
AB Initio Tutorial
Last updated on Nov 23, 2023

Ab Initio Tutorial - Table of Content
- AB Initio Introduction
- AB Initio Overview
- AB Initio Architecture
- Differences between ETL and BI
- Application integration implementation using AB Initio
- Functions of AB Initio system tool
- Advantages of AB Initio methods
- ETL process overview
- ETL tool functions
- ETL testing – tasks to be performed
- AB Initio- ETL testing categories/a>
- AB Initio ETL testing techniques overview
- Ab initio- Automation process
- Conclusion
AB Initio Introduction
AB Initio Software, an esteemed MNC based in Lexington, Massachusetts, stands out in data management. Renowned as a robust ETL (Extract, Transform, Load) testing tool, AB Initio integrates six core components. These include the cooperating systems, component library, graphical development environment, enterprise meta environment, data profiler, and conduct environment setup. Praised for its powerful, GUI-based parallel processing capabilities, AB Initio excels in ETL data management and analysis. Also, it adeptly handles diverse data sources within data warehouse apps. Its ETL process encompasses three pivotal operations:
- Data Extraction: Efficiently pulls data from various transactional systems like Oracle, IBM, and Microsoft.
- Data Transformation: Implements data cleansing to prepare data for data warehouse systems.
- Data Loading: Seamlessly loads processed data into OLTP data warehouse systems.
To gain in-depth knowledge with practical experience, then explore Ab Initio Training
AB Initio Overview:
AB Initio, more than just software, is a complete suite of data management apps, primarily known for its flagship AB Initio cooperating system. Characterized by a user-friendly graphical interface, this ETL tool simplifies complex data processes through intuitive drag-and-drop functionalities. It is especially effective in handling vast data volumes, leveraging parallel processing for optimum efficiency. Key components include the Cooperation System, Enterprise Meta Environment (EME), various data tools, a data profiler application, and the PLAN IT system.
AB Initio Architecture:
Ab initio architecture explains the work nature and overall structure of the ETL tool:
The architecture of AB Initio, embodying the essence of "beginning from the start," operates on a client-server model. The client side, the Graphical Development Environment (GDE), resides on the user's desktop, while the server side, the cooperating system, functions on a remote mainframe or UNIX machine. AB Initio's code, typically called a graph (with a .mp extension), requires GDE for deployment in .ksh (K-shell) format.
