
SAP HANA Tutorial
Last updated on Jun 12, 2024

Introduction to SAP HANA
SAP HANA is in-memory management, data-oriented, and relational development management system developed and produced by SAP SE enterprise corporation. The primary function of SAP HANA is to manage database applications, store, and retrieve the data as requested by the enterprises. SAP HANA stands for “High performance analytic appliances”. SAP HANA application is a combination of both hardware and software appliances. This module is a data foundation technology that offers advanced level data analytical and multi-dimensional management data-driven applications. SAP HANA product written in JAVA, and C programming languages.
Why SAP HANA is so popular technology?
The following are the important features of SAP HANA that make this technology so popular in the current business platform:
1. SAP HANA acts as an eclipse editor and web-based editor (also known as pick-up and drop services) to support the graphical creation of business applications.
2. Provides Source agnostic data access and integration services that allow accessing and indexing external data from across the entire organization. Add these analytical services to existing analytical models.
3. Real-time data analytical processing can be performed to analyze business operations in real-time using the huge volume of detailed information while business happening.
4. Data can be accumulated from many applications and data sources without disturbing in any way that continuing business operation.
5. View of business information can be carry on in a persistent data repository and build again in case of a crash.
Differences between SAP and SAP HANA
Below are the major differences between SAP and SAP HANA:
First, let us know the SAP thing:
SAP:
1. SAP is a traditional ECC business enterprise application.
2. In SAP, nearly all the SAP transaction codes are available and there is no concept of data simplification.
3. it’s easy to access all the functional modules of SAP and helps you to create real-time data reporting.
4. Also offers additional performance and the SAP solution also boasts amended transactions.
5. Upgrade to ECC6 enhancement package 7 and then perform a database management activity.
SAP HANA:
1. Helps to rebuilt to capitalize the significant simplification that the SAP HANA platform provides.
2. This is a packaged solution that has SAP ERP at its core optimized to run on the HANA platform.
3. Helps to integrate and leverage various solutions and technologies in SAP arsenal.
4. Achieve data simplification. This is achieved by replacing the core tables within certain processes into a single table.
5. SAP HANA is designed with SAP flori for a richer user experience and easily configurable on cloud technology.
Advantages of SAP HANA module:
Below are the few advantages of SAP HANA:
1. Offers in-memory management: this type of in-memory allows for sophisticated data calculations.
