
Mainframe Tutorial
Last updated on Jun 12, 2024

What do you know about the framework?
The mainframe is an industry-related term for a large computer. The name comes from the way the machines build-up: all units like data processing and communication etc, these units will be combined into a frame. Thus the name is given as software framework. Mainframe computers are power computers used primarily by corporate and governmental organizations for critical applications, bulk data, and processing millions of records each day such as census industry and customer statistics, enterprise resource planning, and transaction processing.
What are the benefits of the mainframe?
The following are the key benefits of using a framework:
1. Mainframe software is cost-effectively provided for an attractive computer architecture that will continue to thrive for the foreseeable future.
2. It offers a comprehensive solution to all the major problems.
3. It is thus likely that the most robust and flexible computing environments of the future will be a combination of both mainframe and client/server architecture.
4. Large organizations with existing reliable mainframe systems and employees who are trained on them will continue to use them for many years to come.
5. Mainframes based companies like HSBC, Accenture, RBI, SATYAM, CSC, and TATA group of companies.
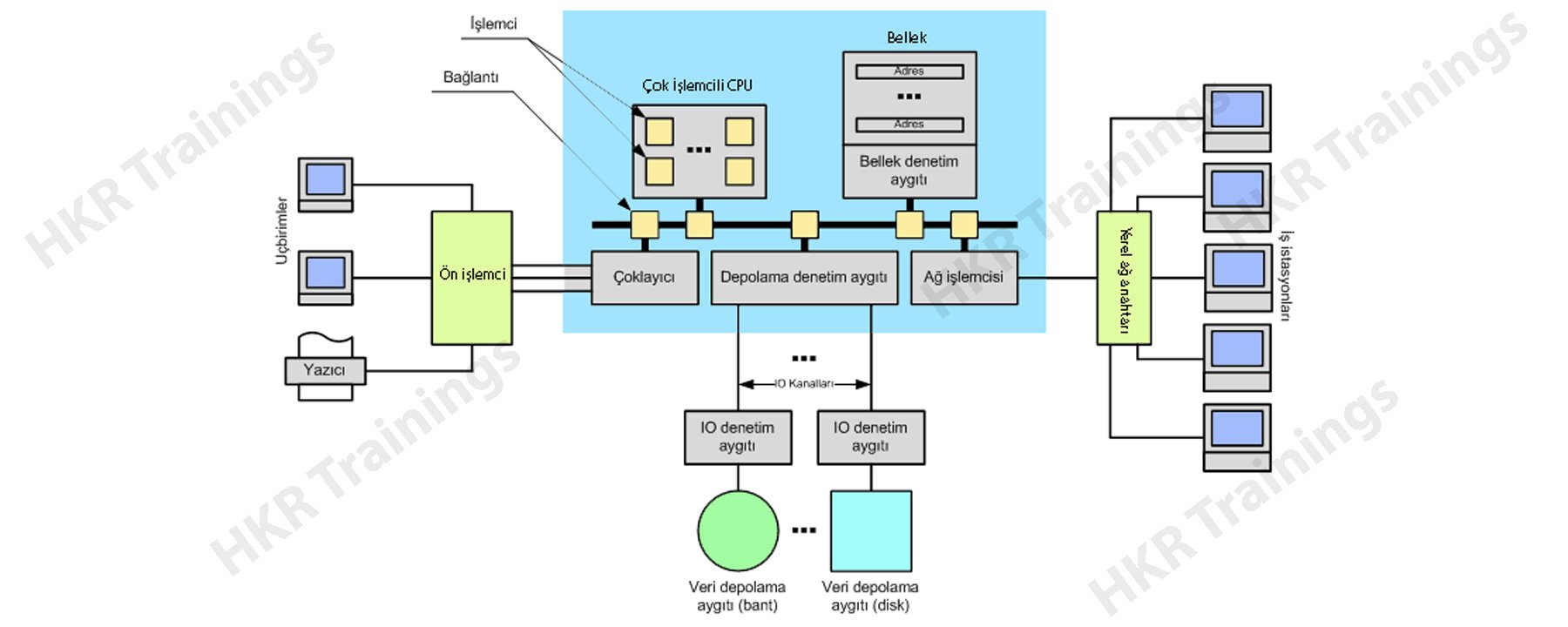
Mainframe Architecture:
Mainframe architecture is a set of rules and components which are used to define the overall structure of the software technology.
The following diagram explains this,
Mainframes are arrived in the year 1960s and now popularly known as “big iron machines”. Before they were used as a small machine, each new generation framework has come up with advanced improvements. The following are the key features of the mainframe they are;
1. New generation framework consists of more and faster processors.
2. Come up with more effective physical memory and greater memory addressing capability.
3. Supports dynamic capabilities for upgrading both software and hardware systems.
4. Increased automation of hardware error checking and recovery facility.
5. Offers enhanced software devices for both input and output between I/O devices and main processors.
6. Provides advanced clustering technologies, they are like parallel Sysplex, and also share a large amount of data among multiple systems.