The below diagram explains the Ab initio architecture in detail:
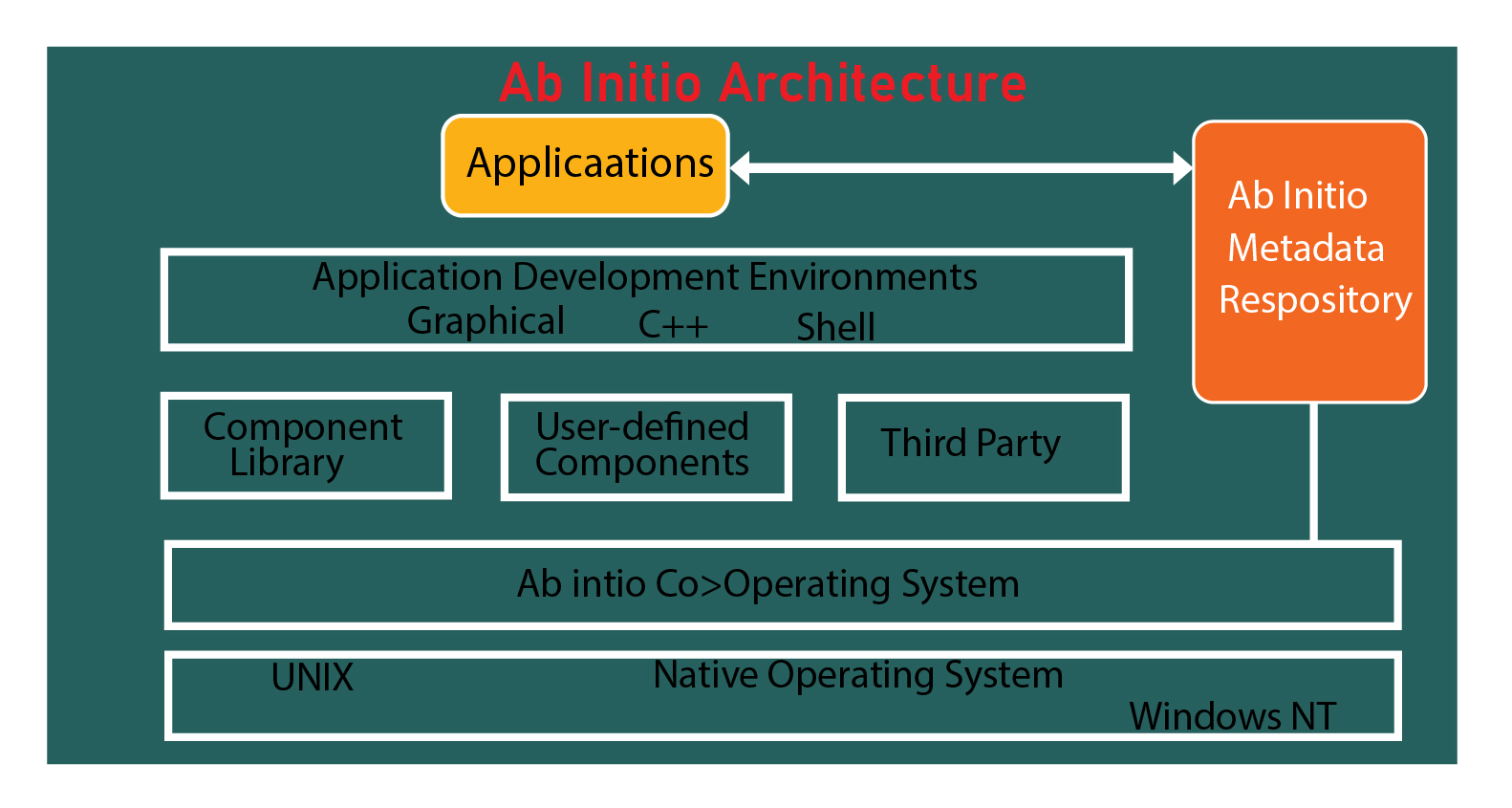
The cooperating system executes these .ksh files, which is crucial in task execution. As an evolving ETL tool vendor, AB Initio is making significant strides in application data integration, offering solutions for data warehousing, real-time analytics, CRM, and enterprise application integration. Its robust architecture ensures fast, secure, and efficient data integration across complex data streams.

Ab Initio Training
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
Differences between ETL and BI:
ETL tools and BI tools, though similar in data handling, serve distinct functions:
ETL Tools:
These tools focus on extracting, transforming, and loading data into warehouse systems. Examples include SAP BO Data Services (BODS), Informatica PowerCenter, Oracle Data Integrator (ODI), and CloverETL.
BI Tools:
They aimed at producing interactive reports, dashboards, and data visuals for end-users. Popular BI tools include SAP Business Objects, IBM Cognos, and Microsoft BI platforms.
Application integration implementation using AB Initio:
AB Initio streamlines the integration of disparate data sources into data warehouses and CRM apps. It addresses challenges like data source diversity, complex business logic, and redundancy. The tool's scalable solutions facilitate the transformation of varied data into a unified format, supporting data warehousing and BI operations.
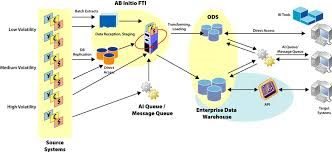
The major challenges included are:
1. Multiple sources: here data available from different sources like mainframes or oracle tables using different techniques, and data formats with different load frequencies.
2. Complex business logic: here you are going to achieve the data format with target systems, data cleansing techniques, and generic entities.
3. Redundancy: multiple data source truth because of data duplications.
With the help of ab initio, a cost-effective system solution can offer batch or real-time execution mechanisms. Here the scalable solution that extracts the data from distributed systems transforms multiple data formats into a common format, this creates the data warehouse, operational data stores, and aggregation or derivation of business intelligence, and loads the data into target systems.
Functions of AB Initio system tool:
AB Initio excels in several key functions:
- Loading data into operational data stores.
- Utilizing a metadata-driven rules engine.
- Providing PAI facilities for query operations.
- Offering a graphical interface for data extraction and loading.
- Supporting delta and before-after data imaging.