2. Acts as calculation engine: In-memory processing gives more time for relatively slow updates to column data.
3. Provides massively parallel processing: MPP optimized software enables linear performance scaling making sophisticated calculations like allocations possible.
4. Larger storage: The columnar storage increases the amount of data that can be stored in limited memory (compared to disk).
5. Row +Column database: Column databases enable easier parallelization of queries. And Row database provides fast transactional processing.
Become a SAP SD Certified professional by learning this HKR SAP SD Training !
SAP HANA – Core Architecture
The below diagram explains the core components and work nature of the SAP HANA module:
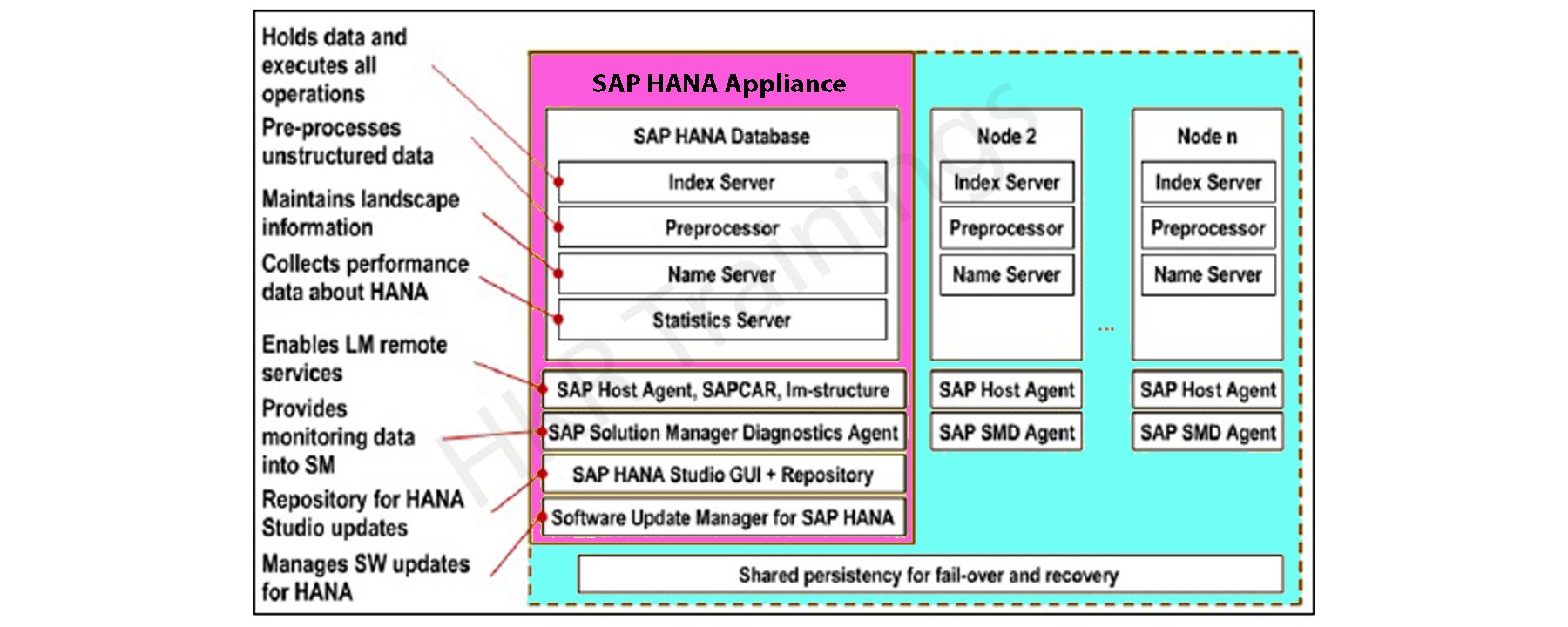
As we already know that SAP HANA is developed with the help of C and JAVA programming languages and designed to run on operations systems like LINUX server enterprise edition 11. Sap HANA consists of multiple components that help to perform many activities. The most important component of SAP HANA architecture is an Index server which consists of an SQL/ MDX processor to handle any type of query statements. The SAP HANA system contains different servers like name servers, statistics server, XS engine, and preprocessor server. All these servers are used to communicate and host multiple web applications.
Index server – a brief detail:
As I said earlier, the index server is an important component of SAP HANA architecture. This server is also known as the heart of the SAP HANA database system. An index server contains the original data and engines to process the data. This type of server takes care of the entire data request and processes them when they are mixed with SQL and MDX. The index server also consists of a data engine to handle all the query statements (SQL/MDX). This also holds a persistent layer used to check the durability of the HANA system and restore the data.
This figure illustrates the overall architecture of the Index server:
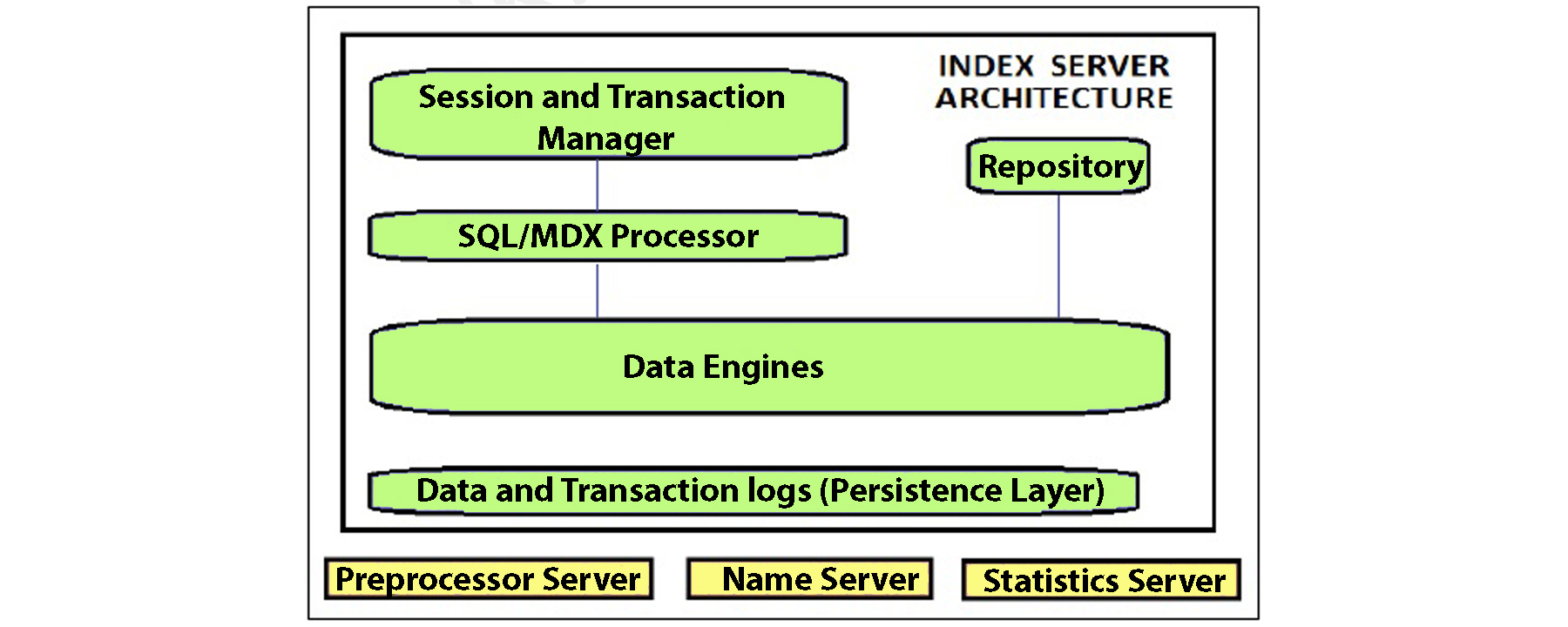
The SQL/MDX processor type is responsible for processing the SQL/MDX data transactions with data engines to run different queries. It requests all the segments to correct the engine for performance optimization. In this processor type, data authorization and also handles all types of errors. MDX or multi-dimensional expression is a query language used in OLAP systems like sequential query language and relational database management system.
The planning engine is responsible to run the planning operations within the database. The calculation engine converts the data into calculation models to build logical data execution. The stored processor executes the procedure call to optimize data processing. The persistent layer is also responsible to check durability and atomicity in SAP HANA systems and also manages the data and transaction logs to manage data backup, HANA system configuration, and log backups.