Different types of mainframe tools
1. CICS:
CICS stands for customer information control system. This tool was developed by IBM in 1968. CICS is a transaction processing system this is also known as online transaction processing (OLTP) software. CICS is also called a data communication system that supports thousands of hardware networking terminals.
Overview of CICS:
CICS is a DB/DC system type that is used in main online applications. The main purpose of developing CICS is to execute only batch programs. CICS programs can be written using programming languages like C, C++, COBOL, and JAVA. CICS allows users to communicate well with the back-end systems, for example, flight reservations.
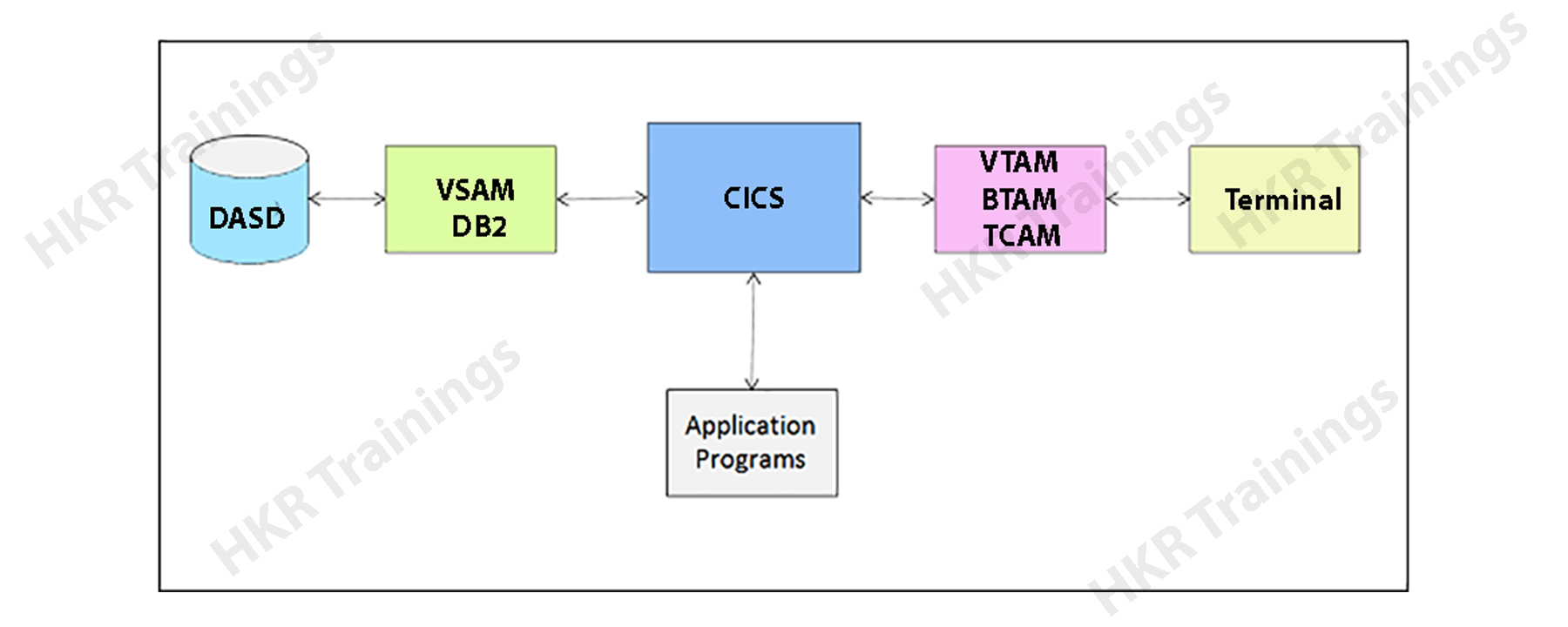
Functions of CICS:
1. CICS manages several requests from concurrent end-users in any application.
2. Although suppose if the multiple users working on CICS system, but it always gives feel that only a single user is working on CICS.
3. CICS helps to access the various data files which are used for reading and updating in an application.
CICS features:
1. CICS is also a type of an operating system, and it manages its processor storage, own task manager. This also handles the multiple program execution and offers its own file management functions.
2. CICS also offers an online environment only in a batch operating system, faster jobs submissions, and executed quickly.
3. It is also possible to have more than two CICS regions at the same time. CICS acts as a batch job in the operating system.
4. CICS also supports generalized online transaction process interfaces.
CICS Environment:
Following are the various services offered by CICS:
1. System services:
CICS maintains the control functions to manage the memory allocation and deallocation of the various resources. In this CICS system service, there are 4 types of controls available such as task control, program control, interval control, and storage control.
2. Data communication services:
CICS data communication service offers an interface with the help of several telecommunication access methods like BTAM, TCAM, and VTAM. CICS releases several application programs from the terminal hardware issues with the help of Basic mapping support (BMS). CICS system also offers the multi-region operations (MRO) to communicate with multiple CICS regions. With the help of Intersystem communication (ISC) users can communicate with the CICS region on another system.
