
Teradata Tutorial
Last updated on Nov 20, 2023

What is Teradata?
Teradata is a relational database management system (RDBMS) that drives a company's data warehouse. The Teradata database is an open-source, compliant with industry ANGI standards. It runs on these industries standard operating systems like Microsoft Windows, enterprise servers, and Novell SUSE Linux. For this reason, Teradata is considered an Open Architecture. This Teradata database is one of the popular database servers that enable users to access Client data applications available from multiple data sources and also help them to solve the inquiries related to data applications.
Become a Teradata Certified professional by learning Teradata Training from hkrtrainings!
History of Teradata
Now I am listing all the major milestones of Teradata,
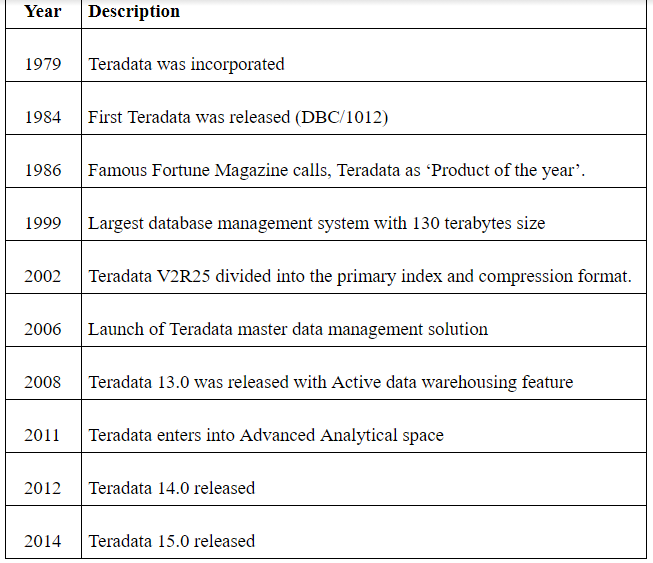
Teradata Architecture
Teradata is designed completely based on massively parallel processing architecture (MPP). Let me explain a few major components of Teradata Architecture,
Teradata Components
The following are the key components of Teradata;
Nodes: Nodes are the basic unit of Teradata units. An individual server in Teradata architecture is called a Node. Each node consists of its own OS operating system, CPU, memory, RDBMS's copy of data software, and disk space.
Parsing Engine: Parsing engine is used to receive the Queries from different client sources and prepare those Queries to make an efficient execution plan. Now see the main functions of Parsing Engine;
- Retrieve the SQL query form the client servers
- Pass these SQL queries to check for the syntax or any other errors
- Need to verify whether the user needed any privilege against the objects used in the SQL queries
- Now it checks if the SQL objects used exists
- It prepares the execution plans to execute the SQL query
- Finally, receive the result from AMP’s and send them back to the client.
- Message passing Layer: They are called BYNET, which is the network layer in the Teradata database system. The main purpose is to establish between PE, AMP, and also between the nodes. Then it receives the execution plan from the parsing engine and sends them to AMP.
- Access Module Processor (AMP): AMP's called Virtual Processors (vproc), the important Functions about AMP;
- it receives and passes the data to respected disks.
- AMP can read/write data from the particular disks.
Advantages of Teradata
As I said earlier, this Teradata has been designed to store and manage a large amount of complex data set in the system. It makes it easier to work with data warehousing in the RDBMS system. I would like to mention a few important advantages of using Teradata,
- Provide Top-level Scalability: Teradata has provided a special tool that counts the number of users and data required for any business operations.
- Unlimited Parallelism: Offers parallel across to data, sorts, and aggregations.
- Offers high-level optimizer: this optimizer mainly works to manage complex queries, add up to 64 queries/joins and process the ad-hoc data.
- Support a “ single unit/version of overall business application management”
- The low-cost ownership: easy to set-up, maintenance, administration, no reorganizing, and robust expansion.
- Provides parallel loads and unloads utilities.

Teradata Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project-Based Learning
Installation of Teradata
Teradata is a fully operational database server virtual machine adopted on the base of VMWARE software.
Requirements: Virtual machine 64 bits and CPU of 64 bits.
Steps:
1) Download the latest version of VM ware
2) Extract the execution file and save it in any folder.
3) You need to download the VMWare workstation player
It is available for both Linux operating systems and Windows OS.
4) Once you finish the download and install the software.
5) After the installation is done, run the VMWare client-server.
6) Select-> Open a virtual Machine-> it will navigate through the already extracted executed folder -> now choose the file with ext.VMDK.
7) Teradata VMware is now added to the VMWare Client-> click on the added Teradata VMware-> Click on the ‘Play Virtual Machine’.
8) If you see any popup on software updates->select ‘Remind me later’
9) Now enter the username (or root name) -> then press on tab -> enter the user password -> finally press enter.
10) Double click on ‘root’s name’-> again double click on ‘Genome’s terminal’-> it will open the shell,
11) Now enter the command /etc/init.d/tpa start-> this will start the Teradata server.
Teradata Relational Concepts
The relational Database management system is database management software that interacts with the database from multiple servers. They usually use the sequential query language (SQL) to store the data in RDBMS.
Database: Database is a collection of relatively logical database sets. Many users can access these data for multiple purposes.
For example, a sales and marketing database contains information about sales and customers that is stored in many database tables.
Tables: Table is the main component in the Relational database management system (RDBMS) which is used to store the data. These tables are consist of Columns and Rows as shown in the figure,
Columns: Columns contain similar data as same as table database. For example, if you add employee salary details, that will be stored like this,
Rows: Row is just an instance of the entire column database. For example, one row contains single employee details like,