SAP Hana Training Certification
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
SAP HANA – Studio:
SAP HANA is an eclipse based tool. SAP HANA environment tool is both the main administration and central development. The important features of SAP HANA studio tool:
1. SAP HANA is a client tool; this can be used to control and access the remote or local system.
2. This studio features offers an environment for SAP HANA administration, SAP HANA data modeling, and HANA data provisioning in the database.
SAP HANA Studio can run on the following platforms:
1. This studio uses Microsoft windows 32 and 64-bit versions, which run on Windows XP, Windows Vista, and Windows 7 version.
2. LINUX enterprise server edition SLES11 or SUSE that uses x86 64 bits.
3. For MAC operating system, the SAP HANA studio client is not available.
Types:
1. SAP HANA Studio features or perspectives:
SAP HANA studio offers perspectives to work on the below HANA features. So you can use the following SAP HANA perspectives:
2. SAP HANA studio Administration:
In this feature type, various toolsets available for various Administrative tasks, design time repository objects, and this excludes the transportable data methods. Here users can perform troubleshooting operations like tracing the unwanted catalog browser, and SQL console.
3. SAP HANA Studio database environment feature:
This feature provides various toolsets for content development. It addresses the DataMart, and ABAP using the SAP HANA scenario. And one more important thing, this feature doesn’t include the SAP HANA tool native application development (XS).
4. SAP HANA Studio Application development:
In this feature, the SAP HANA tool consists of a small web browser server, and this web server is used to host the small web-based applications.These toolsets are also used for developing various SAP HANA tool native applications which are written in JAVA and HTML.
Different types of SAP HANA system monitors:
The SAP HANA system monitors are used to control the various tasks like Log disks, Data Disks, trace disks, and alerts on resource usage.
Let me explain them one by one:
1. System ID: this helps in the ID assigned to the system when added to the studio environment.
2. Operational state: maintains the overall system status.
3. Alerts: This monitor is used to check the system issue alerts when resource usage and thresholds are violated. In general, these alerts are categorized into low, medium, or high priority.
4. Data Disks in (GB): this indicates the size of the data volume available on disk.
5. Log disks in (GB): this indicates the size of the log volume on the disk.
6. Database Resident Memory management: this indicates the size of the memory used in an operating system to manage SAP HANA database processes.