- Feeding data to target systems and reporting tools.
Advantages of AB Initio methods:
AB Initio offers significant advantages, particularly in understanding protein folding mechanisms and misfolding, and is crucial for de novo protein design.
1. Ab initio can give insights into folding mechanisms.
2. Helps in the understanding of protein misfolding.
3. Does not require homologs techniques.
4. Only way to model new data folds.
5. Ab initio model is useful for de novo protein design.
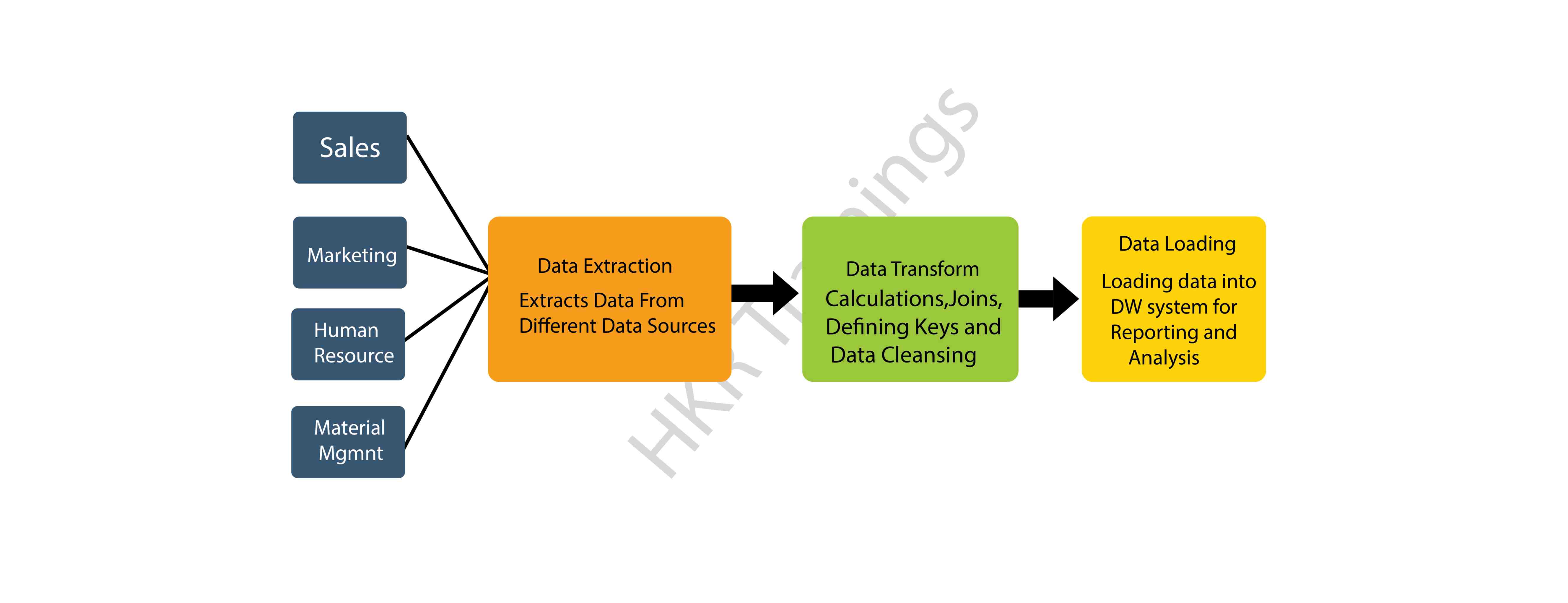
ETL process overview:
The ETL process involves three critical stages:
- Extracting Data: Involves data extraction from heterogeneous sources, often scheduled during off-business hours.
- Transforming Data: Focuses on data format conversion, error correction, and data integration.
- Loading Data: Entails loading transformed data into various data warehouse systems for analytical processing.