3. Data handling services:
Data handling services act as an interface between different data access methods like BDAM, and VSAM, etc. CICS offers servicing data handling requests from application programs. This type of data handling service helps application programmer to set a lot of commands to deal with data set, database access, and related operations. There are various types of data handling interfaces available such as IMS, DB, and DB2.
4. Application programming services:
The application programming services of CICS offer features like command-line interface, CEDF (is also known as debugging facility), and CECI (also known as Command interpreter facility).
5. Monitoring services:
Monitoring services in CICS monitor various events along with address space. This service provides serious statistical information that will be used for system tuning.
2. COBOL tool:
COBOL stands for Common business-oriented language. This language was previously developed by the US defense department for processing business data is popularly known as COBOL.
COBOL is used for writing programs for various applications. With the help of COBOL no need to write programs on system software. The applications included are the defense domain and insurance domain.
COBOL is a high-level programming language and anyone can understand how COBOL works. Here COBOL code was initially converted into machine code with the help of the compiler. Compiler helps to run the program and check for any syntax errors. Then converts them into machine language and the final output is known as the load module. The output will be available in binary form (0s and 1s).
Importance of COBOL:
1. COBOL was the first-ever widely used high-level programming language. This is kind of English like language and user friendly. All the instructions can be coded in simple English language terms.
2. COBOL is also known for its self-documentation process.
3. COBOL language is designed to handle huge data processing.
4. COBOL is compatible with the previous versions.
5. COBOL has an effective error message and resolution of any bugs or ticket is easier.
Features of COBOL:
Below are the important key features of COBOL:
1. Standard language:
As I said earlier, COBOL is a standard language that can be compiled and executed on computer machines namely IBM AS/400 and personal computers.
2. Business-oriented:
COBOL was mainly designed for business-oriented applications related to the defense domain and financial domains. This language can handle huge volumes of data due to its advanced file handling capabilities.
3. Robust language:
COBOL is a robust language because of its numerous debugging and testing tools which are available for almost all computer platforms.
4. structured language:
In COBOL, there are lots of logical control structures are available. These logical structures make it easier to read and modify different divisions and make it easy to debug.
COBOL program structure:
Below is the program structure of COBOL:
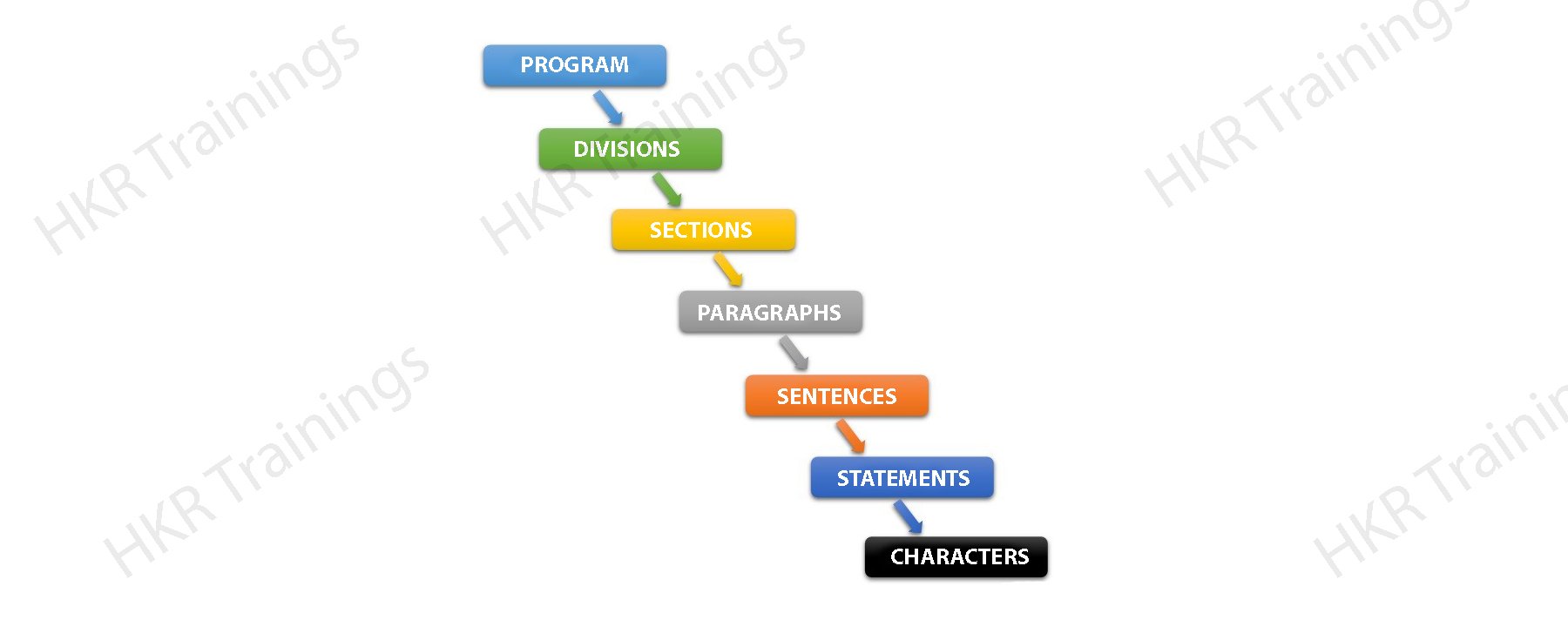
Let me explain each section briefly:
1. Sections: sections are the logical subdivision of program logic. A section is nothing but a collection of paragraphs.
2. Paragraphs: paragraphs are the subdivision section or division. It is either a user-defined or a predefined user name followed by a period, or sentences/ entries.
3. Sentences: sentences are nothing but a combination of one or more statements. The sentences appear only in the procedure type. Any sentence should end with a period.
4. Statements: statements are meaningful COBOL statements and perform processing.
5. Characters: characters are the lowest hierarchy level section and which cannot be divisible.
DB2:
DB2 is one of the popular database products developed by IBM. This is a relational database management system or RDBMS. DB2 is designed to store, retrieve, and analyze the data. DB2 products are providing extended support for object-oriented features and Non-relational XML structures.
History of DB2:
At an earlier stage, IBM had developed the DB2 product to work on specific platforms. In the year 1990, IBM decided to develop a universal database (UDB) DB2 server. So this universal database product can run on any operating systems like LINUX, UNIX, and Windows.
Versions:
The current version of the DB2 version we are using is 10.5 with advanced features like BLU accelerations and the code name is known as “Kepler”. Below are a few versions:
3.4 version -> code name “cobweb”
8.1, 8.2 version -> code name “stinger”
9.1 versions -> code name “viper”
9.5 versions -> code name “viper2”
9.7 version -> code name “cobra”
9.8 version -> this version added features with only pure scale.
10.1 versions -> code name “Galileo”
10.5 versions -> code name “Kepler”
Data server editions and features:
Below are the data server editions and features:
1. Edition name = Advanced enterprise server edition and enterprise server edition (AESE /ESE)
Features:
It is designed for mid-size to large scale business organizations platforms like Linux, UNIX, and Windows. Table partitioning high availability disaster recovery (HARD), materialized query table (MQTs), multidimensional clustering (MDC), connection concentrator pure XML backup compression homogeneous federations.
2. Edition name = Workgroup server edition (WSE)
Features:
This is designed for workgroup or mid-size business organizations. Using WSE or Workgroup server edition users can work with- high availability disaster recovery (HARD), online reorganization pure XML, web service federation, support DB2 homogeneous federations homogeneous SQL replication backup compression facility.
3. Edition name = Express –c
Features:
It offers all the capabilities of DB2 at zero change. This can run on any physical or virtual systems with any size configuration.
4. Edition name = Express Edition
Features:
This version is designed for entry-level and mid-size business organizations. It is full-featured DB2 data server. It offers only limited services. This edition comes with web service federations, DB2 homogeneous federations, homogeneous SQL replications, and backup compression.
5. Edition name = Enterprise developer
Features:
This edition offers only a single application developer. It is useful to design, build, and prototype the applications for deployment on any of the IBM servers. The software cannot be used for developing applications.

Mainframes Training Certification
- Master Your Craft
- Lifetime LMS & Faculty Access
- 24/7 online expert support
- Real-world & Project Based Learning
DB Architecture:
The below diagram explains the overall structure of DB:
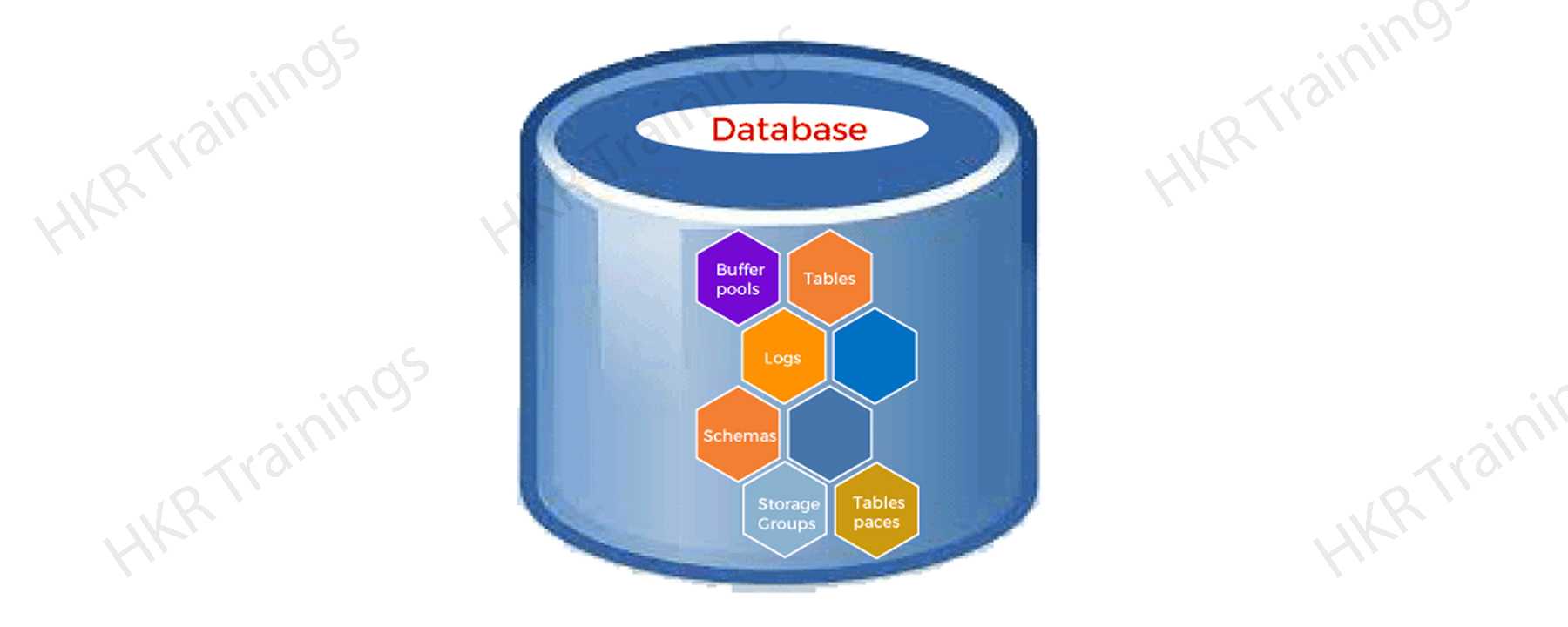
Database directory:
A database directory is a type of organized repository of various databases. Once you create a database, all the required details about database will be stored in a database directory. The details included are default storage devices, temporary tables list, and configuration files, etc.
In this database directory, the partial global directory is created in the instance folder. This database directory contains information that is related to the database. The partial global directory is named as a NODExxxx/SQLyyyy. Where XXXX is the data partition and yyy is the SQL database token.
How to create a Partitioned global directory?
1. Go to the directory location:
The partition global directory consists of database related files they are listed below:
a. Global deadlock write-to-file event monitoring file type.
b. Table space information related files [SQLSPCS.1, SQLSPCS.2]
c. Storage control files [SQLSGF.1, SQLSGF.2]
d. Temporary table storage container files. This file will be stored in [/storage path/T000011/C00000.TMP/SQL00002.MEMBER0001.TDA]
e. Global configuration file [SQLDBCONF]
f. History files [DB2RHIST.ASC, DB2RHIST.BAK, and DB2TSCHG.HIS]
g. Automatic storage containers.
The syntax used to create a database:
Db2 create database
Where database_name indicates the new database name, you are going to create it.
Create a restrictive database:
Db2 create database
Where db_name indicates the database name.
IMS DB tool:
IMS stands for the Information management system. IMS was first developed by IBM with Rockwell and Caterpillar in the year 1966 for the Apollo moon mission. This type of IMS offers easy to use, reliable, and standard environment facility for executing high-performance data transactions. IMS DB tool is used by high-level programming languages such as COBOL to store the data for hierarchical arrangement and access them.
Overview of IMS DB tool:
A database is a collection of related data items. These data items are stored and organized in order to provide fast and easy access. IMS database is a kind of hierarchical database where different types of data are stored at different levels and each hierarchical entity is dependent on the higher-level entity.