7. Used memory: Here the amount of physical memory that is used by the SAP HANA database.
8. CPU in (%): This helps to know the percentage of CPU that has been used by the SAP HANA database.
9. Hostname: it indicates the name of the server hosting used in the SAP HANA database.
10. Instance Number: here the Instance number is the administrative unit that consists of the various server software components.
11. System trace disk in GB: it gives the total disk space used on the disk that contains the trace files.
12. System physical memory in GB: this gives the total amount of physical memory used.
13. Distributed: this indicates whether the system is running on any single web host or this will be distributed in the system.
14. Start time first: this indicates when the time that first started and value is restarted for any important reason.
15. Versions: this indicates the software versions of the SAP HANA environment studio.
16. Platform: this indicates the different operating systems where the SAP HANA studio is running.
17. Number of crash dump files: here the number of crash dump files removed in the SAP HANA system.
SAP HANA information Modeler:
This SAP HANA information modeler is the core of the data modeler. This helps to create the different model views at the top of data base management tables and helps to implement the business logic.
Features of Information modeler:
1. This modeler offers multiple views of transactional data that is stored in physical tables of the SAP HANA database to perform analysis and business logic operations.
2. Information modeler works only for column-based data storage tables.
3. Information modeling views are written using JAVA or HTML based data applications or various SAP tools like SAP Lumira or SAP analysis office.
4. With the help of an information modeler it is possible to use a third-party tool like Microsoft excel to connect SAP HANA and helps to create data reports.
5. SAP HANA information modeling views exploit SAP HANA real power.
There are three types of Information modeler:
1. Attribute view
2. Analytical view
3. Calculation view
Let us know this information modeler views:
1. Attribute view: The attributes are non-measurable data elements in any database table. This view represents the master data and similar to Business warehouse characteristics. Attribute views are also considered as a dimension in SAP HANA database management or used to join the dimensions in information modeling.
The following are the important features of Attribute views:
1. Attribute views are mainly used in data analytic and also for the calculation views.
2. This view represents the master data.
3. Used to filter the table dimensional size in any analytical and calculation view.
2. Analytical views: Analytical views use the power of SAP HANA to perform operations like calculations and aggregate functions in the database table. This has at least one fact data table which measures and primary keys contain master data.
Important features are:
1. Analytic views are used to design to perform star schema data queries.
2. Analytic views contain one fact table and multidimensional tables hold master data and perform tasks like calculations and aggregations.
3. This view is similar to information cubes and information objects in the SAP business warehouse.
3. Calculation view:
Calculation views are located on the top of attribute and analytic views to operate with any complex calculations, which are not possible to do with analytic views. In general, the calculation views are a combination of base data columns, and where attribute and analytic views are mainly used to provide business logic.
The main features are:
1. The calculation views are specified either graphical using SAP HANA information modeling or you can consider SQL scripts.
2. These calculation views are generated to perform complex calculations, which are not possible with any other views like attribute and analytic views in SAP HANA information modeler.
3. Here one or more analytic and attribute views will be consumed with the help of inbuilt functions like Union, projects, joins, or ranks in any calculation views.
SAP HANA export and import options:
Here users can make use of SAP HANA import and export options with the help of tables, columns, information modeler, and Landscape to transport data from one place to another.
Let me explain first with Exporting tables or information model in SAP HANA studio:
The navigation is:
First, go to file menu -> export data file -> then here you will see options as follows
Export options under SAP HANA content:
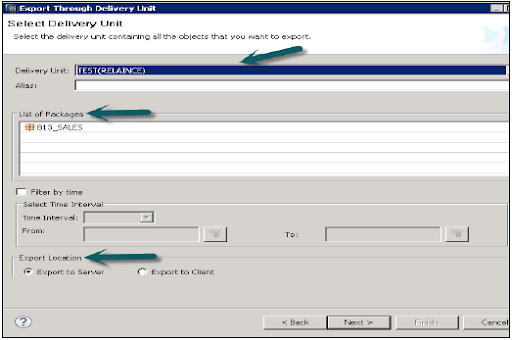
Here the delivery unit is known as a single unit, which can be mapped to multiple data packages and that can be exported as a single data entity. Here all the data packages can be assigned to delivery any unit and this unit acts as a single unit.