Primary Key: The primary key is used for the unique identification of row in a table. The main thing is that no duplicate values are allowed in a table row. They never accept the NULL values in the row. The primary key is the compulsory field in the table database.
Foreign key: Foreign keys are mainly used to establish a relationship between the table databases. In the tree hierarchy of the table, a foreign key in the child table can be considered as a primary key in the parental table. A table can consist of multiple foreign key values. It allows duplicate values and also you can add null values. These keys are the optional ones in the table database creation.
That’s it about Teradata relational concepts.
Check out here for frequently asked Teradata interview questions & answers
Teradata Datatypes
Teradata datatypes help the user to add what kind of data values that can be stored in Column. Teradata supports several data types associated with the columns.
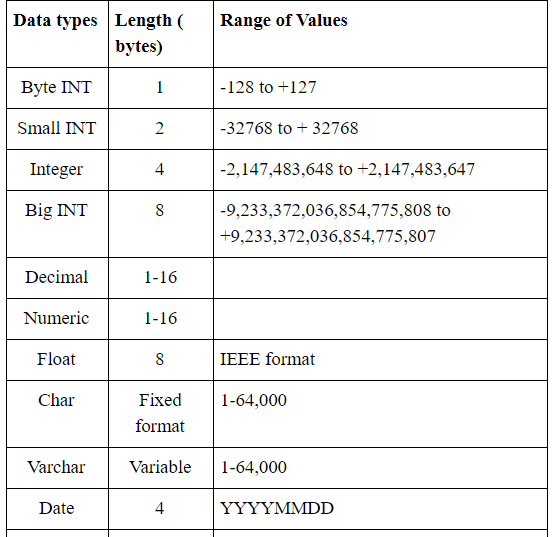
Table to be continued

Teradata Tables
Tables in Teradata nothing but the collection of data. We can create a table with the help of the Number of rows and columns.
Types of Teradata Tables:
1) Permanent table: This permanent table is a default table and it contains the user-created data and stored them permanently.
2) Volatile Table: The data added to the volatile table can be retained only during the user session. This table data is dropped only at the end of the session. These tables are used to hold the intermediate data during the data transformation.
3) Global Temporary table: In the Global temporary table, table data is deleted at the end of the user session.
4) Derived Table: This Derived table can be used to store the intermediate results in the queries. The life span of this table within the query in which the query is created, used and dropped.
Table data is classified into SET and MULTISET, the SET data set doesn't hold the duplicate records, where the MULTISET table can hold the duplicate records.
Table commands and Description
a) Create Table: Create table command is used to create tables in the Teradata. The syntax is as follows,
CREATE
Table option: this table option specifies the physical attributes that contains journal and fallback.
Column definition: Column Definition specifies the list of columns, data types, and their attributes.
Index Definition: this consists of a primary index, secondary index, and partitioned primary index.
b) ALTER Table: Alter table command is used to add or drop the columns from an already existing table. Users can use the Alter table command to modify the attributes in the existing columns.
Syntax:
ALTER TABLE
ADD
DROP
c) DROP Table: DROP table is used to drop the table. When you will get an issue in table drop, you need to delete the table data, and then drop the table.
Syntax:
DROP TABLE;