The following figure explains this:
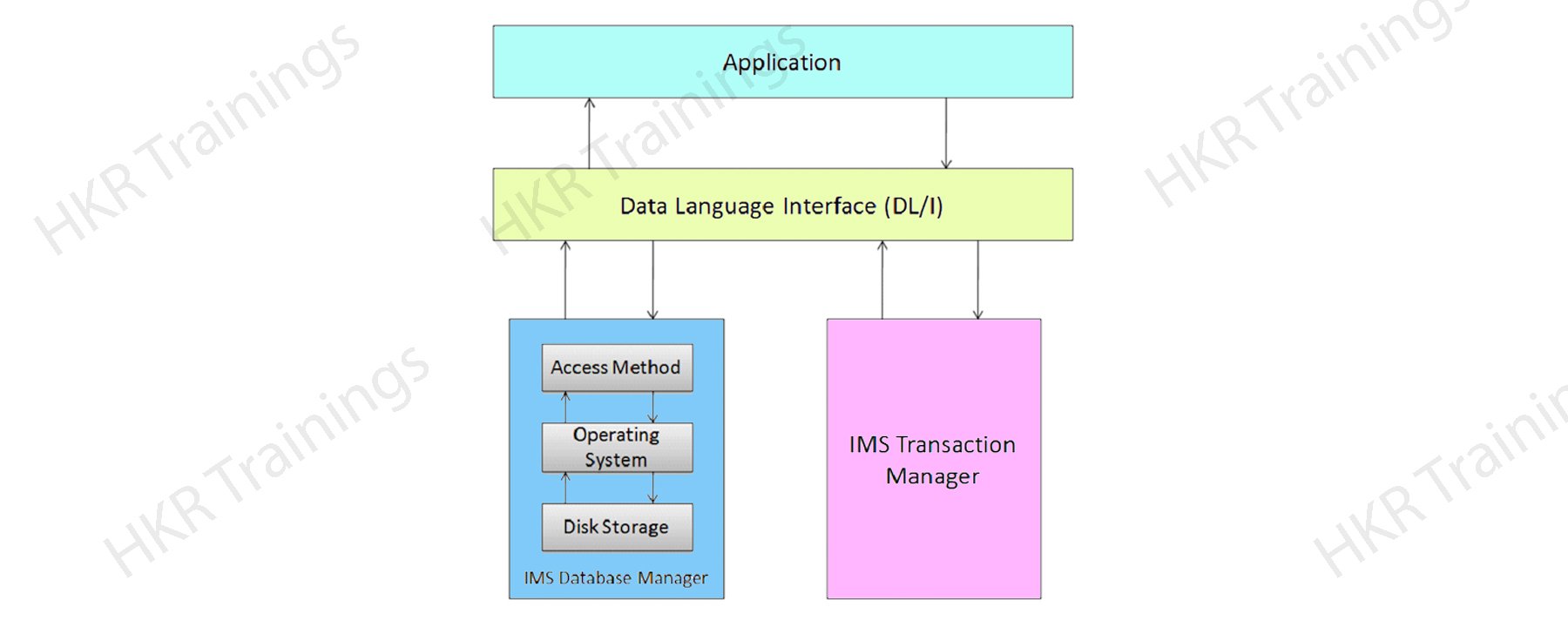
Database management:
A database management system is a collection of application programs mainly used for data storage, accessing, and managing your data sets in the database. One of the main advantages of the IMS system is to maintain the data integrity, allow you to faster data recovery, and make it easy to retrieve data. IMS tool maintains a large amount of data with the help of its database management system.

Subscribe to our YouTube channel to get new updates..!
Transaction manager:
The main function of the transaction manager is to offer a better communication platform between the database system and the application programs. Sometimes IMS acts as a transaction manager. A transaction manager deals with various end-users to store data and retrieve of data from the multiple database management systems.
DL/I –Data language interface:
DL/I comprises several application programs and grants access to the data stored in the database. IMS database uses the DL/I this serves as an interface language and accesses the database in an application program.
Importance of IMS:
1. IMS database system supports applications from different programming languages such as JAVA and XML.
2. IMS database system offers better application management and data can be accessed over any platform.
3. IMS database system offers faster data processing when it is compared to other DB2 systems.
Limitations of IMS:
1. IMS database implementation is very complex when compared to other database systems.
2. IMS helps to predefine the tree structures that reduce flexibility.
3. IMS database system sometimes it’s difficult to manage.
Hierarchical structure:
An IMS database system is a collection of data physical files. In the hierarchical database system, the topmost level data information entity. Each level in the hierarchy consists of segments, standard files, and difficult to implement hierarchies but sometimes DL/I support hierarchies. The following diagram explains the hierarchical structure type:

Segments:
A segment is created by grouping similar data types. This is the smallest unit of information that DL/I transfers to and from an application program during the time of input and output operations. A segment can have one or more data fields that are grouped together.
Field:
A filed is a single piece of information in a segment. For example, roll number, course, name, and mobile number in the student segment. A segment consists of related data fields to collect the appropriate entity information. A field can be used as a key for ordering any segment types.