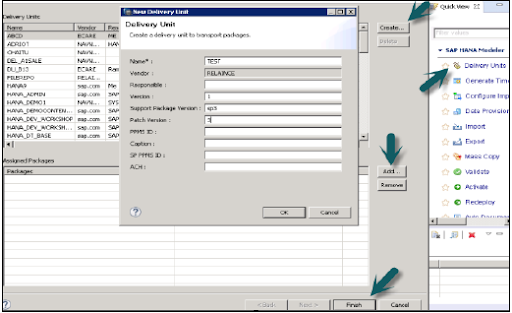
With the help of the below navigation, the delivery unit should perform the task:
First, go to the HANA information modeler -> Delivery unit modification -> select system and next go to create option-> here you need to fill the details like your name, and software version which you are using it -> click OK button -> now it’s time to add packages to any delivery unit -> then click the finish button.
The following window diagram explains the delivery unit:
Once you created the delivery unit and the data packages will be assigned to it. Once you finished this task, you can see the list of data packages with the help of this export option.
The navigation is as follows: Go to file -> then select export -> choose delivery unit -> Choose the option delivery unit.
After you can see the list of all the packages that are assigned to the SAP HANA deliver the unit. The export delivery consists of two options:
1. Export to server
2. Export to client
There are two modes available in the Export unit:
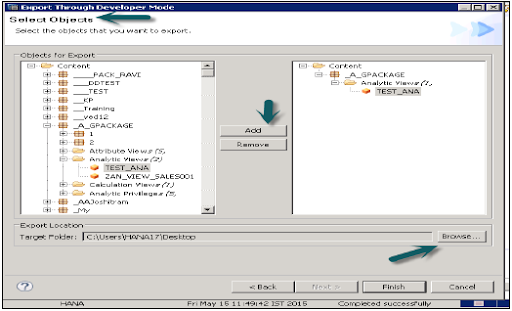
1. Developer mode:
This export option can be used to export the individual date objects to the specified location in the local system. Users can choose the single information view or group of information views, and packages-> select the local data client for export the data and then the finish.
The following screenshot as shown below:
2. Support mode:
This mode can be used to export the data objects that consist of SAP support purposes. For example:
Go to the information view -> this throws the errors -> resolve the case -> then share it with the SAP for debugging task.
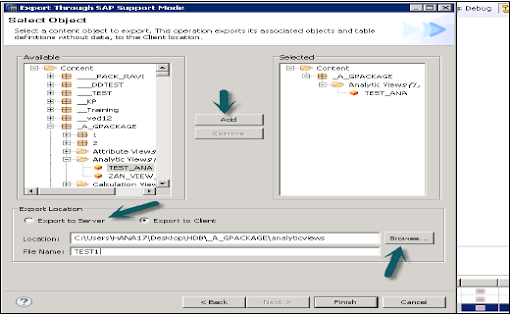
3. Developer mode:
To perform this task, first browse for the local client location where you can view the export and select the views (which are required). Here the user can choose the individual views or group of views-> go to packages -> click on the FINISH button.
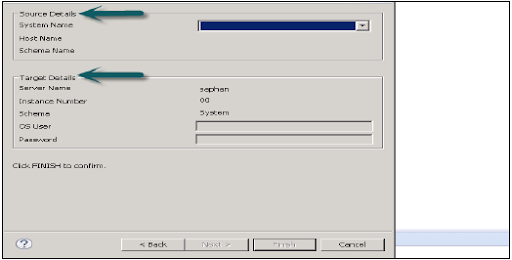
4. Mass import of metadata:
To perform this metadata task:
First go to file -> den import -> choose Mass import of metadata -> then select on next -> now click on source -> target system.
The below diagram explains the configuration of the system for mass to import and then click “finish”.
Subscribe to our YouTube channel to get new updates..!
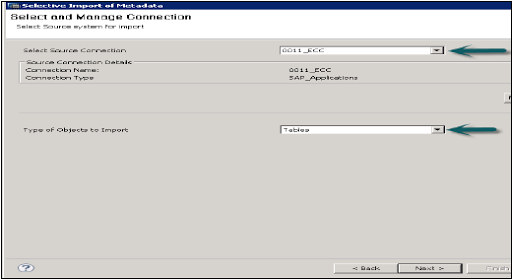
5. Select import of metadata:
This mode allows you to select the tables and target schema to perform a data import from SAP applications, to do this the navigation is as follows:
First go to file -> then choose data import -> go for selective metadata import -> click on Next.