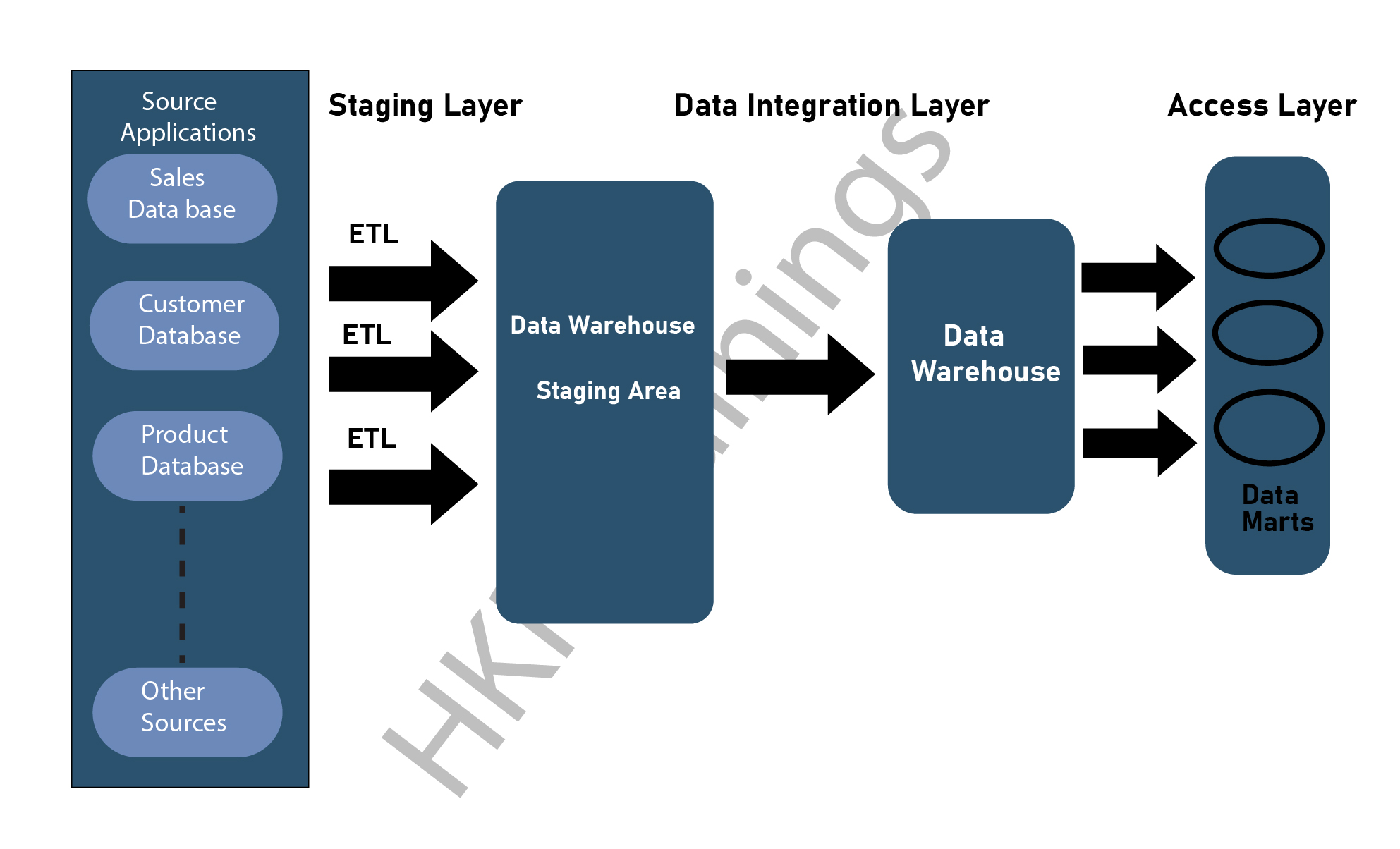
ETL tool functions:
The ETL tool's architecture comprises staging, data integration, and access layers, each playing a vital role in data handling and integration.
1. Staging layer: the staging layer or staging database is used to store the data which is extracted from different data source systems.
2. Data integration layer: The data integration layer transforms the different data from the staging layer and transfers them to a database, here data will be arranged into a hierarchical group is known as dimensions and converted into facts or aggregate facts. This combination of aggregated facts and dimension tables in a data warehouse table is known as a schema.
3. Access layer: this access layer is mainly used by end-user to retrieve the data for data analytical reporting and information storage.
The below diagram explains the functions of the ETL tool:
ETL testing – tasks to be performed:
ETL testing, crucial for data integrity, involves tasks like data model review, schema validation, data verification, and more, differing significantly from standard database testing.