Segment type:
A segment type is a category of the data segment. A DL/I database consists of 255 different segment types and 15 levels of the hierarchy. The following is an example of a Segment type:
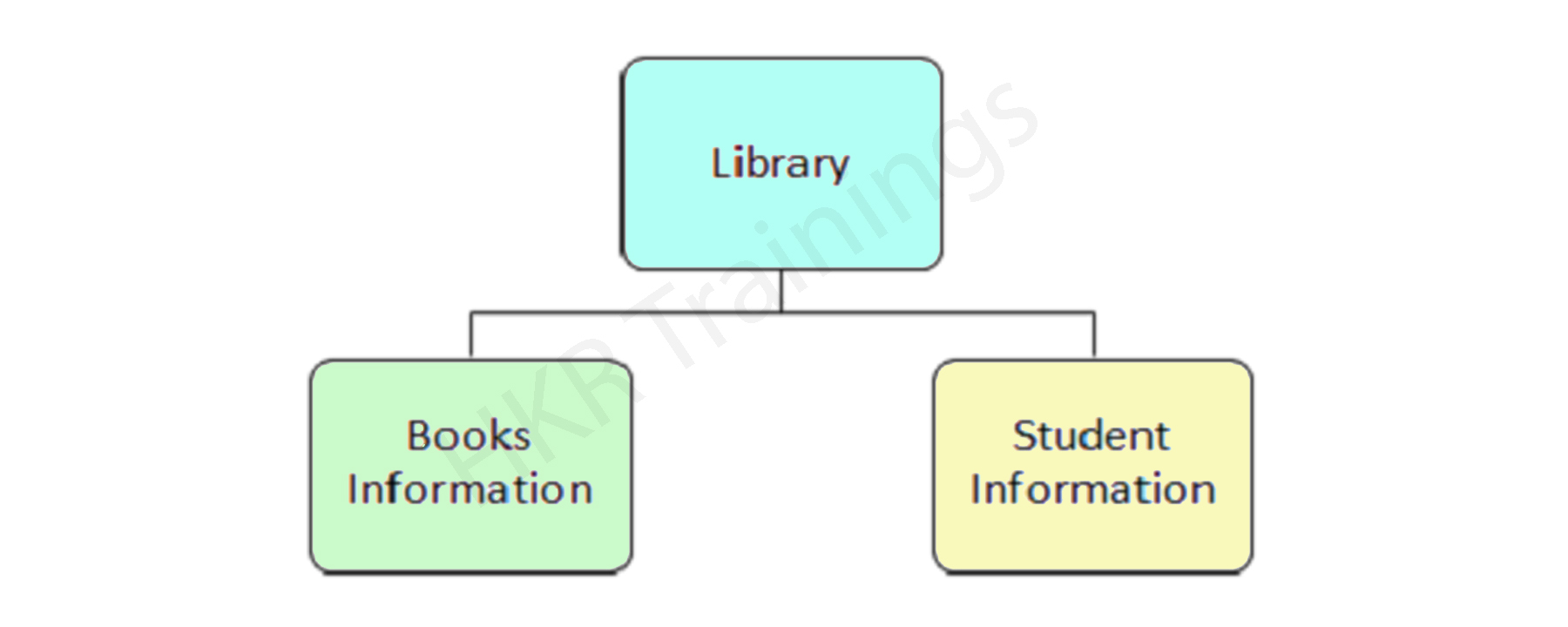
Segment occurrence:
A segment occurrence is an individual segment type and this consists of only user data. For example, when you take book information as a segment type and you can see any number of occurrences of it. This type of segment contains any number of book information.
JCL tool:
JCL stands for job control language is the command language of multiple virtual storages (MVS), which is commonly used in various operating systems in the IBM mainframes. JCL helps to identify the program to be executed, required input, and location of the input or output identification with the help of job control statements. JCL is mainly used for submitting any program type for the batch mode execution.
Overview of JCL:
JCL is used in a mainframe environment and acts as a communication between a program and an operating system. For example COBOL language, PL/I, and Assembler. In the mainframe environment programs will be executed in the form of batch and online modes. Here Virtual storage access method can be used as a batch system program. Online program mode can be of type back office screen and accounting details.
Job processing:
A job is nothing but a unit of work that is made up of many job processing steps. Each job processing step is specified in a job control language (JCL) using a set of job control statements.
In the mainframe, the operating system makes use of Job entry systems or JES to accept the jobs, transfer that into the operating system, to schedule various jobs type for processing, and to control the output.
The below diagram will illustrate the job processing step:
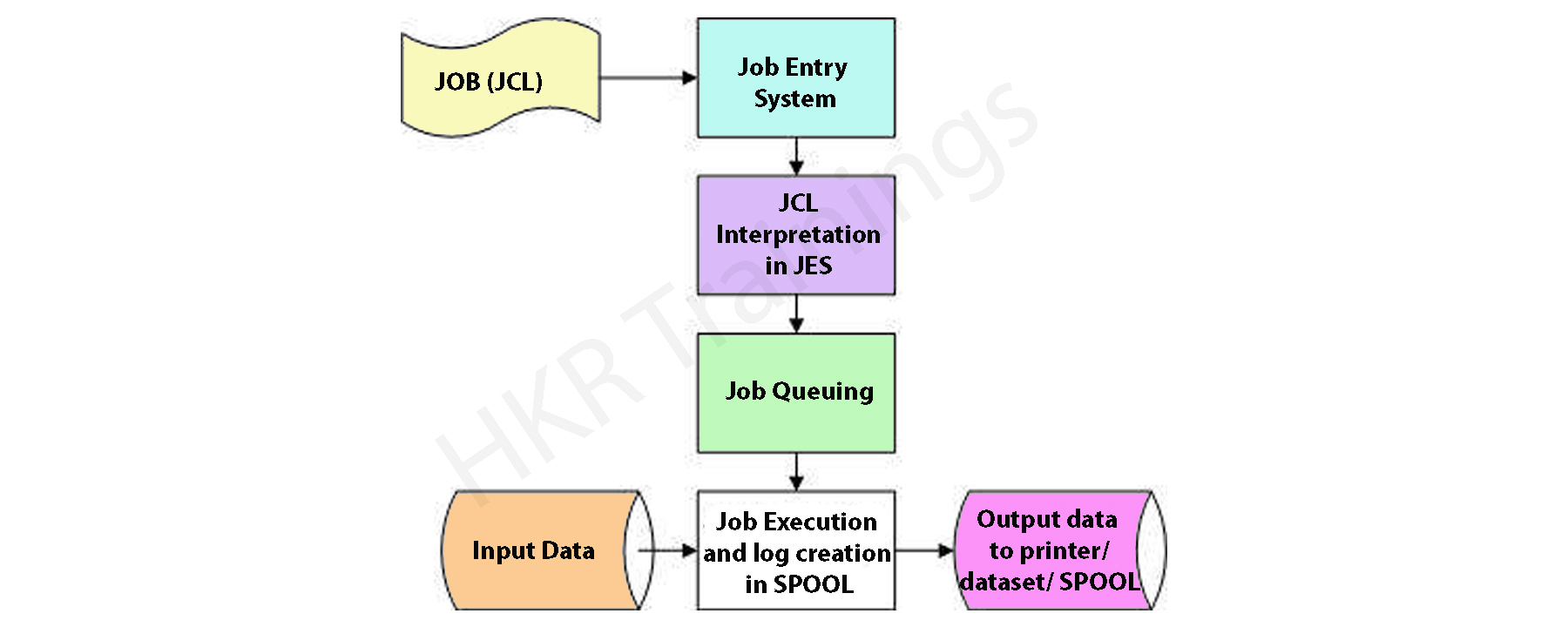
Job submission step: this step is used for submitting the job control language or JCL to JES (Job entry system).
Job conversion: The JCL along with the PROC process will be converted into an interpreted text which is to be understood by JES and helps to store the data sets, which is known as SPOOL.
Job queuing: JES decides the priority based on CLASS and PRTY parameters in the JOB control statements. The errors will be checked in this step with the help of job queuing.
Job execution: Once the job reaches the highest priority, it is taken up for execution from the job queue.
Purging: once the job is completed, the allocated resources and the JES SPOOL spaces are released. In order to store any job log file, you need to copy this job log file to another dataset.
VSAM tool:
A VSAM stands for virtual storage Access method and this is also known as file storage access method used in many technologies like MVS, ZOS, and OS/390 operating system. This also acts as a high-performance access method used to organize the various data in the form of files in mainframe devices. VSAM tool is used by COBOL and CICS to store and retrieve the various data sets. VSAM makes it easier for any application program to execute any output or input operation.