Subscribe to our YouTube channel to get new updates..!
Teradata Operators
There are two types of operators available; they are Logical and conditional operators. These operators perform the comparison and combining multiple data conditions tasks in the database management.
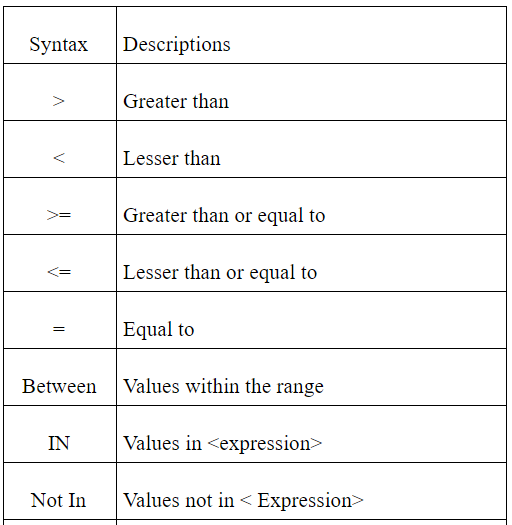
Table to be continued
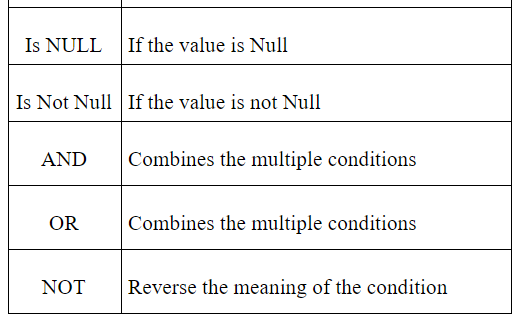
For example:
BETWEEN: This BETWEEN commands are used to check if a value is within a range of values.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN … AND …;
IN: this command is used to check the value against a given list of values.
For example:
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (…,…,…);
NOT IN: This command reverses the result of IN command. It fetches records with values that don’t match with the given list.
For example:
SELECT * From
Employee
Where EmployeeNo not in (…,..., …);
SET operators:
The SET operator is used to combine the result from multiple SELECT statements. Where SET operators combine the rows from multiple rows.
Rules you should follow while working with SET operators:
- The number of columns from each SELECT statement should be the same.
- The data types from each SELECT must be compatible.
- ORDER BY should be included only in the final SELECT statement.
UNION: Union statement is used to combine results from multiple SELECT statements. It doesn’t calculate the duplicate value.
Syntax:
SELECT col1, col2, col3…
FROM
[Where condition]
UNION
SELECT col1, col2, col3..
FROM
[WHERE condition];
UNION ALL:
UNION ALL combines the results from multiple tables including duplicate rows.
Syntax:
SELECT col1, col2, col3..
FROM
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
[WHERE condition]
Related Article:CSUM in Teradata
INTERSECT:
INTERSECT command is used to combine results from multiple SELECT statements. It returns the rows from the first SELECT statement that has a corresponding match in the second SELECT statement.
Syntax:
SELECT col1, col2, col3,
FROM
[WHERE condition]
INTERSECT
SELECT col1, col2, col3..
FROM
[WHERE condition];
MINUS/EXCEPT: This command combines the rows from multiple tables and returns the rows which are in the first SELECT but not in the second SELECT.
Syntax:
SELECT col1, col2, col3,
FROM
[WHERE condition]
MINUS
SELECT col1, col2, col3,
FROM
[WHERE condition];
Teradata Functions
Teradata supports many built-in functions to perform specific tasks or operations.
Count – this counts the rows
Sum – Sums up the values of the specified columns
Max- this returns the large value of the specified columns
Min- this returns the minimum value of the specified column
AVG – this returns the average value of the specific columns.
Let me explain one by one,
COUNT:
Syntax:
SELECT count (*) from row name;
………..
MAX:
Syntax:
SELECT max (NetPay) from row name;
………
MIN:
Syntax:
SELECT min (NetPay) from row name;
………..
AVG:
Syntax:
SELECT avg (NetPay) from row name;
…………..
SUM:
Syntax: SELECT sum (Net Pay) from row name;
……………
Built-in functions example:
The following are the few examples for built-in functions and they are the extensions to SQL query language.
1) SELECT;
2) SELECT DATE;
3) SELECT CURRENT_DATE;
4) SELECT TIME;
5) SELECT CURRENT_TIME;
6) SELECT CURRENT_TIMESAMP;
7) SELECT DATABASE;
TERADATA CASE and COALESCE functions:
I will explain one by one with an example,
CASE function: This CASE expression check each row again the condition (WHEN clause) and it will return the result of the first match. If no condition matches, it will abort the loop.
Syntax:
CASE
WHEN
WHEN
ELSE
Result-n
END
COALESCE function:
This COALESCE function first returns the non-null value. If all the arguments are NULL value, it returns the whole expression as a NULL,
Syntax:
COALESCE (expression 1, expression 2, ….)
Advantages of using Teradata over another database system:
Here I would like to mention a few advantages of using Teradata over another database system,
- Easy to use.
- It’s very easy to understand
- It models the business not the process
- Offers data-driven technology versus application-driven
- It makes the application easier to build
- Supports trend towards end-user computing
- Allows businesses to respond to changing conditions more flexibly than other types.
Conclusion
In this article, I have tried to explain the basic concepts of Teradata and its uses in a relational database management system. As I have explained, Teradata is one the easiest database management tools that supports user to create a large amount of data set and also help users to perform data warehousing operations. Even no-programmer or non-technical people can learn this technology without having any programming experience. I hope this blog may help a lot of people who have a desire to learn this tool and also for Teradata Community Forums.
Other Related Articles :
About Author
Upcoming Teradata Training Online classes
| Batch starts on 30th Jul 2026 |
|
||
| Batch starts on 3rd Aug 2026 |
|
||
| Batch starts on 7th Aug 2026 |
|