Now it’s time to choose the source connection in the “SAP applications”. One thing should be remembered here when you choose to import the metadata, the data store must have already created in the SAP applications -> then click “NEXT”.
Now select the table you want to create and then validate it-> click after the finish.
SAP HANA- Data types:
Here the data types are required to work with SAP HANA tables and SQL statements. For example:
Create column Table TEST1 (
ID INTEGER, //integer data type
NAME VARCHAR (20), // character data type
PRIMARY KEY1 (ID) // this is used to mention the primary key in the function
);
SAP HANA supports 7 data types and this depends on the type of data column that you have stored in a column.
1. Numeric data type
2. Character or String data type
3. Boolean data type
4. DATE and TIME data type
5. Binary data type
6. Large objects data type
7. Multi-valued data type
Let us know each data types briefly:
1. Numeric data type:
a. TinyINT: this data type stores 8 bits of an unsigned integer. Here the minimum value is 0 and the maximum value is 255.
b. SMALLINT: this data type stores the 16 bits of signed integer data. Here the minimum value you can use is -32,768 and the maximum value is +32,767.
c. Integer: here the integer data type stores 32-bit integer value, the minimum value you used here is -2,147,483… and the maximum value is 2,147,483…..
d. BIGINT: this data type stores the 64-bit integer data that can be stored.
e. REAL: here the minimum value you can store is -3.40E and the maximum value is +3.40E.
2. Boolean data type:
Here Boolean data values that can be stored are “TRUE” or “FALSE”.
3. Character data type:
The character data types stored are:
1. VARCHAR – this stores a maximum of 8000 characters.
2. Nvarchar - this stores the maximum length of 4000 characters.
3. ALPHANUM – this data type stores the alphanumeric characters. The number ranges from 1 to 127.
4. SHORT TEXT – this stores the variable-length character string that supports only text search features and a string value.
4. Binary data type:
Binary data types are used to store the only bytes of binary data values.
One type of binary data type is available:
a. VARBINARY: this stores the binary data values in bytes. Here the maximum length stored is 1 to 5000.
5. LARGE objects:
LARGE objects are used to store only a large amount of data like text document types and images.
1. NCLOB – this stores the large UNICODE character objects.
2. BLOB – this stores a large number of Binary data codes.
3. CLOB – this stores a large amount of ASCII data characters.
4. TEXT – this enables the text search engine features such as column data tables and row data values are not stored.
5. BINTEXT – this supports the text search features, but this is possible to only add binary data values.
6. MULTIVATED:
Here the multivated data types are mainly used to store the collection of data values with the same data type.
7. ARRAYS:
Arrays are used to store the group of data values. They also contain NULL values.
SAP HANA – Security overview
As we already know, all the technologies have come up with a lot of security methods. The main purpose of using security systems are used to protect their data. The SAP HANA system also helps customers to adopt different security procedures and policies. These security systems also help companies to meet compliance requirements. SAP HANA system supports multiple database systems in a single SAP system and this is known as multitenant database containers. This SAP HANA environment also contains more than one multitenant database container.
Below are a few security-related features,
1. User and Role management
2. Authentication and SSO methods
3. Authorization system
4. Data encryption to work with the communication network
5. Data encryption available in the persistence layer
Some of the additional features can also be used:
1. Database isolation: this involves preventing the cross tenant attacks through various operating system mechanisms.
2. System configuration change blacklist: this method involves preventing system properties that are being changed by tenant database administration management.
3. Restricted features: This security feature involves disabling certain database management features that offer direct access to the file system, other resources, and the network.
Related Articles SAP SD Sales Document Types !
Conclusion
This SAP HANA tutorial has been developed for anyone, who has basic SQL knowledge. Once you finish this HKR’s SAP HANA tutorial, you will be able to find yourself at a moderate level of SAP expertise in system administration and operations. With the help of this tutorial, you are also able to perform system implantation and SAP HANA data modeling. If you are not aware of any SQL relational database skills, then we recommend that you first go through HKR’s short tutorials on SQL technology.
About Author
Upcoming SAP Hana Training Certification Online classes
| Batch starts on 4th Aug 2026 |
|
||
| Batch starts on 8th Aug 2026 |
|
||
| Batch starts on 12th Aug 2026 |
|