In ETL testing important tasks to be performed:
1. Understanding the data to be used for analytical and reporting purposes.
2. Review the data model architecture
3. Source to perform target mapping
4. Helps to check the data on various sources.
5. Schema and packaging validations
6. Helps to perform data verifications in the target data source system
7. Verification of data transmission, calculations, and aggregation rules.
8. Sample data comparison between any source system and the target system
9. Data integration and data quality checks in the target system source.
10. Helps to perform various data testing
Frequently asked Ab Initio Interview Questions
Subscribe to our YouTube channel to get new updates..!
Now it’s time to know the difference between ETL testing and database testing:
Both ETL testing and database testing involve data validation operations. But these two testing techniques are not the same. ETL testing is mainly used to perform on the data sources in the data warehouse system. Database testing is performed on the transactional system source here the data comes from various different applications into the transactional database.
ETL testing involves the below operations:
1. Perform data validation movements from the source system to the target system.
2. Verification of multiple data counts in the source system and the target system.
3. Verifies the data extraction, data transmission as per the requirements.
4. Verifying the table relations like joins and keys are preserved during the time of data transformation.
Database testing performs the following operations:
1. Verifies and maintains the primary and foreign keys.
2. Verifying the data column in a database table that contains valid data values.
3. Verifying the data accuracy in data columns. For instance: the number of months column should not exceed a value greater than 12 months.
4. Verifying the missing data values in the column. This is used to check if there are any null values present or not.
AB Initio- ETL testing categories:
AB Initio ETL testing encompasses a range of categories, including source-to-target count testing, data mapping, end-user testing, retesting, and system integration testing. Let us discuss them in brief.
1) Source-to-Target Count Testing:
This testing verifies the count of records, ensuring the number of data rows in the source matches the count in the target system after ETL processing.
2) Data Mapping Testing:
Focuses on ensuring that data transformation and mapping from the source to the target system adhere to the specified needs and business logic.
3) End-User Testing:
It involves validating the data and its functionality from the end-user's perspective. Also, it ensures that the data presented in reports and dashboards meets user needs and expectations.
4) Retesting:
Conducted after bug fixes or modifications, this testing ensures that the issues identified in earlier tests have been resolved and that the changes haven't introduced new problems.
5) System Integration Testing:
Tests the ETL process in the context of its interaction with other systems, verifying that integrated components function together as intended and data flows correctly across system boundaries.
AB Initio ETL testing techniques overview:
Essential testing techniques in AB Initio ETL include production validation testing, source-to-target data testing, data integration testing, application migration testing, data quality testing, and more, each addressing specific data integrity and efficiency aspects.
1. Production validation testing:
This type of testing technique is used to perform analytical data reporting and analysis function, and also checks for the validation data production in the system. The production validation testing can be done on the data that is moved to the production system. This technique is considered to be a crucial testing step as it involves a data validation method and compares these data with the source system.
2. Source to target count testing:
This type of testing can be performed when the test team has less to perform any type of testing operations. The targeted testing checks the data count in the source as well as target systems. One more point to be considered here is it doesn’t involve ascending or descending the data values.
3. Source to target data testing:
In this type of testing, a test team involves invalidating the data values from the source system to the target system. This checks the corresponding data values also available in the target system. This type of testing technique is also time-consuming and mainly used to work on banking projects.
4. Data integration orb threshold value validation testing:
In this type of testing, a test team will validate the data ranges. All the threshold data values in the target system will be checked if they are expecting the valid output. With the help of this technique, you can also perform data integration in the target system where data is available from the multiple data source system once you finish the data transmission and loading operations.
5. Application migration testing:
Application migration testing is normally performed when you move from an old application to a new application system. This type of testing saves a lot of your time and also helps in data extraction from legacy systems to a new application system.
6. Data check and constant testing:
This testing includes the various types of checks such as data type check, index check, and data length check. Here the testing engineer performs the following scenarios- primary key, foreign key, NULL, Unique, and NOT NULL checks.
7. Duplicate data check testing:
This testing technique involves checking for the duplicate data situated in the target system. When there is a huge amount of data residing in the target system. It is also possible that there are also duplicate data available in the production system.
