionally, Informatica Developer 9.1.0 now allows for writing SQL overrides on uncached lookups. Previously, this capability was only available for cached lookups. With this new feature, developers can have greater control over the transformation logic and optimize the data retrieval process.
Another improvement in this version is the ability to control the session log file size or log file time in a real-time environment. This feature ensures that the log files do not consume excessive storage space or become too large to handle efficiently. This is especially important in scenarios where data load or transformation processes are executed frequently and require monitoring and troubleshooting.
Overall, these new features in Informatica Developer 9.1.0 enhance the integration and transformation capabilities of the tool, allowing developers to perform more complex data operations and optimize their workflow in real-time environments.
90. How can we update a record in the target table without using Update Strategy?
Ans:
To update a record in the target table without using Update Strategy in Informatica, follow these steps:
1. Define the key in the target table at the Informatica level: At the Informatica level, identify the field that serves as the primary key in the target table. This key will be used to uniquely identify the records in the table.
2. Connect the key and the field to update in the mapping target: In the mapping, create a connection between the primary key field and the field that needs to be updated in the target table. For example, if you want to update the "Customer Address" field, connect the primary key field and the "Customer Address" field.
3. Set the target property to 'Update as Update' and check the 'Update' checkbox: In the session properties, configure the target table with the properties "Update as Update" and check the "Update" checkbox. This ensures that the mapping updates the desired field in the target table instead of performing an insert or delete.
For illustration purposes, let's consider a target table called "Customer" with fields such as "Customer ID," "Customer Name," and "Customer Address." To update the "Customer Address" without using Update Strategy, define "Customer ID" as the primary key at the Informatica level. Then, create a mapping that connects the "Customer ID" field with the "Customer Address" field. Finally, in the session properties, set the target table to "Update as Update" and check the "Update" checkbox.
By following these steps, the mapping will update the "Customer Address" field for all matching customer IDs in the target table, without relying on an Update Strategy transformation.
91. How do pre-session and post-session shell commands function?
Ans:
Pre-session and post-session shell commands are used in session tasks to perform specific actions before or after the execution of the task. These commands can be run as pre-session commands, post-session success commands, or post-session failure commands, depending on the user's requirements.
When used as a pre-session command, the shell command is executed before the session task begins. This allows users to perform any necessary setup or configuration tasks before the main task execution. For example, a pre-session shell command could be used to create temporary tables, set environment variables, or perform any other actions required to prepare the environment for the session task.
Post-session shell commands, on the other hand, are executed after the session task has completed. They can be further categorized as post-session success commands and post-session failure commands. A post-session success command is executed only if the session task completes successfully, while a post-session failure command is executed in case of any failure or error during the task execution.
These shell commands are flexible and can be customized based on specific use cases. Users have the ability to change or alter the application of pre-session and post-session shell commands to meet their specific requirements. This allows for greater control and flexibility in managing the tasks and automating related processes.
In summary, pre-session and post-session shell commands provide users the ability to execute specific commands before or after the execution of session tasks. They offer a way to configure, set up, or clean up the environment, and can be used to automate additional actions based on the success or failure of the session task.
92. In Informatica Workflow Manager, how many repositories can be created?
Ans: In Informatica Workflow Manager, the number of repositories that can be created depends on the required number of ports. In general, there is no specific limit on the number of repositories that can be created. This means that any number of repositories can be created based on the needs and requirements of the user.
93. What is a User-Defined Event?
Ans:
Are user-defined events customizable?
Yes, user-defined events can be customized to suit different needs and requirements.
Can you provide more details on the flow of tasks in a user-defined event?
The flow of tasks in a user-defined event refers to a sequence of actions or steps that need to be accomplished within the workflow.
How can user-defined events be raised?
User-defined events can be raised as per requirements.
How can user-defined events be developed?
User-defined events can be developed according to specific requirements.
What is the nature of a user-defined event?
A user-defined event is a flow of tasks in the workflow.
94. What is a Predefined Event?
Ans:
What is the nature of a predefined event?
A predefined event is characterized as a file-watch event, specifically designed to monitor and respond to the presence of a particular file.
What is the trigger for a predefined event?
A predefined event is triggered by the arrival of a specific file in a specific location.
95. What are mapping parameters vs. mapping variables in Informatica?
Ans:
Does Excerpt_Theirs explain the usage of mapping parameters?
No, Excerpt_Theirs does not explain the usage of mapping parameters.
What does Excerpt_Theirs mention about mapping variables?
Excerpt_Theirs mentions that mapping variables are values that change during the session's execution.
Does Excerpt_Theirs provide information about mapping parameters?
No, Excerpt_Theirs does not provide any information about mapping parameters.
What happens to mapping variables when a session restarts?
When a session restarts, the Informatica server stores the end value of a mapping variable and reuses it.
What specific tool does Excerpt_Theirs mention?
Excerpt_Theirs mentions the Informatica Workflow Manager.
About Author
Upcoming Informatica Certification Training Online classes
| Batch starts on 25th Jul 2026 |
|
||
| Batch starts on 29th Jul 2026 |
|
||
| Batch starts on 2nd Aug 2026 |
|