Overview of VSAM:
Virtual storage access method (VSAM) is a high-performance access method and organizes the data sets. This mainframe tool utilizes the various virtual concepts and also protects the data sets at different levels by using passwords. In COBOL, this VSAM can be used as a physical sequential file. VSAM is the logical dataset for storing data records.
Characteristics of VSAM:
Below are the various characteristics of VSAM:
1. VSAM helps to protect the data against any unauthorized access by using passwords.
2. VSAM offers faster data access methods.
3. VSAM provides various options for optimizing the performance.
4. VSAM allows data set sharing in both online and batch mode environment.
5. VSAM’s data sets are more structured and organized in data storage.
6. Free up space is reused automatically in various VSAM data files.
Limitations of VSAM:
1. VSAM data sets cannot be stored on TAPE volume. This is only stored on DASD space.
2. VSAM requires a number of cylinders to store the various data sets and not cost-effective.
VSAM components:
There are three main components of VSAM:
1. VSAM cluster:
VSAM clusters are nothing but logical data sets for storing the various data records. A cluster comprises of index association, sequence data set, and data portions. The space occupied by the VSAM cluster will be divided into contiguous areas known as control intervals.
There are two sub-components used in a VSAM cluster:
a. Index components
b. Data component.
2. Control intervals:
The control intervals (CI) in VSAM are equivalent to blocks and used for non-VSAM data sets. In non-VSAM methods, the data set unit is defined by various blocks. VSAM works well only with logical data sets are known as control intervals. Control intervals are the smallest unit used to transfer data between a disk and the operating systems.
The control interval consists of sub-components:
a. Logical records
b. Control information fields
c. Free space
3. Control Area:
A control area in VSAM is the formation of two or more control intervals. Any VSAM dataset is composed of one or more control areas. The actual size of VSAM is a multiple of the control area. All VSAM files are extended in units of Control areas.
Conclusion :
In this Mainframe tutorial, you will be learning major mainframe technologies like CICS, COBOL, DB2, IMS DB, JCL, and VSAM. These technologies offer different features and functionalities. We have tried to explain all in one article, and kind of ready book. I hope this tutorial may help a few of you who want to begin your mainframe profession as well as working professionals.
About Author
Upcoming Mainframes Training Certification Online classes
| Batch starts on 22nd Jul 2026 |
|
||
| Batch starts on 26th Jul 2026 |
|
||
| Batch starts on 30th Jul 2026 |
|