The following SQL statement used to perform this type of testing technique:
Select Customer_ID, Customer_NAME, Quantity, COUNT (*)
FROM Customer
GROUP BY Customer_ID, Customer_NAME, Quantity Having COUNT (*) > 1;
Duplicate data appears in the target system because of these reasons:
1. If no primary key is specified, then the duplicate values may come.
2. This also arises due to incorrect mapping and environmental data issues.
3. Manual errors arise while transferring data from the source system to the target system.
8. Data Transformation testing:
The data transformation testing is not performed by using any single SQL statement. This testing technique is time-consuming and also helps to run multiple SQL queries to check for the transformation rules. Here the testing team needs to run the SQL statement queries and then compare the output.
9. Data quality testing:
This type of testing includes operations like number check, date check, null number check, and precision check, etc. Here the testing team also performs syntax tests to check any invalid characters and incorrect upper or lower case order. Reference tests also are done to check if the data is available according to the data model.
10. Incremental testing:
Incremental testing can be performed to verify if the data insert and update the SQL statements. These SQL statements are executed as per the expected results. This testing technique is performed step by step with old and new data values.
11. Regression testing:
When you make changes to any data transformation and data aggregation rules used to add new functionality. This also helps the testing team to find a new error is called regression testing. The bug also comes in regression testing and this process is known as regression.
12. Retesting:
When the test team runs the tests after fixing any bugs is called retesting.
13. System integration testing:
System integration testing includes the testing of system components and also integrates the modules. There are three ways of system integration available such as top-down, bottom-up approach, and hybrid method.
14. Navigation testing:
Navigation testing is also called front-end system testing. This involves the end-user point of view testing can be performed by checking all the aspects such as various fields, aggregation, and calculations.
Ab Initio –ETL process
The ETL process in AB Initio involves understanding business needs, test planning, creating test scenarios, and executing test cases, culminating in a complete test summary report.
Below are the common steps included in the ETL life cycle:
1. Helps in the understanding of the business requirements
2. Validation of the business requirement process.
3. Test estimation step is used to provide the estimated time to run the test cases and also completes the test summary process report.
4. Test planning methods involve finding the testing techniques based on the data inputs as per the business requirements.
5. Helps in the creation of test scenarios and test cases.
6. Once the test cases are ready to perform testing and approved, the next step is to perform any pre-execution check.
7. Enables you to execute all the test cases.
8. The last and final step to create a complete test summary report and file a closure test process.
Ab initio- Automation process
AB Initio ETL testing automation leverages tools like Query Surge and Informatica Data Validation, enhancing efficiency and accuracy.
Query Surge process:
Query surge is nothing but a data testing solution that is designed to perform big data testing, data warehouse testing, and the ETL process. This process can automate the entire test process and fit nicely into your DevOps strategy.
The key feature of query surge is as follows:
1. It consists of query wizards to generate test Query pairs fast and easily without having to write your SQL statements.
2. This has a design library with reusable query snippets. Also, you can generate custom query pairs.
3. This process can compare data values from source files and data stored in the target data warehouse of big data.
4. This can also compare the millions of rows and columns of data values in minutes.
5. Query surge also allows the user to schedule any tests to run immediately at any time or date.
6. This can also produce informative data reports, view data updates, and auto email the result of your team.
To automate any process, the ETL tool should start with query surge using command API once this completes the ETL software load process. The query surge process runs automatically and the UN attends and executes all the test processes.
Informatica data validation process:
Informatica data validation offers an ETL testing tool that helps the testing team to accelerate and automate the ETL testing process during the time of development and production environment. This validation process helps you to deliver, complete, repeatable, and auditable test coverage in less time duration. And this validation process does not require any programming skill sets.
Conclusion:
In this ab initio tutorial, we have explained the architecture overview, definition, integration, automation process, ETL function tool, ETL work nature, and testing techniques. Learning this Ab initio testing tool will help you to become a master in automation and ETL tools. This ab initio tool helps you to correct invalid data fields, and apply calculations. The ab initio tutorial is specially designed for those who want to begin their career in ETL testing. And this also is useful for those software testing professionals who are willing to perform data analysis to extract processes. Our technical team provides 24/7 online support for these course-related doubts.
About Author
Upcoming Ab Initio Training Online classes
| Batch starts on 14th Jul 2025 |
|
||
| Batch starts on 18th Jul 2025 |
|
||
| Batch starts on 22nd Jul 2025 |
|